Fiabilidade no Azure Traffic Manager
Este artigo contém recuperação de desastres entre regiões e suporte de continuidade de negócios para o Azure Traffic Manager.
Recuperação de desastres entre regiões e continuidade de negócios
A recuperação de desastres (DR) consiste na recuperação de eventos de alto impacto, como desastres naturais ou implantações com falha que resultam em tempo de inatividade e perda de dados. Independentemente da causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que suporte ativamente a DR. Antes de começar a pensar em criar seu plano de recuperação de desastres, consulte Recomendações para projetar uma estratégia de recuperação de desastres.
Quando se trata de DR, a Microsoft usa o modelo de responsabilidade compartilhada. Em um modelo de responsabilidade compartilhada, a Microsoft garante que a infraestrutura de linha de base e os serviços da plataforma estejam disponíveis. Ao mesmo tempo, muitos serviços do Azure não replicam dados automaticamente ou recorrem de uma região com falha para replicação cruzada para outra região habilitada. Para esses serviços, você é responsável por configurar um plano de recuperação de desastres que funcione para sua carga de trabalho. A maioria dos serviços executados nas ofertas de plataforma como serviço (PaaS) do Azure fornecem recursos e orientação para dar suporte à DR e você pode usar recursos específicos do serviço para dar suporte à recuperação rápida para ajudar a desenvolver seu plano de DR.
O Azure Traffic Manager é um balanceador de carga de tráfego baseado em DNS que permite distribuir tráfego para seus aplicativos voltados para o público em regiões globais do Azure. O Traffic Manager também fornece aos seus endpoints públicos alta disponibilidade e capacidade de resposta rápida.
O Gerenciador de Tráfego usa o DNS para direcionar as solicitações do cliente para o ponto de extremidade de serviço apropriado com base em um método de roteamento de tráfego. O gerenciador de tráfego também fornece monitoramento de integridade para cada ponto de extremidade. O ponto de extremidade pode ser qualquer serviço voltado para a Internet hospedado dentro ou fora do Azure. O Gestor de Tráfego proporciona vários métodos de encaminhamento de tráfego e opções de monitorização de pontos finais para satisfazer diferentes necessidades das aplicações e modelos de ativação pós-falha automática. O Gestor de Tráfego é resiliente a falhas, incluindo a falhas numa região do Azure inteira.
Recuperação de desastres em geografia de várias regiões
O DNS é um dos mecanismos mais eficientes para desviar o tráfego da rede. O DNS é eficiente porque geralmente é global e externo ao data center. O DNS também está isolado de qualquer falha de nível regional ou de zona de disponibilidade (AZ).
Há dois aspetos técnicos para configurar sua arquitetura de recuperação de desastres:
Usando um mecanismo de implantação para replicar instâncias, dados e configurações entre ambientes primários e em espera. Esse tipo de recuperação de desastres pode ser feito nativamente por meio do Azure Site Recovery, consulte a documentação do Azure Site Recovery por meio de dispositivos/serviços de parceiros do Microsoft Azure, como Veritas ou NetApp.
Desenvolvimento de uma solução para desviar o tráfego de rede/web do site principal para o site em espera. Esse tipo de recuperação de desastres pode ser obtido por meio do DNS do Azure, do Gerenciador de Tráfego do Azure (DNS) ou de balanceadores de carga globais de terceiros.
Este artigo se concentra especificamente no planejamento de recuperação de desastres do Azure Traffic Manager.
Deteção, notificação e gerenciamento de interrupções
Durante um desastre, o ponto de extremidade principal é investigado e o status muda para degradado e o local de recuperação de desastres permanece online. Por predefinição, o Gestor de Tráfego envia todo o tráfego para o ponto final primário (com a prioridade mais alta). Se o ponto de extremidade primário parecer degradado, o Gerenciador de Tráfego roteia o tráfego para o segundo ponto de extremidade, desde que permaneça íntegro. Pode-se configurar mais pontos de extremidade no Gerenciador de Tráfego que podem servir como pontos de extremidade de failover extras ou, como balanceadores de carga compartilhando a carga entre pontos de extremidade.
Configurar a recuperação de desastres e a deteção de interrupções
Quando você tem arquiteturas complexas e vários conjuntos de recursos capazes de executar a mesma função, você pode configurar o Gerenciador de Tráfego do Azure (com base no DNS) para verificar a integridade de seus recursos e rotear o tráfego do recurso não íntegro para o recurso íntegro.
No exemplo a seguir, tanto a região primária quanto a secundária têm uma implantação completa. Essa implantação inclui os serviços de nuvem e um banco de dados sincronizado.
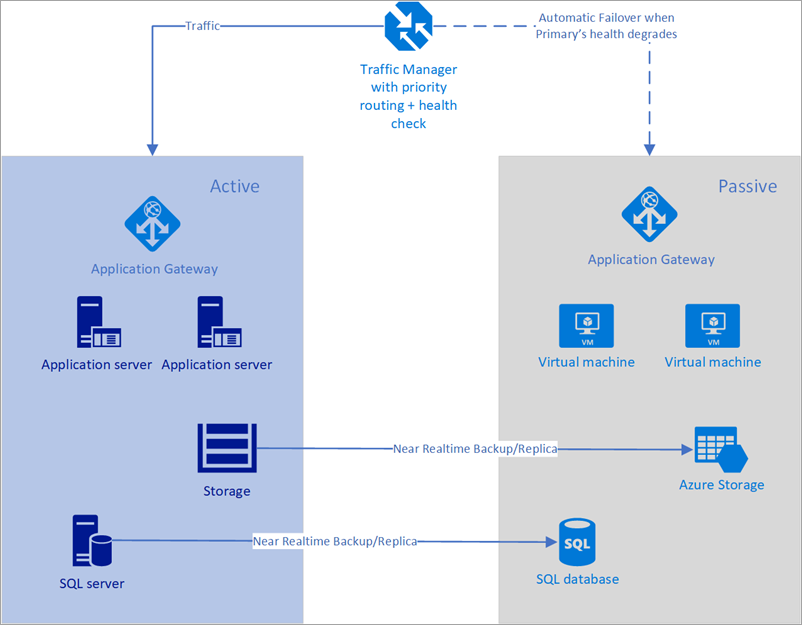
Figura - Failover automático usando o Gerenciador de Tráfego do Azure
No entanto, apenas a região primária está lidando ativamente com solicitações de rede dos usuários. A região secundária torna-se ativa somente quando a região primária sofre uma interrupção de serviço. Nesse caso, todas as novas solicitações de rede são encaminhadas para a região secundária. Como o backup do banco de dados é quase instantâneo, ambos os balanceadores de carga têm IPs que podem ser verificados e as instâncias estão sempre ativas e em execução, essa topologia fornece uma opção para um RTO baixo e failover sem qualquer intervenção manual. A região de failover secundária deve estar pronta para entrar em operação imediatamente após a falha da região primária.
Este cenário é ideal para o uso do Gerenciador de Tráfego do Azure que tem testes incorporados para vários tipos de verificações de integridade, incluindo http / https e TCP. O Gerenciador de Tráfego do Azure também tem um mecanismo de regras que pode ser configurado para failover quando ocorre uma falha, conforme descrito abaixo. Vamos considerar a seguinte solução usando o Gerenciador de Tráfego:
- O Cliente tem o ponto de extremidade da Região #1 conhecido como prod.contoso.com com um IP estático como 100.168.124.44 e um ponto de extremidade da Região #2 conhecido como dr.contoso.com com um IP estático como 100.168.124.43.
- Cada um desses ambientes é frontado por meio de uma propriedade voltada para o público, como um balanceador de carga. O balanceador de carga pode ser configurado para ter um ponto de extremidade baseado em DNS ou um nome de domínio totalmente qualificado (FQDN), como mostrado acima.
- Todas as instâncias na Região 2 estão em replicação quase em tempo real com a Região 1. Além disso, as imagens da máquina estão atualizadas e todos os dados de software/configuração são corrigidos e estão de acordo com a Região 1.
- O dimensionamento automático é pré-configurado com antecedência.
Para configurar o failover com o Azure Traffic Manager:
Criar um novo perfil do Azure Traffic Manager Crie um novo perfil do Azure Traffic Manager com o nome contoso123 e selecione o método de Roteamento como Prioridade. Se você tiver um grupo de recursos pré-existente ao qual deseja se associar, poderá selecionar um grupo de recursos existente, caso contrário, crie um novo grupo de recursos.
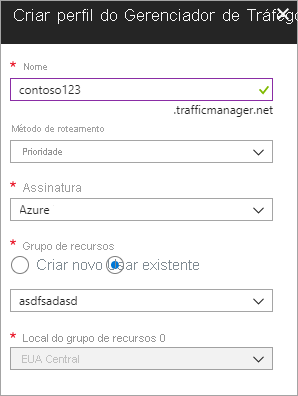
Figura - Criar um perfil do Gerenciador de Tráfego
Criar pontos de extremidade dentro do perfil do Gerenciador de Tráfego
Nesta etapa, você cria pontos de extremidade que apontam para os locais de produção e recuperação de desastres. Aqui, escolha o Tipo como um ponto de extremidade externo, mas se o recurso estiver hospedado no Azure, você também poderá escolher o ponto de extremidade do Azure. Se você escolher o ponto de extremidade do Azure, selecione um recurso de Destino que seja um Serviço de Aplicativo ou um IP Público alocado pelo Azure. A prioridade é definida como 1 , uma vez que é o serviço principal para a Região 1. Da mesma forma, crie também o ponto de extremidade de recuperação de desastres no Gerenciador de Tráfego.
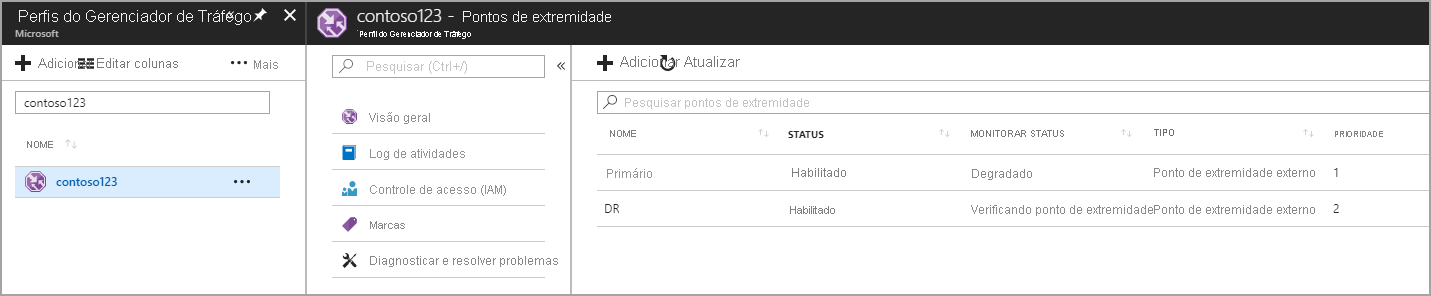
Figura - Criar pontos de extremidade de recuperação de desastres
Configurar verificação de integridade e configuração de failover
Nesta etapa, você define o TTL DNS para 10 segundos, o que é honrado pela maioria dos resolvedores recursivos voltados para a Internet. Essa configuração significa que nenhum resolvedor de DNS armazenará as informações em cache por mais de 10 segundos.
Para as configurações do monitor de ponto de extremidade, o caminho é definido como atual em / ou raiz, mas você pode personalizar as configurações do ponto de extremidade para avaliar um caminho, por exemplo, prod.contoso.com/index.
O exemplo abaixo mostra o https como o protocolo de sondagem. No entanto, você pode escolher http ou tcp também. A escolha do protocolo depende da aplicação final. O intervalo de sondagem é definido como 10 segundos, o que permite uma sondagem rápida, e a repetição é definida como 3. Como resultado, o Gerenciador de Tráfego fará failover para o segundo ponto de extremidade se três intervalos consecutivos registrarem uma falha.
A fórmula a seguir define o tempo total para um failover automatizado:
Time for failover = TTL + Retry * Probing intervalE neste caso, o valor é 10 + 3 * 10 = 40 segundos (Max).
Se a Repetição estiver definida como 1 e o TTL estiver definido como 10 segundos, o tempo de failover 10 + 1 * 10 = 20 segundos.
Defina a Repetição para um valor maior que 1 para eliminar as chances de failovers devido a falsos positivos ou quaisquer pequenas falhas de rede.
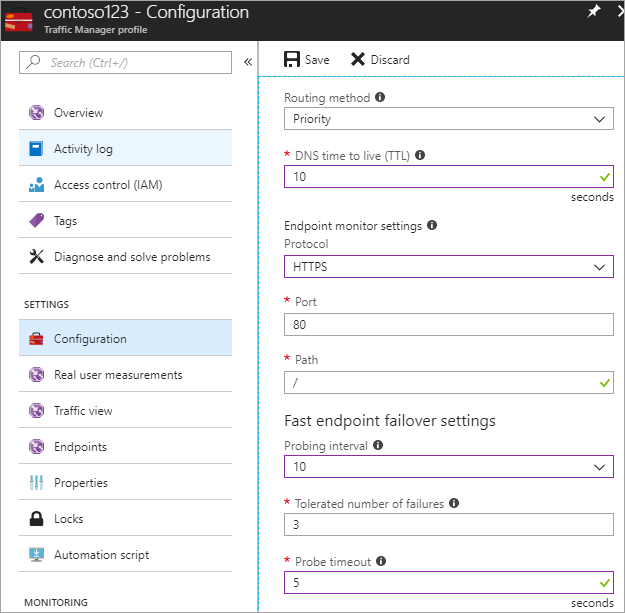
Figura - Configurar verificação de integridade e configuração de failover
Próximos passos
Saiba mais sobre o Azure Traffic Manager.
Saiba mais sobre o DNS do Azure.