Gerenciamento de continuidade de negócios no Azure
O Azure mantém um dos programas de gerenciamento de continuidade de negócios mais maduros e respeitados do setor. O objetivo da continuidade de negócios no Azure é criar e avançar a capacidade de recuperação e resiliência para todos os serviços recuperáveis de forma independente, seja um serviço voltado para o cliente (parte de uma oferta do Azure) ou um serviço de plataforma de suporte interno.
Para entender a continuidade dos negócios, é importante observar que muitas ofertas são compostas por vários serviços. No Azure, cada serviço é identificado estaticamente por meio de ferramentas e é a unidade de medida usada para privacidade, segurança, inventário, gerenciamento de continuidade de negócios de risco e outras funções. Para medir adequadamente as capacidades de um serviço, os três elementos de pessoas, processos e tecnologia são incluídos para cada serviço, independentemente do tipo de serviço.
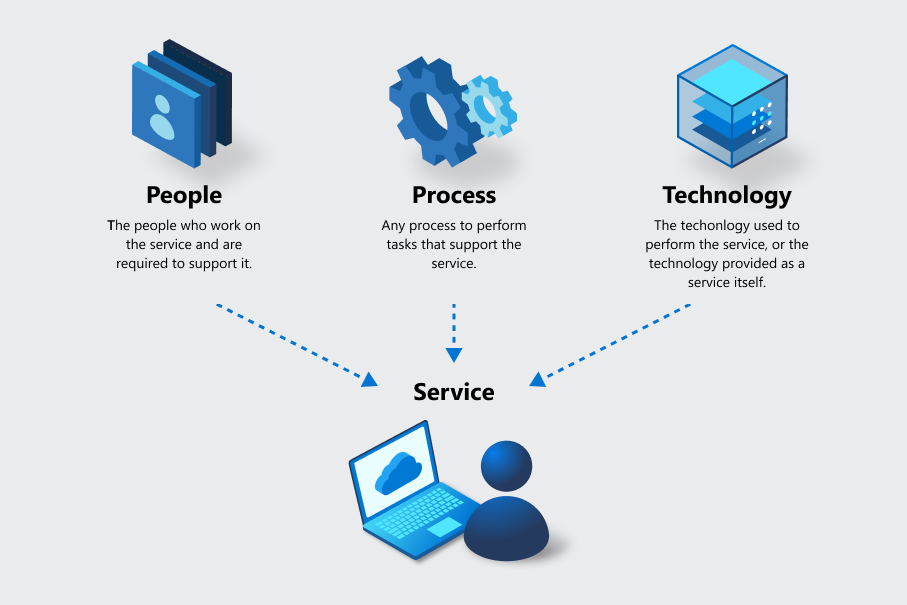
Por exemplo:
- Se houver um processo de negócios baseado em pessoas, como um help desk ou uma equipe, a prestação de serviços é o que eles fazem. As pessoas utilizam processos e tecnologia para realizar o serviço.
- Se houver tecnologia como um serviço, como as Máquinas Virtuais do Azure, a entrega de serviços é a tecnologia junto com as pessoas e os processos que dão suporte à sua operação.
Modelo de responsabilidade partilhada
Muitas das ofertas fornecidas pelo Azure exigem que você configure a recuperação de desastres em várias regiões e não são de responsabilidade da Microsoft. Nem todos os serviços do Azure replicam dados automaticamente ou retornam automaticamente de uma região com falha para replicação cruzada para outra região habilitada. Nesses casos, você é responsável por configurar a recuperação e a replicação.
A Microsoft garante que a infraestrutura de linha de base e os serviços da plataforma estejam disponíveis. Mas, em alguns cenários, o uso exige que você duplique suas implantações e armazenamento em uma capacidade de várias regiões, se desejar. Estes exemplos ilustram o modelo de responsabilidade partilhada. É um pilar fundamental na sua estratégia de continuidade de negócios e recuperação de desastres.
Divisão de responsabilidade
Em qualquer datacenter local, você é o proprietário de toda a pilha. À medida que você move ativos para a nuvem, algumas responsabilidades são transferidas para a Microsoft. O diagrama a seguir ilustra áreas e divisão de responsabilidade entre você e a Microsoft de acordo com o tipo de implantação.
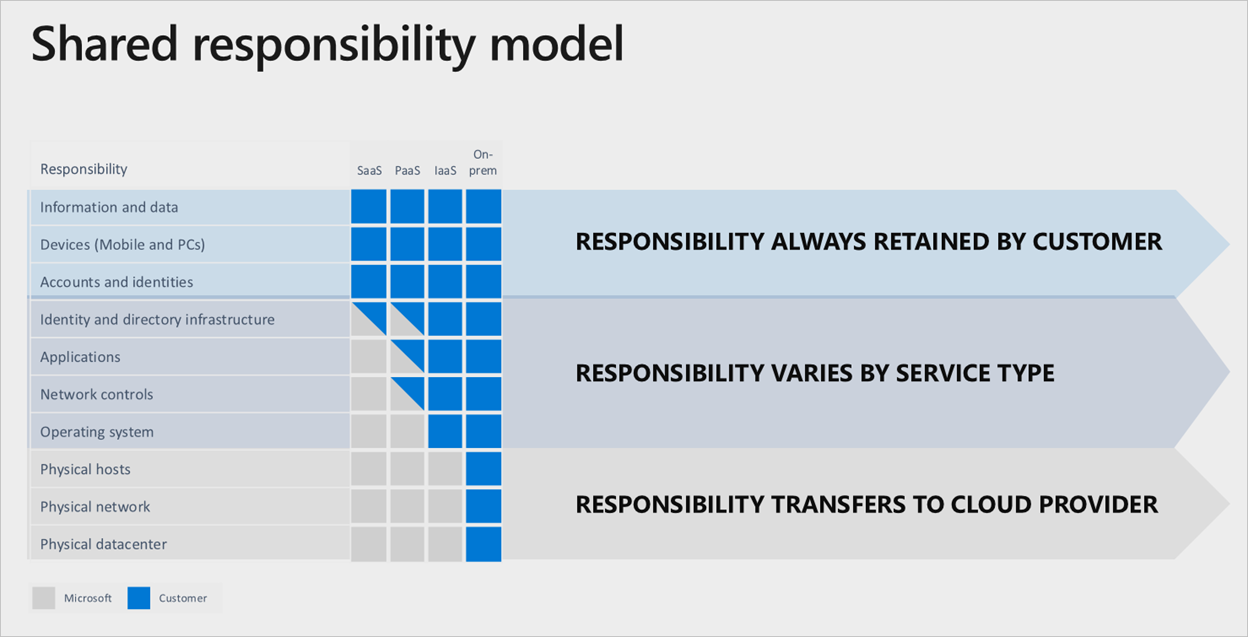
Um bom exemplo do modelo de responsabilidade compartilhada é a implantação de máquinas virtuais. Se desejar configurar a replicação entre regiões para resiliência se houver falha de região, você deverá implantar um conjunto duplicado de máquinas virtuais em uma região habilitada alternativa. O Azure não replica automaticamente esses serviços se houver uma falha. É sua responsabilidade implantar os ativos necessários. Você deve ter um processo para alterar manualmente as regiões primárias ou deve usar um gerenciador de tráfego para detetar e fazer failover automaticamente.
Todos os serviços de recuperação de desastres habilitados pelo cliente têm documentação voltada para o público para guiá-lo. Para obter um exemplo de documentação voltada para o público para recuperação de desastres habilitada pelo cliente, consulte Azure Data Lake Analytics.
Para obter mais informações sobre o modelo de responsabilidade compartilhada, consulte Central de Confiabilidade da Microsoft.
Conformidade com a continuidade de negócios: responsabilidade de nível de serviço
Cada serviço é necessário para concluir os registros de Recuperação de Desastres de Continuidade de Negócios na Ferramenta Azure Business Continuity Manager. Os proprietários de serviços podem usar a ferramenta para trabalhar em um modelo federado para concluir e incorporar requisitos que incluem:
Propriedades do serviço: define o serviço e como a recuperação de desastres e a resiliência são alcançadas e identifica a parte responsável pela recuperação de desastres (para tecnologia). Para obter detalhes sobre a propriedade da recuperação, consulte a discussão sobre o modelo de responsabilidade compartilhada na seção e diagrama anteriores.
Análise de impacto nos negócios: essa análise ajuda o proprietário do serviço a definir o RTO (Recovery Time Objetive, objetivo de tempo de recuperação) e o RPO (Recovery Point Objetive, objetivo de ponto de recuperação) com base na criticidade do serviço em uma tabela de impactos. Impactos operacionais, legais, regulatórios, de imagem de marca e financeiros são usados como metas de recuperação.
Nota
A Microsoft não publica RTO ou RPOs para serviços porque esses dados são apenas para medidas internas. Todas as promessas e medidas do cliente são baseadas em SLA porque cobrem uma gama mais ampla em comparação com RTO ou RPO, que só é aplicável em perdas catastróficas.
Dependências: cada serviço mapeia as dependências (outros serviços) necessárias para operar, não importa quão crítico, e é mapeado para tempo de execução, necessário apenas para recuperação ou ambos. Se houver dependências de armazenamento, outros dados serão mapeados que definem o que está armazenado e se exigem instantâneos point-in-time, por exemplo.
Força de trabalho: Como observado na definição de um serviço, é importante saber a localização e a quantidade de força de trabalho capaz de suportar o serviço, garantindo que não haja pontos únicos de falha, e se os funcionários críticos estão dispersos para evitar falhas por coabitação em um único local.
Fornecedores externos: a Microsoft mantém uma lista abrangente de fornecedores externos e os fornecedores considerados críticos são medidos em termos de capacidades. Se identificado por um serviço como uma dependência, os recursos do fornecedor são comparados às necessidades do serviço para garantir que uma interrupção de terceiros não interrompa os serviços do Azure.
Classificação de recuperação: esta classificação é exclusiva do programa Azure Business Continuity Management. Esta classificação mede vários elementos-chave para criar uma pontuação de resiliência:
- Disposição para failover: Embora possa haver um processo, ele pode não ser a primeira escolha para interrupções de curto prazo.
- Automatização de failover.
- Automatização da decisão de failover.
O tempo mais confiável e mais curto para failover é um serviço automatizado e que não requer decisão humana. Um serviço automatizado usa monitoramento de pulsação ou transações sintéticas para determinar que um serviço está inativo e iniciar a correção imediata.
Plano e teste de recuperação: o Azure exige que cada serviço tenha um plano de recuperação detalhado e teste esse plano como se o serviço tivesse falhado devido a uma interrupção catastrófica. Os planos de recuperação devem ser escritos para que alguém com habilidades e acesso semelhantes possa concluir as tarefas. Um plano escrito evita depender da disponibilidade de especialistas no assunto.
Os testes são feitos de várias maneiras, incluindo o autoteste em um ambiente de produção ou quase produção e como parte de exercícios de região completa do Azure em conjuntos de regiões canárias. Essas regiões habilitadas são idênticas às regiões de produção, mas podem ser desabilitadas sem afetar seus serviços. Os testes são considerados integrados porque todos os serviços são afetados simultaneamente.
Habilitação do cliente: quando você é responsável pela configuração da recuperação de desastres, o Azure precisa ter orientação de documentação voltada para o público. Para todos esses serviços, são fornecidos links para documentação e detalhes sobre o processo.
Verificar a conformidade da continuidade de negócios
Quando um serviço tiver concluído seu registro de gerenciamento de continuidade de negócios, você deverá enviá-lo para aprovação. Ele é atribuído a um profissional experiente em gerenciamento de continuidade de negócios que analisa todo o registro quanto à integridade e qualidade. Se o registro atender a todos os requisitos, ele será aprovado. Caso contrário, é rejeitado com um pedido de retrabalho. Esse processo garante que ambas as partes concordem que a conformidade com a continuidade de negócios foi cumprida e que o trabalho só é atestado pelo proprietário do serviço. As equipes de auditoria interna e conformidade do Azure também fazem amostragem aleatória periódica para garantir que os melhores dados estejam sendo enviados.
Testes de serviços
A Microsoft e o Azure fazem testes extensivos para recuperação de desastres e prontidão para a zona de disponibilidade. Os serviços são autotestados em um ambiente de produção ou pré-produção para demonstrar a capacidade de recuperação independente para serviços que não dependem de grandes failovers de plataforma.
Para garantir que os serviços possam se recuperar da mesma forma em um cenário de região descendente, o teste do tipo "pull-the-plug" é feito em ambientes canários que são regiões totalmente implantadas que correspondem à produção. Por exemplo, os clusters, racks e unidades de alimentação são literalmente desligados para simular uma falha total da região.
Durante esses testes, o Azure usa o mesmo processo de produção para deteção, notificação, resposta e recuperação. Nenhum indivíduo está esperando uma perfuração, e os engenheiros confiados para a recuperação são os recursos normais de rotação de plantão. Esse tempo evita depender de especialistas no assunto que podem não estar disponíveis durante um evento real.
Incluídos nesses testes estão os serviços em que você é responsável por configurar a recuperação de desastres seguindo a documentação pública da Microsoft. As equipes de serviço criam instâncias semelhantes às do cliente para mostrar que a recuperação de desastres habilitada pelo cliente funciona conforme o esperado e que as instruções fornecidas são precisas.
Para obter mais informações sobre certificações, consulte a Central de Confiabilidade da Microsoft e a seção sobre conformidade.