Disponibilidade do SAP HANA em uma região do Azure
Este artigo descreve vários cenários de disponibilidade para o SAP HANA em uma região do Azure. O Azure tem muitas regiões, espalhadas pelo mundo. Para obter a lista de regiões do Azure, consulte Regiões do Azure. Para implantar o SAP HANA em VMs em uma região do Azure, a Microsoft oferece a implantação de uma única VM com uma instância HANA. Para maior disponibilidade, você pode implantar duas VMs com duas instâncias HANA usando um conjunto de escala flexível com FD=1, zonas de disponibilidade ou um conjunto de disponibilidade que usa replicação do sistema HANA para disponibilidade.
As regiões do Azure que fornecem Zonas de Disponibilidade consistem em vários data centers, cada um com sua própria fonte de energia, resfriamento e infraestrutura de rede. O objetivo de oferecer zonas diferentes dentro de uma única região do Azure é habilitar a implantação de aplicativos em duas ou três Zonas de Disponibilidade disponíveis. Ao distribuir sua implantação de aplicativo entre zonas, quaisquer problemas de energia ou de rede que afetem uma infraestrutura específica da Zona de Disponibilidade do Azure não interromperiam totalmente a funcionalidade do seu aplicativo na região do Azure. Embora possa haver alguma capacidade reduzida, como a perda potencial de VMs em uma zona, as VMs nas zonas restantes continuariam a operar sem interrupção. Para configurar duas instâncias HANA em VMs separadas abrangendo zonas diferentes, você tem a opção de implantar VMs usando a opção de implantação de escala flexível definida com FD=1 ou zonas de disponibilidade.
Para aumentar a disponibilidade em uma região, é recomendável implantar duas VMs com duas instâncias HANA usando um conjunto de disponibilidade. Um Conjunto de Disponibilidade do Azure é um recurso de agrupamento lógico que garante que os recursos de VM configurados no Conjunto de Disponibilidade sejam isolados de falhas uns dos outros quando são implantados em um datacenter do Azure. O Azure garante que as VMs que colocar num Conjunto de Disponibilidade são executadas em vários servidores físicos, suportes de computação, unidades de armazenamento e comutadores de rede. Em algumas documentações do Azure, essa configuração é chamada de posicionamentos em diferentes domínios de atualização e falha. Esses posicionamentos geralmente estão dentro de um datacenter do Azure. Supondo que problemas de fonte de energia e rede afetariam o datacenter que você está implantando, toda a sua capacidade em uma região do Azure seria afetada.
O posicionamento de datacenters que representam as Zonas de Disponibilidade do Azure é um compromisso entre o fornecimento de latência de rede aceitável entre serviços implantados em zonas diferentes e uma distância entre datacenters. Idealmente, catástrofes naturais não afetariam a energia, o fornecimento de rede e a infraestrutura de todas as Zonas de Disponibilidade nesta região. No entanto, como catástrofes naturais monumentais mostraram, as Zonas de Disponibilidade nem sempre fornecem a disponibilidade desejada dentro de uma região. Pense no furacão Maria que atingiu a ilha de Porto Rico em 20 de setembro de 2017. O furacão basicamente causou um apagão de quase 100% na ilha de 90 milhas de largura.
Cenário de VM única
Em um cenário de VM única, você cria uma VM do Azure para a instância do SAP HANA. Você usa o Armazenamento Premium do Azure para hospedar o disco do sistema operacional e todos os seus discos de dados. O SLA de tempo de atividade do Azure de 99,9% e os SLAs de outros componentes do Azure são suficientes para você cumprir seus SLAs de disponibilidade para seus clientes. Nesse cenário, você não precisa usar um Conjunto de Disponibilidade do Azure para VMs que executam a camada DBMS. Nesse cenário, você confia em dois recursos diferentes:
- Reinicialização automática da VM do Azure (também conhecida como reparo de serviço do Azure)
- Reinicialização automática do SAP HANA
A reinicialização automática da VM do Azure, ou reparo de serviço, é uma funcionalidade no Azure que funciona em dois níveis:
- O host do servidor do Azure verifica a integridade de uma VM hospedada no host do servidor.
- O controlador de malha do Azure monitora a integridade e a disponibilidade do host do servidor.
Uma funcionalidade de verificação de integridade monitora a integridade de cada VM hospedada em um host de servidor do Azure. Se uma VM cair em um estado não íntegro, uma reinicialização da VM pode ser iniciada pelo agente de host do Azure que verifica a integridade da VM. O controlador de malha verifica a integridade do host verificando muitos parâmetros diferentes que podem indicar problemas com o hardware do host. Ele também verifica a acessibilidade do host através da rede. Uma indicação de problemas com o anfitrião pode levar aos seguintes eventos:
- Se o host sinalizar um estado de integridade incorreto, uma reinicialização do host e uma reinicialização das VMs que estavam em execução no host serão acionadas.
- Se o host não estiver em um estado íntegro após a reinicialização bem-sucedida, uma reimplantação das VMs que estavam originalmente no nó agora não íntegro em um servidor host íntegro será iniciada. Nesse caso, o host original é marcado como não íntegro. Ele não será usado para implantações adicionais até que seja limpo ou substituído.
- Se o host não íntegro tiver problemas durante o processo de reinicialização, uma reinicialização imediata das VMs em um host íntegro será acionada.
Com o monitoramento de host e VM fornecido pelo Azure, as VMs do Azure que enfrentam problemas de host são reiniciadas automaticamente em um host do Azure íntegro.
Importante
A recuperação do serviço do Azure não reiniciará VMs Linux em que o SO convidado esteja em estado de pânico do kernel. As configurações padrão das versões Linux comumente usadas não são a reinicialização automática de VMs ou servidores onde o kernel Linux está em estado de pânico. Em vez disso, o padrão prevê manter o sistema operacional em estado de pânico do kernel para poder anexar um depurador do kernel para analisar. O Azure está honrando esse comportamento ao não reiniciar automaticamente uma VM com o SO convidado nesse estado. Suponhamos que tais ocorrências são extremamente raras. Você pode substituir o comportamento padrão para habilitar uma reinicialização da VM. Para alterar o comportamento padrão, ative o parâmetro 'kernel.panic' em /etc/sysctl.conf. O tempo definido para esse parâmetro é em segundos. Os valores recomendados comuns são aguardar de 20 a 30 segundos antes de acionar a reinicialização por meio desse parâmetro. Para obter mais informações, consulte sysctl.conf.
O segundo recurso no qual você confia nesse cenário é o fato de que o serviço HANA executado em uma VM reiniciada é iniciado automaticamente após a reinicialização da VM. Você pode configurar a reinicialização automática do serviço HANA através dos serviços de vigilância dos vários serviços HANA.
Você pode melhorar esse cenário de VM única adicionando um nó de failover frio a uma configuração do SAP HANA. Na documentação do SAP HANA, essa configuração é chamada de autofailover de host. Essa configuração pode fazer sentido em uma situação de implantação local em que o hardware do servidor é limitado e você dedica um nó de servidor único como o nó de failover automático do host para um conjunto de hosts de produção. Mas no Azure, onde a infraestrutura subjacente do Azure fornece um servidor de destino íntegro para uma reinicialização bem-sucedida da VM, não faz sentido implantar o autofailover de host do SAP HANA. Devido à recuperação do serviço do Azure, não há nenhuma arquitetura de referência que preveja um nó em espera para o autofailover do host HANA.
Caso especial de configurações de expansão do SAP HANA no Azure
Arquiteturas de alta disponibilidade baseadas em nó de espera ou replicação do sistema HANA podem ser encontradas nos seguintes documentos. Nos casos em que os nós em espera ou a alta disponibilidade da replicação do sistema HANA não são usados nas configurações de expansão do SAP HANA, você pode depender dos recursos de reparo de serviço das VMs do Azure e da reinicialização automática da instância do SAP HANA assim que a VM estiver operacional novamente.
- RedHat Enterprise Linux
- Servidor SUSE Linux Enterprise
Cenários de disponibilidade para duas VMs diferentes
Para garantir a disponibilidade do sistema HANA em uma região específica, você tem a opção de configurar duas VMs nas zonas de disponibilidade da região ou dentro da região. Para atingir esse objetivo, você pode configurar as VMs usando o conjunto de escala flexível, zonas de disponibilidade ou opção de implantação de conjunto de disponibilidade. A configuração base no Azure teria a seguinte aparência:
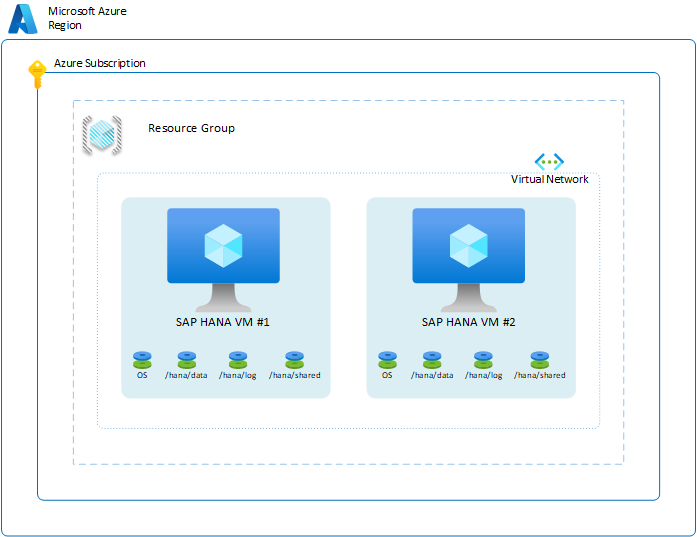
Para ilustrar os diferentes cenários de disponibilidade do SAP HANA, algumas das camadas no diagrama são omitidas. O diagrama mostra apenas camadas que representam VMs, hosts, Conjuntos de Disponibilidade e regiões do Azure. As instâncias da Rede Virtual do Azure, os grupos de recursos e as subscrições não desempenham um papel nos cenários descritos nesta secção.
Replicar backups para uma segunda máquina virtual
Uma das configurações mais rudimentares é usar backups. Em particular, você pode ter backups de log de transações enviados de uma VM para outra VM do Azure. Você pode escolher o tipo de Armazenamento do Azure. Nesta configuração, você é responsável por criar scripts da cópia de backups agendados que são conduzidos na primeira VM para a segunda VM. Se precisar usar as segundas instâncias de VM, restaure os backups completos, incrementais/diferenciais e de log de transações até o ponto necessário.
A arquitetura se parece com:
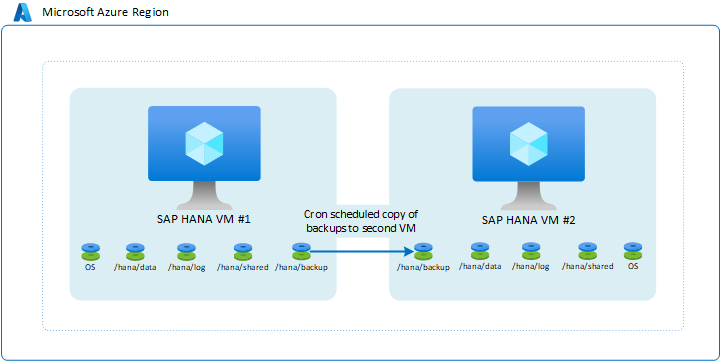
Essa configuração não é adequada para atingir ótimos tempos de RPO (Recovery Point Objetive, objetivo de ponto de recuperação) e RTO (Recovery Time Objetive, objetivo de tempo de recuperação). RTO tempos especialmente sofreria devido à necessidade de restaurar totalmente o banco de dados completo usando os backups copiados. No entanto, essa configuração é útil para recuperar da exclusão não intencional de dados nas instâncias principais. Com essa configuração, a qualquer momento, você pode restaurar para um determinado ponto no tempo, extrair os dados e importar os dados excluídos para sua instância principal. Portanto, pode fazer sentido usar um método de cópia de backup em combinação com outra funcionalidade de alta disponibilidade.
Enquanto os backups estão sendo copiados, você poderá usar uma VM menor do que a VM principal na qual a instância do SAP HANA está sendo executada. Lembre-se de que você pode anexar um número menor de VHDs a VMs menores. Para obter informações sobre os limites de tipos de VM individuais, consulte Tamanhos para máquinas virtuais Linux no Azure.
Replicação do sistema SAP HANA sem failover automático
Os cenários descritos nesta seção usam a replicação do sistema SAP HANA. Para obter a documentação do SAP, consulte Replicação do sistema. Cenários sem failover automático não são comuns para configurações em uma região do Azure. Uma configuração sem failover automático, embora evitando uma configuração do Pacemaker, obriga você a monitorar e fazer failover manualmente. Uma vez que isso requer e esforços também, a maioria dos clientes está confiando na recuperação do serviço do Azure. Existem alguns casos de borda em que essa configuração pode ajudar em termos de cenários de falha. Ou, em alguns casos, um cliente pode querer perceber mais eficiência.
Replicação do sistema SAP HANA sem failover automático e sem pré-carregamento de dados
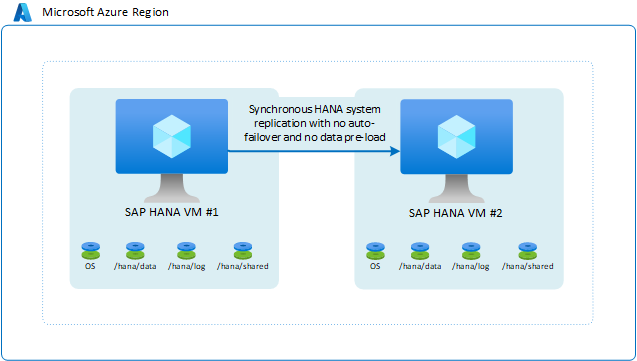
Nesse cenário, você usa a replicação do sistema SAP HANA para mover dados de forma síncrona para obter um RPO de 0. Por outro lado, você tem um RTO longo o suficiente para não precisar de failover ou pré-carregamento de dados no cache de instâncias do HANA. Neste caso, é possível obter mais economia na sua configuração tomando as seguintes ações:
- Execute outra instância do SAP HANA na segunda VM. A instância do SAP HANA na segunda VM ocupa a maior parte da memória da máquina virtual. No caso de um failover para a segunda VM, você precisa desligar a instância do SAP HANA em execução que tem os dados totalmente carregados na segunda VM, para que os dados replicados possam ser carregados no cache da instância HANA de destino na segunda VM.
- Use um tamanho de VM menor na segunda VM. Se ocorrer um failover, você terá uma etapa adicional antes do failover manual. Nesta etapa, você redimensiona a VM para o tamanho da VM de origem.
O cenário é semelhante a:
Nota
Mesmo que você não use o pré-carregamento de dados no destino de replicação do sistema HANA, precisará de pelo menos 64 GB de memória. Você também precisa de memória suficiente, além de 64 GB para manter os dados rowstore na memória da instância de destino.
Replicação do sistema SAP HANA sem failover automático e com pré-carregamento de dados
Nesse cenário, os dados replicados para a instância HANA na segunda VM são pré-carregados. Isso elimina as duas vantagens de não pré-carregar dados. Nesse caso, não é possível executar outro sistema SAP HANA na segunda VM. Também não é possível usar um tamanho de VM menor. Por isso, os clientes raramente implementam esse cenário.
Replicação do sistema SAP HANA com failover automático
Na configuração de disponibilidade padrão e mais comum em uma região do Azure, duas VMs do Azure que executam pacotes Linux com HA têm um cluster de failover definido. O cluster HA Linux é baseado na Pacemaker estrutura usando SLES ou RHEL com um fencing device SLES ou RHEL como exemplo.
Do ponto de vista do SAP HANA, o modo de replicação usado é sincronizado e um failover automático é configurado. Na segunda VM, a instância do SAP HANA atua como um nó hot standby. O nó em espera recebe um fluxo síncrono de registros de alteração da instância principal do SAP HANA. À medida que as transações são confirmadas pelo aplicativo no nó primário do HANA, o nó principal do HANA aguarda para confirmar a confirmação do aplicativo até que o nó secundário do SAP HANA confirme que recebeu o registro de confirmação. O SAP HANA oferece dois modos de replicação síncrona. Para obter detalhes e uma descrição das diferenças entre esses dois modos de replicação síncrona, consulte o artigo SAP Replication modes for SAP HANA system replication.
A configuração geral é semelhante a:
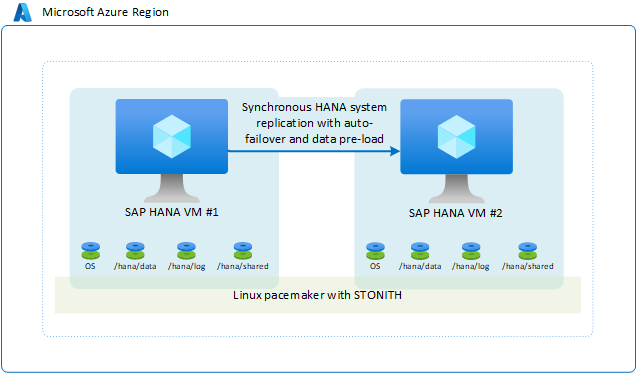
Você pode escolher essa solução porque ela permite que você obtenha um RPO=0 e um RTO baixo. Configure a conectividade do cliente SAP HANA para que os clientes SAP HANA usem o endereço IP virtual para se conectar à configuração de replicação do sistema HANA. Essa configuração elimina a necessidade de reconfigurar o aplicativo se ocorrer um failover para o nó secundário. Nesse cenário, as SKUs de VM do Azure para as VMs primárias e secundárias devem ser as mesmas.
Próximos passos
Para obter orientação passo a passo sobre como configurar essas configurações no Azure, consulte:
- Configurar a replicação do sistema SAP HANA em VMs do Azure
- Alta disponibilidade para SAP HANA usando replicação de sistema
Para obter mais informações sobre a disponibilidade do SAP HANA nas regiões do Azure, consulte: