Tutorial: Carregue, aceda e explore os seus dados no Azure Machine Learning
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
Neste tutorial, ficará a saber como:
- Carregue os seus dados para o armazenamento na nuvem
- Criar um ativo de dados do Azure Machine Learning
- Aceda aos seus dados num bloco de notas para desenvolvimento interativo
- Criar novas versões de ativos de dados
Um projeto de aprendizado de máquina normalmente começa com análise exploratória de dados (EDA), pré-processamento de dados (limpeza, engenharia de recursos) e construção de protótipos de modelo de aprendizado de máquina para validar hipóteses. Esta fase do projeto de prototipagem é altamente interativa. Ele se presta ao desenvolvimento em um IDE ou um notebook Jupyter, com um console interativo Python. Este tutorial descreve essas ideias.
Este vídeo mostra como começar no estúdio do Azure Machine Learning, para que você possa seguir as etapas no tutorial. O vídeo mostra como criar um bloco de anotações, clonar o bloco de anotações, criar uma instância de computação e baixar os dados necessários para o tutorial. As etapas também são descritas nas seções a seguir.
Pré-requisitos
-
Para usar o Azure Machine Learning, você precisa de um espaço de trabalho. Se você não tiver um, conclua Criar recursos necessários para começar a criar um espaço de trabalho e saiba mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez seja necessário adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes Python. Para obter mais informações, consulte Cenário: acessar pacotes públicos de aprendizado de máquina.
-
Entre no estúdio e selecione seu espaço de trabalho se ele ainda não estiver aberto.
-
Abra ou crie um bloco de notas na sua área de trabalho:
- Se quiser copiar e colar código em células, crie um novo bloco de anotações.
- Ou abra tutoriais/get-started-notebooks/explore-data.ipynb na seção Amostras do estúdio. Em seguida, selecione Clonar para adicionar o bloco de anotações aos seus arquivos. Para localizar blocos de notas de exemplo, consulte Aprender com blocos de notas de exemplo.
Defina seu kernel e abra no Visual Studio Code (VS Code)
Na barra superior acima do bloco de anotações aberto, crie uma instância de computação se ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Aguarde até que a instância de computação esteja em execução. Em seguida, certifique-se de que o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar este kernel.
Se você não vir esse kernel, verifique se sua instância de computação está em execução. Se estiver, selecione o botão Atualizar no canto superior direito do bloco de anotações.
Se você vir um banner dizendo que precisa ser autenticado, selecione Autenticar.
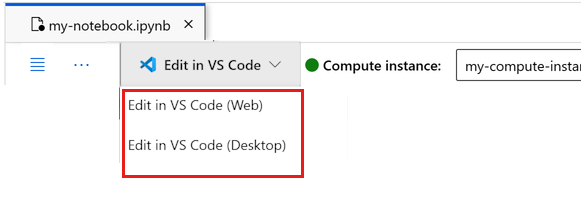
Você pode executar o bloco de anotações aqui ou abri-lo no VS Code para um ambiente de desenvolvimento integrado (IDE) completo com o poder dos recursos do Azure Machine Learning. Selecione Abrir no VS Code e, em seguida, selecione a opção Web ou desktop. Quando iniciado dessa forma, o VS Code é anexado à sua instância de computação, ao kernel e ao sistema de arquivos do espaço de trabalho.




Importante
O restante deste tutorial contém células do bloco de anotações do tutorial. Copie-os e cole-os no seu novo bloco de notas ou mude para o bloco de notas agora se o tiver clonado.
Faça o download dos dados usados neste tutorial
Para ingestão de dados, o Azure Data Explorer manipula dados brutos nesses formatos. Este tutorial usa este exemplo de dados de cliente de cartão de crédito em formato CSV. As etapas prosseguem em um recurso do Azure Machine Learning. Nesse recurso, criaremos uma pasta local, com o nome sugerido dos dados, diretamente sob a pasta onde este bloco de anotações está localizado.
Nota
Este tutorial depende dos dados colocados em um local de pasta de recursos do Azure Machine Learning. Para este tutorial, 'local' significa um local de pasta nesse recurso do Azure Machine Learning.
Selecione Abrir terminal abaixo dos três pontos, como mostra esta imagem:
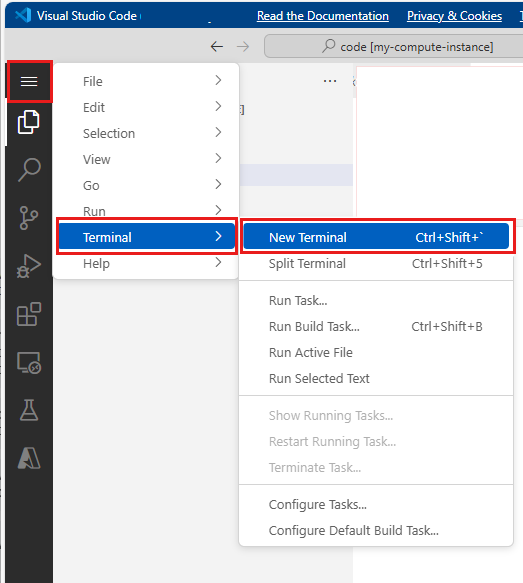
A janela do terminal é aberta num novo separador.
Certifique-se de
cdque (Alterar diretório) está localizado na mesma pasta onde este bloco de notas está localizado. Por exemplo, se o bloco de anotações estiver em uma pasta chamada get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedInsira estes comandos na janela do terminal para copiar os dados para sua instância de computação:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvAgora você pode fechar a janela do terminal.
Para obter mais informações sobre os dados no UC Irvine Machine Learning Repository, visite este recurso.
Criar um identificador para o espaço de trabalho
Antes de explorarmos o código, você precisa de uma maneira de fazer referência ao seu espaço de trabalho. Você criará ml_client um identificador para o espaço de trabalho. Em seguida, você usa ml_client para gerenciar recursos e trabalhos.
Na célula seguinte, introduza o ID da Subscrição, o nome do Grupo de Recursos e o nome da Área de Trabalho. Para encontrar estes valores:
- No canto superior direito da barra de ferramentas do estúdio do Azure Machine Learning, selecione o nome do seu espaço de trabalho.
- Copie o valor para espaço de trabalho, grupo de recursos e ID de assinatura para o código.
- Você deve copiar individualmente os valores um de cada vez, fechar a área e colar, em seguida, continuar para o próximo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Nota
A criação do MLClient não se conectará ao espaço de trabalho. A inicialização do cliente é preguiçosa. Espera pela primeira vez que precisa de fazer uma chamada. Isso acontece na próxima célula de código.
Carregar dados para o armazenamento na nuvem
O Azure Machine Learning usa URIs (Uniform Resource Identifiers), que apontam para locais de armazenamento na nuvem. Um URI facilita o acesso a dados em blocos de anotações e trabalhos. Os formatos de URI de dados têm um formato semelhante aos URLs da Web que você usa no navegador da Web para acessar páginas da Web. Por exemplo:
- Acesse dados do servidor https público:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Acessar dados do Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Um ativo de dados do Azure Machine Learning é semelhante aos marcadores do navegador da Web (favoritos). Em vez de lembrar os URIs (caminhos de armazenamento longos) que apontam para os dados usados com mais frequência, você pode criar um ativo de dados e, em seguida, acessar esse ativo com um nome amigável.
A criação de ativos de dados também cria uma referência ao local da fonte de dados, juntamente com uma cópia de seus metadados. Como os dados permanecem em seu local existente, você não incorre em nenhum custo adicional de armazenamento e não corre em risco a integridade da fonte de dados. Você pode criar ativos de dados a partir de armazenamentos de dados do Azure Machine Learning, Armazenamento do Azure, URLs públicas e arquivos locais.
Gorjeta
Para carregamentos de dados de tamanho menor, a criação de ativos de dados do Aprendizado de Máquina do Azure funciona bem para carregamentos de dados de recursos de máquina local para armazenamento em nuvem. Essa abordagem evita a necessidade de ferramentas ou utilitários extras. No entanto, um carregamento de dados de tamanho maior pode exigir uma ferramenta ou utilitário dedicado - por exemplo, azcopy. A ferramenta de linha de comando azcopy move dados de e para o Armazenamento do Azure. Para obter mais informações sobre azcopy, visite este recurso.
A próxima célula do bloco de anotações cria o ativo de dados. O exemplo de código carrega o arquivo de dados brutos para o recurso de armazenamento em nuvem designado.
Cada vez que você cria um ativo de dados, você precisa de uma versão exclusiva para ele. Se a versão já existir, você receberá um erro. Neste código, usamos a "inicial" para a primeira leitura dos dados. Se essa versão já existe, não a recriamos.
Você também pode omitir o parâmetro version . Nesse caso, um número de versão é gerado para você, começando com 1 e depois incrementando a partir daí.
Este tutorial usa o nome "inicial" como a primeira versão. O tutorial Criar pipelines de aprendizado de máquina de produção também usa essa versão dos dados, portanto, aqui usamos um valor que você verá novamente nesse tutorial.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Para examinar os dados carregados, selecione Dados à esquerda. Os dados são carregados e um ativo de dados é criado:
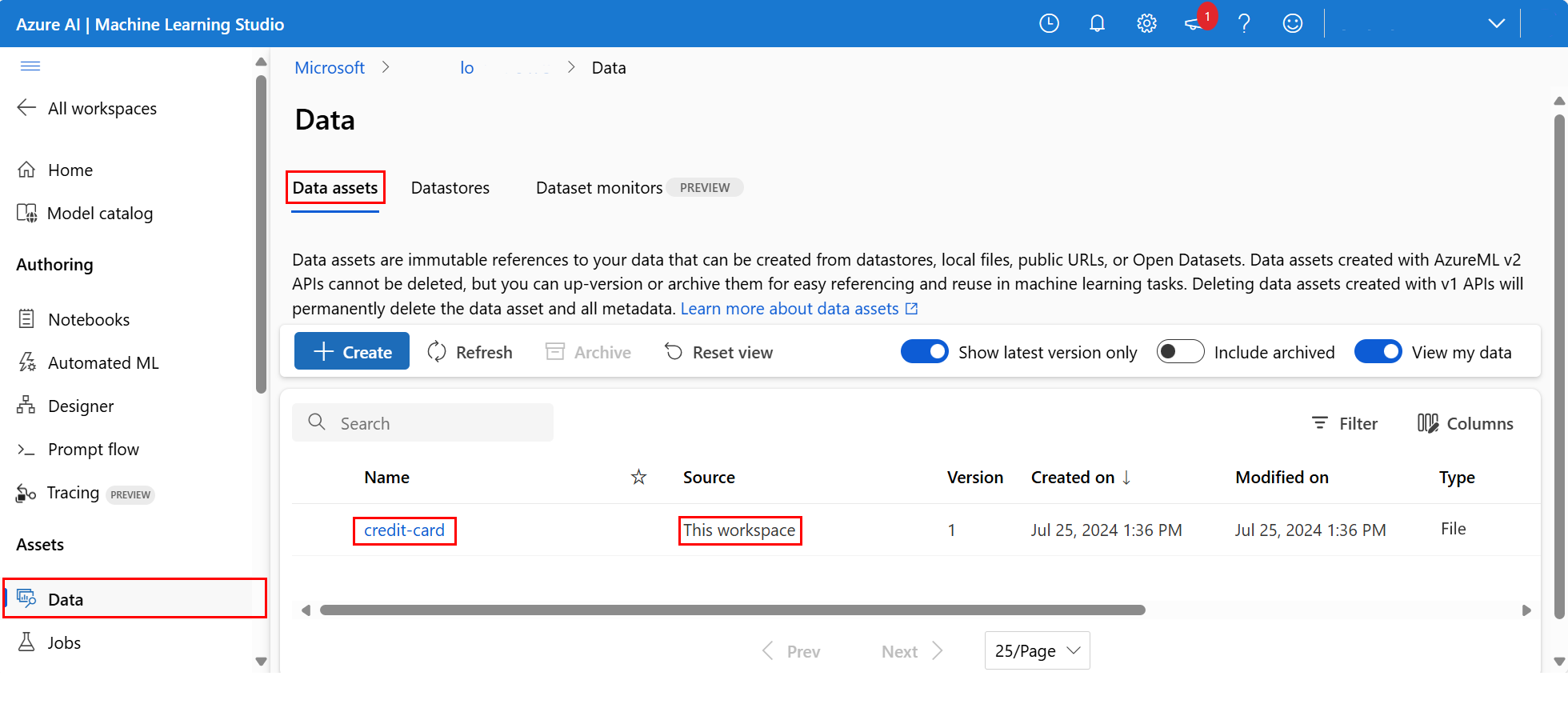
Esses dados são chamados de cartão de crédito e, na guia Ativos de dados, podemos vê-los na coluna Nome.
Um armazenamento de dados do Azure Machine Learning é uma referência a uma conta de armazenamento existente no Azure. Um armazenamento de dados oferece estes benefícios:
Uma API comum e fácil de usar, para interagir com diferentes tipos de armazenamento
- Azure Data Lake Storage
- Blob
- Ficheiros
e métodos de autenticação.
Uma maneira mais fácil de descobrir armazenamentos de dados úteis, quando se trabalha em equipe.
Em seus scripts, uma maneira de ocultar informações de conexão para acesso a dados baseado em credenciais (entidade de serviço/SAS/chave).
Aceder aos seus dados num bloco de notas
Os Pandas suportam diretamente URIs - este exemplo mostra como ler um arquivo CSV de um armazenamento de dados do Azure Machine Learning:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
No entanto, como mencionado anteriormente, pode se tornar difícil lembrar desses URIs. Além disso, você deve substituir manualmente todos os <valores de substring> no comando pd.read_csv com os valores reais para seus recursos.
Você desejará criar ativos de dados para dados acessados com frequência. Aqui está uma maneira mais fácil de acessar o arquivo CSV no Pandas:
Importante
Em uma célula de notebook, execute este código para instalar a azureml-fsspec biblioteca Python em seu kernel Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Para obter mais informações sobre o acesso a dados em um bloco de anotações, visite Acessar dados do armazenamento em nuvem do Azure durante o desenvolvimento interativo.
Criar uma nova versão do ativo de dados
Os dados precisam de alguma limpeza leve, para torná-los adequados para treinar um modelo de aprendizado de máquina. Dispõe de:
- dois cabeçalhos
- uma coluna de ID do cliente; não usaríamos esse recurso no Machine Learning
- espaços no nome da variável de resposta
Além disso, em comparação com o formato CSV, o formato de arquivo Parquet torna-se uma maneira melhor de armazenar esses dados. O Parquet oferece compressão e mantém o esquema. Para limpar os dados e armazená-los no Parquet, use:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Esta tabela mostra a estrutura dos dados no arquivo default_of_credit_card_clients.csv original. CSV baixado em uma etapa anterior. Os dados carregados contêm 23 variáveis explicativas e 1 variável de resposta, como mostrado aqui:
| Nome(s) da coluna | Tipo de variável | Description |
|---|---|---|
| X1 | Explicação | Montante do crédito concedido (NT dólar): inclui tanto o crédito ao consumo individual como o crédito familiar (suplementar). |
| X2 | Explicação | Sexo (1 = masculino; 2 = feminino). |
| X3 | Explicação | Educação (1 = pós-graduação; 2 = universidade; 3 = ensino médio; 4 = outros). |
| X4 | Explicação | Estado civil (1 = casado; 2 = solteiro; 3 = outros). |
| X5 | Explicação | Idade (anos). |
| X6-X11 | Explicação | Histórico de pagamentos passados. Rastreamos os registros de pagamentos mensais anteriores (de abril a setembro de 2005). -1 = remuneração devida; 1 = atraso de pagamento de um mês; 2 = atraso de pagamento de dois meses; . . .; 8 = atraso de pagamento de oito meses; 9 = atraso de pagamento por nove meses ou mais. |
| X12-17 | Explicação | Valor do extrato da fatura (NT dólar) de abril a setembro de 2005. |
| X18-23 | Explicação | Valor do pagamento anterior (NT dólar) de abril a setembro de 2005. |
| Y | Response | Pagamento por defeito (Sim = 1, Não = 0) |
Em seguida, crie uma nova versão do ativo de dados (os dados são carregados automaticamente para o armazenamento em nuvem). Para esta versão, adicione um valor de tempo, para que cada vez que esse código for executado, um número de versão diferente seja criado.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
O arquivo de parquet limpo é a fonte de dados da versão mais recente. Este código mostra primeiro o conjunto de resultados da versão CSV e, em seguida, a versão do Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Clean up resources (Limpar recursos)
Se você planeja continuar agora para outros tutoriais, pule para Próximas etapas.
Parar instância de computação
Se você não planeja usá-lo agora, pare a instância de computação:
- No estúdio, na área de navegação esquerda, selecione Computar.
- Nas guias superiores, selecione Instâncias de computação
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Eliminar todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.

Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Próximos passos
Para obter mais informações sobre ativos de dados, visite Criar ativos de dados.
Para obter mais informações sobre armazenamentos de dados, visite Criar datastores.
Continue com o próximo tutorial para aprender a desenvolver um script de treinamento: