Alguns dos comandos da CLI do Azure neste artigo usam a extensão , ou v1, para o azure-cli-mlAzure Machine Learning. O suporte para a extensão v1 terminará em 30 de setembro de 2025. Você poderá instalar e usar a extensão v1 até essa data.
Recomendamos que você faça a transição para a mlextensão , ou v2, antes de 30 de setembro de 2025. Para obter mais informações sobre a extensão v2, consulte Extensão CLI do Azure ML e Python SDK v2.
Neste artigo, você aprenderá a usar o Open Neural Network Exchange (ONNX) para fazer previsões em modelos de visão computacional gerados a partir do aprendizado de máquina automatizado (AutoML) no Azure Machine Learning.
Para usar o ONNX para previsões, você precisa:
Baixe arquivos de modelo ONNX de uma execução de treinamento AutoML.
Compreender as entradas e saídas de um modelo ONNX.
Pré-processe seus dados para que estejam no formato necessário para imagens de entrada.
Execute inferência com o ONNX Runtime for Python.
Visualize previsões para tarefas de deteção de objetos e segmentação de instâncias.
O ONNX é um padrão aberto para modelos de aprendizado de máquina e aprendizado profundo. Ele permite a importação e exportação de modelos (interoperabilidade) entre as estruturas de IA populares. Para obter mais detalhes, explore o projeto ONNX GitHub.
ONNX Runtime é um projeto de código aberto que suporta inferência entre plataformas. O ONNX Runtime fornece APIs em linguagens de programação (incluindo Python, C++, C#, C, Java e JavaScript). Você pode usar essas APIs para executar inferência em imagens de entrada. Depois de ter o modelo que foi exportado para o formato ONNX, você pode usar essas APIs em qualquer linguagem de programação que seu projeto precisa.
Neste guia, você aprenderá a usar APIs Python para ONNX Runtime para fazer previsões em imagens para tarefas de visão populares. Você pode usar esses modelos exportados ONNX entre idiomas.
Pré-requisitos
Obtenha um modelo de visão computacional treinado pelo AutoML para qualquer uma das tarefas de imagem suportadas: classificação, deteção de objetos ou segmentação de instância. Saiba mais sobre o suporte AutoML para tarefas de visão computacional.
Instale o pacote onnxruntime . Os métodos neste artigo foram testados com as versões 1.3.0 a 1.8.0.
Baixar arquivos de modelo ONNX
Você pode baixar arquivos de modelo ONNX de execuções do AutoML usando a interface do usuário do estúdio Azure Machine Learning ou o SDK Python do Azure Machine Learning. Recomendamos o download através do SDK com o nome do experimento e o ID de execução pai.
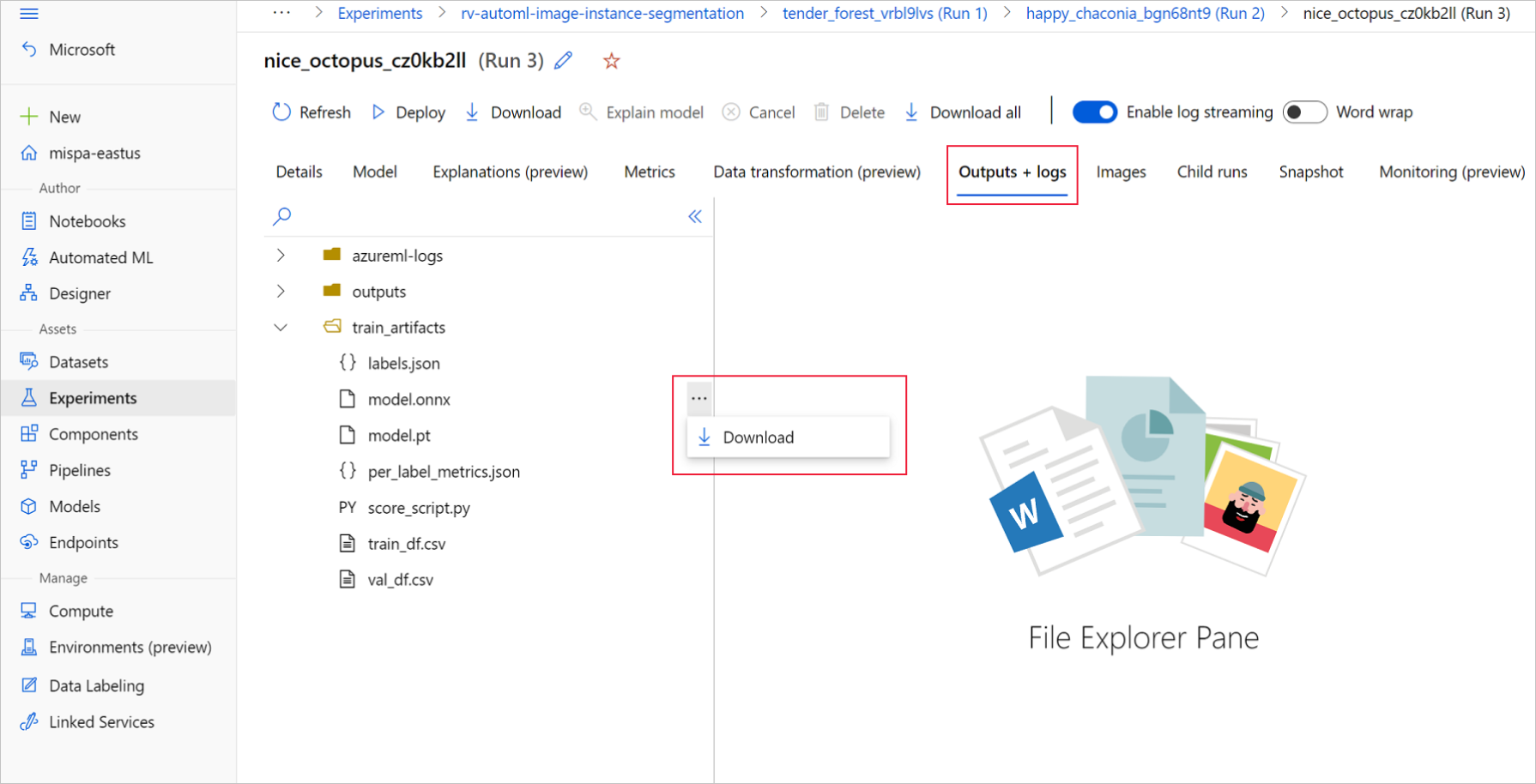
Azure Machine Learning Studio
No estúdio de Aprendizado de Máquina do Azure, vá para seu experimento usando o hiperlink para o experimento gerado no bloco de anotações de treinamento ou selecionando o nome do experimento na guia Experimentos em Ativos. Em seguida, selecione a melhor corrida filho.
Dentro da melhor execução filho, vá para Saídas+logs>train_artifacts. Use o botão Download para baixar manualmente os seguintes arquivos:
labels.json: Arquivo que contém todas as classes ou rótulos no conjunto de dados de treinamento.
model.onnx: Modelo em formato ONNX.
Salve os arquivos de modelo baixados em um diretório. O exemplo neste artigo usa o diretório ./automl_models .
SDK do Python do Azure Machine Learning
Com o SDK, você pode selecionar a melhor execução filho (por métrica primária) com o nome do experimento e o ID de execução pai. Em seguida, você pode baixar os arquivos labels.json e model.onnx .
O código a seguir retorna a melhor execução filho com base na métrica primária relevante.
from azureml.train.automl.run import AutoMLRun
# Select the best child run
run_id = '' # Specify the run ID
automl_image_run = AutoMLRun(experiment=experiment, run_id=run_id)
best_child_run = automl_image_run.get_best_child()
Baixe o arquivo labels.json , que contém todas as classes e rótulos no conjunto de dados de treinamento.
Por padrão, o AutoML for Images oferece suporte à pontuação em lote para classificação. Mas os modelos de deteção de objetos e segmentação de instâncias não suportam inferência em lote. No caso de inferência em lote para deteção de objetos e segmentação de instâncias, use o procedimento a seguir para gerar um modelo ONNX para o tamanho de lote necessário. Os modelos gerados para um tamanho de lote específico não funcionam para outros tamanhos de lote.
from azureml.core.script_run_config import ScriptRunConfig
from azureml.train.automl.run import AutoMLRun
from azureml.core.workspace import Workspace
from azureml.core import Experiment
# specify experiment name
experiment_name = ''
# specify workspace parameters
subscription_id = ''
resource_group = ''
workspace_name = ''
# load the workspace and compute target
ws = ''
compute_target = ''
experiment = Experiment(ws, name=experiment_name)
# specify the run id of the automl run
run_id = ''
automl_image_run = AutoMLRun(experiment=experiment, run_id=run_id)
best_child_run = automl_image_run.get_best_child()
Para obter os valores de argumento necessários para criar o modelo de pontuação em lote, consulte os scripts de pontuação gerados na pasta de saídas das execuções de treinamento do AutoML. Use os valores de hiperparâmetro disponíveis na variável de configurações do modelo dentro do arquivo de pontuação para a melhor execução filho.
Para classificação de imagem de várias classes, o modelo ONNX gerado para a melhor execução infantil suporta pontuação em lote por padrão. Portanto, nenhum argumento específico do modelo é necessário para esse tipo de tarefa e você pode pular para a seção Carregar os rótulos e arquivos de modelo ONNX.
Para classificação de imagem com vários rótulos, o modelo ONNX gerado para a melhor execução infantil suporta pontuação em lote por padrão. Portanto, nenhum argumento específico do modelo é necessário para esse tipo de tarefa e você pode pular para a seção Carregar os rótulos e arquivos de modelo ONNX.
arguments = ['--model_name', 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 600, # enter the height of input to ONNX model
'--width_onnx', 800, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-object-detection',
'--min_size', 600, # minimum size of the image to be rescaled before feeding it to the backbone
'--max_size', 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'--box_score_thresh', 0.3, # threshold to return proposals with a classification score > box_score_thresh
'--box_nms_thresh', 0.5, # NMS threshold for the prediction head
'--box_detections_per_img', 100 # maximum number of detections per image, for all classes
]
arguments = ['--model_name', 'yolov5', # enter the yolo model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 640, # enter the height of input to ONNX model
'--width_onnx', 640, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-object-detection',
'--img_size', 640, # image size for inference
'--model_size', 'medium', # size of the yolo model
'--box_score_thresh', 0.1, # threshold to return proposals with a classification score > box_score_thresh
'--box_iou_thresh', 0.5 # IOU threshold used during inference in nms post processing
]
arguments = ['--model_name', 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 600, # enter the height of input to ONNX model
'--width_onnx', 800, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-instance-segmentation',
'--min_size', 600, # minimum size of the image to be rescaled before feeding it to the backbone
'--max_size', 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'--box_score_thresh', 0.3, # threshold to return proposals with a classification score > box_score_thresh
'--box_nms_thresh', 0.5, # NMS threshold for the prediction head
'--box_detections_per_img', 100 # maximum number of detections per image, for all classes
]
Baixe e mantenha o ONNX_batch_model_generator_automl_for_images.py arquivo no diretório atual e envie o script. Use ScriptRunConfig para enviar o script ONNX_batch_model_generator_automl_for_images.py disponível no repositório GitHub azureml-examples, para gerar um modelo ONNX de um tamanho de lote específico. No código a seguir, o ambiente de modelo treinado é usado para enviar esse script para gerar e salvar o modelo ONNX no diretório de saídas.
Uma vez que o modelo de lote é gerado, baixe-o de saídas Outputs+logs>manualmente ou use o seguinte método:
batch_size= 8 # use the batch size used to generate the model
onnx_model_path = 'automl_models/model.onnx' # local path to save the model
remote_run.download_file(name='outputs/model_'+str(batch_size)+'.onnx', output_file_path=onnx_model_path)
Após a etapa de download do modelo, use o pacote Python do ONNX Runtime para executar a inferência usando o arquivo model.onnx . Para fins de demonstração, este artigo usa os conjuntos de dados de Como preparar conjuntos de dados de imagem para cada tarefa de visão.
Treinamos os modelos para todas as tarefas de visão com seus respetivos conjuntos de dados para demonstrar a inferência do modelo ONNX.
Carregue as etiquetas e os arquivos de modelo ONNX
O trecho de código a seguir carrega labels.json, onde os nomes de classe são ordenados. Ou seja, se o modelo ONNX prevê um ID de rótulo como 2, então ele corresponde ao nome do rótulo dado no terceiro índice no arquivo labels.json .
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ",str(e))
Obter detalhes de entrada e saída esperados para um modelo ONNX
Quando você tem o modelo, é importante saber alguns detalhes específicos do modelo e da tarefa. Esses detalhes incluem o número de entradas e o número de saídas, a forma ou o formato de entrada esperado para pré-processamento da imagem e a forma de saída para que você conheça as saídas específicas do modelo ou da tarefa.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Formatos de entrada e saída esperados para o modelo ONNX
Cada modelo ONNX tem um conjunto predefinido de formatos de entrada e saída.
A entrada é uma imagem pré-processada, com a forma (1, 3, 224, 224) para um tamanho de lote de 1 e uma altura e largura de 224. Estes números correspondem aos valores utilizados no crop_size exemplo de treino.
Formato de saída
A saída é uma matriz de logits para todas as classes/rótulos.
Nome da saída
Forma de saída
Tipo de saída
Description
saída1
(batch_size, num_classes)
ndarray(float)
Modelo retorna logits (sem softmax). Por exemplo, para classes de tamanho de lote 1 e 4, ele retorna (1, 4).
A entrada é uma imagem pré-processada, com a forma (1, 3, 224, 224) para um tamanho de lote de 1 e uma altura e largura de 224. Estes números correspondem aos valores utilizados no crop_size exemplo de treino.
Formato de saída
A saída é uma matriz de logits para todas as classes/rótulos.
Nome da saída
Forma de saída
Tipo de saída
Description
saída1
(batch_size, num_classes)
ndarray(float)
Modelo retorna logits (sem sigmoid). Por exemplo, para classes de tamanho de lote 1 e 4, ele retorna (1, 4).
A entrada é uma imagem pré-processada, com a forma (1, 3, 600, 800) para um tamanho de lote de 1, e uma altura de 600 e largura de 800.
Formato de saída
A saída é uma tupla de output_names e previsões. Aqui, output_names e predictions são listas com comprimento 3*batch_size cada. Para Faster R-CNN ordem de saídas são caixas, rótulos e pontuações, enquanto para RetinaNet saídas são caixas, pontuações, rótulos.
Nome da saída
Forma de saída
Tipo de saída
Description
output_names
(3*batch_size)
Lista de chaves
Para um tamanho de lote de 2, output_names será ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Lista de ndarray(float)
Para um tamanho de lote de 2, predictions terá a forma de [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Aqui, os valores em cada índice correspondem ao mesmo índice em output_names.
A tabela a seguir descreve caixas, rótulos e pontuações retornados para cada amostra no lote de imagens.
Nome
Forma
Tipo
Description
Caixas
(n_boxes, 4), em que cada caixa tem x_min, y_min, x_max, y_max
ndarray(float)
Modelo retorna n caixas com suas coordenadas superior esquerda e inferior direita.
Etiquetas
(n_boxes)
ndarray(float)
Rótulo ou ID de classe de um objeto em cada caixa.
Pontuações
(n_boxes)
ndarray(float)
Pontuação de confiança de um objeto em cada caixa.
A entrada é uma imagem pré-processada, com a forma (1, 3, 640, 640) para um tamanho de lote de 1 e uma altura e largura de 640. Estes números correspondem aos valores utilizados no exemplo de formação.
Nome de entrada
Forma de entrada
Input type
Description
Entrada
(batch_size, num_channels, height, width)
ndarray(float)
A entrada é uma imagem pré-processada, com a forma (1, 3, 640, 640) para um tamanho de lote de 1, e uma altura de 640 e largura de 640.
Formato de saída
As previsões do modelo ONNX contêm várias saídas. A primeira saída é necessária para executar a supressão não-máxima para deteções. Para facilitar o uso, o ML automatizado exibe o formato de saída após a etapa de pós-processamento NMS. A saída após NMS é uma lista de caixas, rótulos e pontuações para cada amostra no lote.
Nome da saída
Forma de saída
Tipo de saída
Description
Saída
(batch_size)
Lista de ndarray(float)
Modelo retorna deteções de caixa para cada amostra no lote
Cada célula na lista indica deteções de caixa de uma amostra com forma (n_boxes, 6), onde cada caixa tem x_min, y_min, x_max, y_max, confidence_score, class_id.
Apenas o Mask R-CNN é suportado para tarefas de segmentação por exemplo. Os formatos de entrada e saída são baseados apenas no Mask R-CNN.
Formato de entrada
A entrada é uma imagem pré-processada. O modelo ONNX para Mask R-CNN foi exportado para trabalhar com imagens de diferentes formas. Recomendamos que você os redimensione para um tamanho fixo que seja consistente com os tamanhos de imagem de treinamento, para um melhor desempenho.
Nome de entrada
Forma de entrada
Input type
Description
Entrada
(batch_size, num_channels, height, width)
ndarray(float)
A entrada é uma imagem pré-processada, com forma (1, 3, input_image_height, input_image_width) para um tamanho de lote de 1 e uma altura e largura semelhantes a uma imagem de entrada.
Formato de saída
A saída é uma tupla de output_names e previsões. Aqui, output_names e predictions são listas com comprimento 4*batch_size cada.
Nome da saída
Forma de saída
Tipo de saída
Description
output_names
(4*batch_size)
Lista de chaves
Para um tamanho de lote de 2, output_names será ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Lista de ndarray(float)
Para um tamanho de lote de 2, predictions terá a forma de [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Aqui, os valores em cada índice correspondem ao mesmo índice em output_names.
Nome
Forma
Tipo
Description
Caixas
(n_boxes, 4), em que cada caixa tem x_min, y_min, x_max, y_max
ndarray(float)
Modelo retorna n caixas com suas coordenadas superior esquerda e inferior direita.
Etiquetas
(n_boxes)
ndarray(float)
Rótulo ou ID de classe de um objeto em cada caixa.
Pontuações
(n_boxes)
ndarray(float)
Pontuação de confiança de um objeto em cada caixa.
Máscaras faciais
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Máscaras (polígonos) de objetos detetados com a forma, altura e largura de uma imagem de entrada.
Execute as seguintes etapas de pré-processamento para a inferência do modelo ONNX:
Converta a imagem em RGB.
Redimensione a imagem para valid_resize_size e valid_resize_size os valores que correspondem aos valores usados na transformação do conjunto de dados de validação durante o treinamento. O valor padrão para valid_resize_size é 256.
Centro cortar a imagem para height_onnx_crop_size e width_onnx_crop_size. Corresponde ao valid_crop_size valor padrão de 224.
Altere HxWxC para CxHxW.
Converter para o tipo float.
Normalize com ImageNet mean = [0.485, 0.456, 0.406] e .std = [0.229, 0.224, 0.225]
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Com PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Execute as seguintes etapas de pré-processamento para a inferência do modelo ONNX. Essas etapas são as mesmas para a classificação de imagem de várias classes.
Converta a imagem em RGB.
Redimensione a imagem para valid_resize_size e valid_resize_size os valores que correspondem aos valores usados na transformação do conjunto de dados de validação durante o treinamento. O valor padrão para valid_resize_size é 256.
Centro cortar a imagem para height_onnx_crop_size e width_onnx_crop_size. Isso corresponde ao valid_crop_size valor padrão de 224.
Altere HxWxC para CxHxW.
Converter para o tipo float.
Normalize com ImageNet mean = [0.485, 0.456, 0.406] e .std = [0.229, 0.224, 0.225]
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Com PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Para a deteção de objetos com o algoritmo Faster R-CNN, siga os mesmos passos de pré-processamento que a classificação de imagens, exceto para o corte de imagens. Você pode redimensionar a imagem com altura 600 e largura 800. Você pode obter a altura e a largura de entrada esperadas com o código a seguir.
Em seguida, execute as etapas de pré-processamento.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Para deteção de objetos com o algoritmo YOLO, siga as mesmas etapas de pré-processamento da classificação de imagem, exceto para corte de imagem. Você pode redimensionar a imagem com altura 600 e largura 800e obter a altura e largura de entrada esperadas com o código a seguir.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Importante
Apenas o Mask R-CNN é suportado para tarefas de segmentação por exemplo. As etapas de pré-processamento são baseadas apenas no Mask R-CNN.
Execute as seguintes etapas de pré-processamento para a inferência do modelo ONNX:
Converta a imagem em RGB.
Redimensione a imagem.
Altere HxWxC para CxHxW.
Converter para o tipo float.
Normalize com ImageNet mean = [0.485, 0.456, 0.406] e .std = [0.229, 0.224, 0.225]
Para resize_height e resize_width, você também pode usar os valores que você usou durante o min_size treinamento, limitados pelos hiperparâmetros e max_sizepara Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Inferência com ONNX Runtime
A inferência com o ONNX Runtime difere para cada tarefa de visão computacional.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
O modelo de segmentação de instância prevê caixas, rótulos, pontuações e máscaras. O ONNX gera uma máscara prevista por instância, juntamente com as caixas delimitadoras correspondentes e a pontuação de confiança da classe. Talvez seja necessário converter de máscara binária para polígono, se necessário.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Aplique softmax() acima dos valores previstos para obter pontuações de confiança de classificação (probabilidades) para cada classe. Então a previsão será a classe com maior probabilidade.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Esta etapa difere da classificação multiclasse. Você precisa aplicar sigmoid aos logits (saída ONNX) para obter pontuações de confiança para classificação de imagem multi-label.
Sem PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Com PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Para classificação multiclasse e multirótulo, você pode seguir as mesmas etapas mencionadas anteriormente para todos os algoritmos suportados no AutoML.
Para deteção de objetos, as previsões são automaticamente na escala de height_onnx, width_onnx. Para transformar as coordenadas de caixa previstas para as dimensões originais, você pode implementar os seguintes cálculos.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Outra opção é usar o código a seguir para dimensionar as dimensões da caixa para estar no intervalo de [0, 1]. Isso permite que as coordenadas da caixa sejam multiplicadas com a altura e largura das imagens originais com as respetivas coordenadas (conforme descrito na seção de previsões de visualização) para obter caixas nas dimensões originais da imagem.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
O código a seguir cria caixas, rótulos e pontuações. Utilize estes detalhes da caixa delimitadora para executar os mesmos passos de pós-processamento que fez para o modelo R-CNN mais rápido.
Você pode usar as etapas mencionadas para Faster R-CNN (no caso de Mask R-CNN, cada amostra tem quatro caixas de elementos, rótulos, pontuações, máscaras) ou consultar a seção visualizar previsões para segmentação por exemplo.
 Python SDK azureml v1
Python SDK azureml v1