Elevada disponibilidade do SAP HANA nas VMs do Azure no Red Hat Enterprise Linux
Para desenvolvimento local, você pode usar a replicação do sistema HANA ou o armazenamento compartilhado para estabelecer alta disponibilidade (HA) para o SAP HANA. Nas Máquinas Virtuais do Azure, a Replicação do Sistema HANA no Azure é atualmente a única função HA suportada.
A replicação do SAP HANA consiste em um nó primário e pelo menos um nó secundário. As alterações nos dados no nó primário são replicadas para o nó secundário de forma síncrona ou assíncrona.
Este artigo descreve como implantar e configurar máquinas virtuais (VMs), instalar a estrutura de cluster e instalar e configurar a replicação de sistema SAP HANA.
Nas configurações de exemplo, os comandos de instalação, o número de instância 03 e o ID de sistema HANA HN1 são usados.
Pré-requisitos
Leia primeiro as seguintes notas e documentos do SAP:
- SAP Note 1928533, que tem:
- A lista de tamanhos de VM do Azure com suporte para a implantação do software SAP.
- Informações de capacidade importantes para tamanhos de VM do Azure.
- O software SAP suportado e as combinações de sistema operacional (SO) e banco de dados.
- A versão necessária do kernel SAP para Windows e Linux no Microsoft Azure.
- SAP Note 2015553 lista os pré-requisitos para implantações de software SAP suportadas pelo SAP no Azure.
- O SAP Note 2002167 recomendou as configurações do sistema operacional para o Red Hat Enterprise Linux.
- O SAP Note 2009879 tem as diretrizes do SAP HANA para Red Hat Enterprise Linux.
- O SAP Note 3108302 tem as diretrizes do SAP HANA para o Red Hat Enterprise Linux 9.x.
- O SAP Note 2178632 tem informações detalhadas sobre todas as métricas de monitoramento relatadas para SAP no Azure.
- O SAP Note 2191498 tem a versão necessária do SAP Host Agent para Linux no Azure.
- O SAP Note 2243692 tem informações sobre o licenciamento SAP no Linux no Azure.
- O SAP Note 1999351 tem mais informações de solução de problemas para a Extensão de Monitoramento Avançado do Azure para SAP.
- O SAP Community WIKI tem todas as notas SAP necessárias para Linux.
- Planejamento e implementação de Máquinas Virtuais do Azure para SAP no Linux
- Implantação de Máquinas Virtuais do Azure para SAP no Linux (este artigo)
- Implantação de DBMS de Máquinas Virtuais do Azure para SAP no Linux
- Replicação do sistema SAP HANA em um cluster de marcapasso
- Documentação geral do RHEL:
- Documentação RHEL específica do Azure:
- Políticas de suporte para clusters de alta disponibilidade RHEL - Máquinas virtuais do Microsoft Azure como membros do cluster
- Instalando e configurando um cluster de alta disponibilidade do Red Hat Enterprise Linux 7.4 (e posterior) no Microsoft Azure
- Instalar o SAP HANA no Red Hat Enterprise Linux para uso no Microsoft Azure
Descrição geral
Para alcançar o HA, SAP HANA é instalado em duas VMs. Os dados são replicados usando a replicação do sistema HANA.
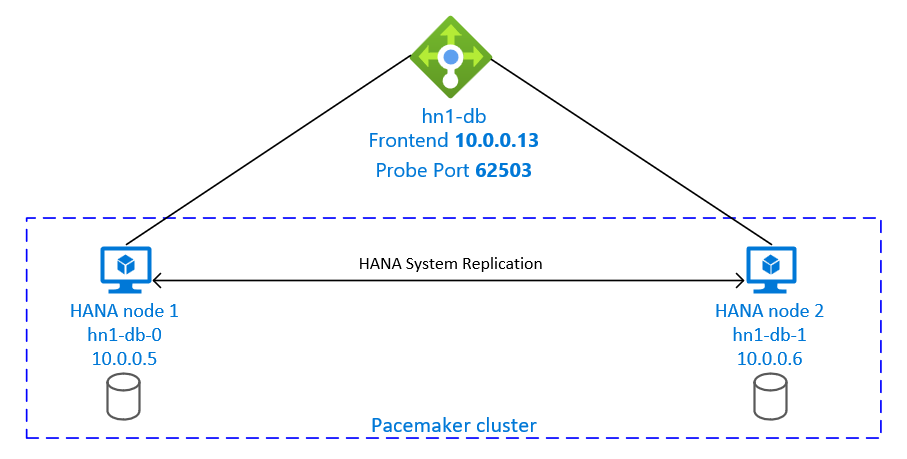
A configuração do SAP HANA System Replication usa um nome de host virtual dedicado e endereços IP virtuais. No Azure, um balanceador de carga é necessário para usar um endereço IP virtual. A configuração apresentada mostra um balanceador de carga com:
- Endereço IP front-end: 10.0.0.13 para hn1-db
- Porta da sonda: 62503
Preparar a infraestrutura
O Azure Marketplace contém imagens qualificadas para SAP HANA com o complemento de Alta Disponibilidade, que você pode usar para implantar novas VMs usando várias versões do Red Hat.
Implantar VMs Linux manualmente por meio do portal do Azure
Este documento pressupõe que você já tenha implantado um grupo de recursos, uma rede virtual do Azure e uma sub-rede.
Implante VMs para SAP HANA. Escolha uma imagem RHEL adequada que seja compatível com o sistema HANA. Você pode implantar uma VM em qualquer uma das opções de disponibilidade: conjunto de escala de máquina virtual, zona de disponibilidade ou conjunto de disponibilidade.
Importante
Certifique-se de que o sistema operacional selecionado é certificado SAP para SAP HANA nos tipos específicos de VM que você planeja usar em sua implantação. Você pode procurar tipos de VM certificados pelo SAP HANA e suas versões de SO em plataformas IaaS certificadas pelo SAP HANA. Certifique-se de examinar os detalhes do tipo de VM para obter a lista completa de versões do sistema operacional suportadas pelo SAP HANA para o tipo de VM específico.
Configurar o balanceador de carga do Azure
Durante a configuração da VM, você tem uma opção para criar ou selecionar o balanceador de carga de saída na seção de rede. Siga as etapas abaixo para configurar o balanceador de carga padrão para configuração de alta disponibilidade do banco de dados HANA.
Siga as etapas em Criar balanceador de carga para configurar um balanceador de carga padrão para um sistema SAP de alta disponibilidade usando o portal do Azure. Durante a configuração do balanceador de carga, considere os seguintes pontos:
- Configuração de IP Frontend: Crie um IP front-end. Selecione a mesma rede virtual e o mesmo nome de sub-rede que suas máquinas virtuais de banco de dados.
- Pool de back-end: crie um pool de back-end e adicione VMs de banco de dados.
- Regras de entrada: crie uma regra de balanceamento de carga. Siga as mesmas etapas para ambas as regras de balanceamento de carga.
- Endereço IP frontend: Selecione um IP front-end.
- Pool de back-end: selecione um pool de back-end.
- Portas de alta disponibilidade: selecione esta opção.
- Protocolo: Selecione TCP.
- Sonda de integridade: crie uma sonda de integridade com os seguintes detalhes:
- Protocolo: Selecione TCP.
- Porta: Por exemplo, 625<instância-não.>
- Intervalo: Digite 5.
- Limite da sonda: Digite 2.
- Tempo limite de inatividade (minutos): Digite 30.
- Ativar IP flutuante: selecione esta opção.
Nota
A propriedade numberOfProbesde configuração da sonda de integridade, também conhecida como Limite não íntegro no portal, não é respeitada. Para controlar o número de testes consecutivos bem-sucedidos ou com falha, defina a propriedade probeThreshold como 2. Atualmente, não é possível definir essa propriedade usando o portal do Azure, portanto, use a CLI do Azure ou o comando PowerShell.
Para obter mais informações sobre as portas necessárias para o SAP HANA, leia o capítulo Conexões com bancos de dados de locatários no guia Bancos de dados de locatários do SAP HANA ou no SAP Note 2388694.
Nota
Quando VMs sem endereços IP públicos são colocadas no pool de back-end de uma instância interna (sem endereço IP público) do Balanceador de Carga do Azure Padrão, não há conectividade de saída com a Internet, a menos que mais configuração seja executada para permitir o roteamento para pontos de extremidade públicos. Para obter mais informações sobre como obter conectividade de saída, consulte Conectividade de ponto de extremidade público para VMs usando o Azure Standard Load Balancer em cenários de alta disponibilidade SAP.
Importante
Não habilite carimbos de data/hora TCP em VMs do Azure colocadas atrás do Balanceador de Carga do Azure. Habilitar carimbos de data/hora TCP pode fazer com que os testes de integridade falhem. Defina o parâmetro net.ipv4.tcp_timestamps como 0. Para obter mais informações, consulte Sondas de integridade do balanceador de carga e SAP Note 2382421.
Instalar o SAP HANA
As etapas nesta seção usam os seguintes prefixos:
- [R]: A etapa aplica-se a todos os nós.
- [1]: A etapa aplica-se apenas ao nó 1.
- [2]: A etapa aplica-se apenas ao nó 2 do cluster Pacemaker.
[A] Configure o layout do disco: LVM (Logical Volume Manager).
Recomendamos que você use o LVM para volumes que armazenam dados e arquivos de log. O exemplo a seguir pressupõe que as VMs tenham quatro discos de dados anexados que são usados para criar dois volumes.
Liste todos os discos disponíveis:
ls /dev/disk/azure/scsi1/lun*Saída de exemplo:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Crie volumes físicos para todos os discos que você deseja usar:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Crie um grupo de volumes para os arquivos de dados. Use um grupo de volumes para os arquivos de log e outro para o diretório compartilhado do SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3Crie os volumes lógicos. Um volume linear é criado quando você usa
lvcreatesem o-iswitch. Sugerimos que você crie um volume distribuído para um melhor desempenho de E/S. Alinhe os tamanhos de distribuição aos valores documentados nas configurações de armazenamento SAP HANA VM. O-iargumento deve ser o número dos volumes físicos subjacentes, e o-Iargumento é o tamanho da faixa.Neste documento, dois volumes físicos são usados para o volume de dados, portanto, o
-iargumento switch é definido como 2. O tamanho da faixa para o volume de dados é 256KiB. Um volume físico é usado para o volume de log, portanto, nenhum-iou-Iswitches são explicitamente usados para os comandos de volume de log.Importante
Use o
-iswitch e defina-o como o número do volume físico subjacente quando usar mais de um volume físico para cada volume de dados, log ou compartilhado. Use a-Iopção para especificar o tamanho da faixa ao criar um volume distribuído. Consulte Configurações de armazenamento SAP HANA VM para obter as configurações de armazenamento recomendadas, incluindo tamanhos de distribuição e número de discos. Os exemplos de layout a seguir não atendem necessariamente às diretrizes de desempenho para um determinado tamanho de sistema. Eles são apenas para ilustração.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedNão monte os diretórios emitindo comandos mount. Em vez disso, insira as configurações no
fstabe emita um finalmount -apara validar a sintaxe. Comece criando os diretórios de montagem para cada volume:sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/sharedEm seguida, crie
fstabentradas para os três volumes lógicos inserindo as/etc/fstabseguintes linhas no arquivo:/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
Finalmente, monte os novos volumes de uma só vez:
sudo mount -a[A] Configure a resolução de nome de host para todos os hosts.
Você pode usar um servidor DNS ou modificar o
/etc/hostsarquivo em todos os nós criando entradas para todos os nós como esta em/etc/hosts:10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Execute a configuração do RHEL para HANA.
Configure o RHEL conforme descrito nas seguintes notas:
- 2447641 - Pacotes adicionais necessários para instalar o SAP HANA SPS 12 no RHEL 7.X
- 2292690 - SAP HANA DB: Configurações recomendadas do sistema operacional para RHEL 7
- 2777782 - SAP HANA DB: Configurações recomendadas do sistema operacional para RHEL 8
- 2455582 - Linux: Executando aplicativos SAP compilados com GCC 6.x
- 2593824 - Linux: Executando aplicativos SAP compilados com GCC 7.x
- 2886607 - Linux: Executando aplicativos SAP compilados com GCC 9.x
[A] Instale o SAP HANA, seguindo a documentação do SAP.
[A] Configure o firewall.
Crie a regra de firewall para a porta de investigação do Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
Configurar a replicação do sistema SAP HANA 2.0
As etapas nesta seção usam os seguintes prefixos:
- [R]: A etapa aplica-se a todos os nós.
- [1]: A etapa aplica-se apenas ao nó 1.
- [2]: A etapa aplica-se apenas ao nó 2 do cluster Pacemaker.
[A] Configure o firewall.
Crie regras de firewall para permitir a replicação do sistema HANA e o tráfego de clientes. As portas necessárias estão listadas nas portas TCP/IP de todos os produtos SAP. Os comandos a seguir são apenas um exemplo para permitir a replicação do sistema HANA 2.0 e o tráfego do cliente para o banco de dados SYSTEMDB, HN1 e NW1.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] Crie a base de dados de inquilinos.
Execute o seguinte comando como <hanasid>adm:
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] Configure a replicação do sistema no primeiro nó.
Faça backup dos bancos de dados como <hanasid>adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"Copie os arquivos PKI do sistema para o site secundário:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Crie o site principal:
hdbnsutil -sr_enable --name=SITE1[2] Configure a replicação do sistema no segundo nó.
Registre o segundo nó para iniciar a replicação do sistema. Execute o seguinte comando como <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[2] Inicie o HANA.
Execute o seguinte comando como <hanasid>adm para iniciar o HANA:
sapcontrol -nr 03 -function StartSystem[1] Verifique o estado da replicação.
Verifique o status da replicação e aguarde até que todos os bancos de dados estejam sincronizados. Se o status permanecer DESCONHECIDO, verifique as configurações do firewall.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Criar um cluster de marcapasso
Siga as etapas em Configurando o Pacemaker no Red Hat Enterprise Linux no Azure para criar um cluster básico do Pacemaker para este servidor HANA.
Importante
Com o SAP Startup Framework baseado em sistema, as instâncias do SAP HANA agora podem ser gerenciadas pelo systemd. A versão mínima necessária do Red Hat Enterprise Linux (RHEL) é o RHEL 8 for SAP. Conforme descrito na Nota 3189534 do SAP, quaisquer novas instalações do SAP HANA SPS07 revisão 70 ou superior, ou atualizações dos sistemas HANA para HANA 2.0 SPS07 revisão 70 ou superior, o framework SAP Startup será automaticamente registrado no systemd.
Ao usar soluções HA para gerenciar a replicação do sistema SAP HANA em combinação com instâncias SAP HANA habilitadas para sistema (consulte SAP Note 3189534), etapas adicionais são necessárias para garantir que o cluster HA possa gerenciar a instância SAP sem interferência do sistema. Portanto, para o sistema SAP HANA integrado ao systemd, etapas adicionais descritas no Red Hat KBA 7029705 devem ser seguidas em todos os nós do cluster.
Implementar ganchos de replicação do sistema SAP HANA
Esta etapa importante otimiza a integração com o cluster e melhora a deteção quando um failover de cluster é necessário. É obrigatório para a operação correta do cluster ativar o gancho SAPHanaSR. É altamente recomendável que você configure os ganchos SAPHanaSR e ChkSrv Python.
[A] Instale os agentes de recursos do SAP HANA em todos os nós. Certifique-se de habilitar um repositório que contenha o pacote. Você não precisa habilitar mais repositórios, se estiver usando uma imagem habilitada para HA RHEL 8.x ou superior.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo dnf install -y resource-agents-sap-hanaNota
Para RHEL 8.x e RHEL 9.x, verifique se o pacote resource-agents-sap-hana instalado é a versão 0.162.3-5 ou posterior.
[A] Instale o HANA
system replication hooks. A configuração para os ganchos de replicação precisa ser instalada em ambos os nós do banco de dados HANA.Pare o HANA em ambos os nós. Executar como <sid>adm.
sapcontrol -nr 03 -function StopSystemAjuste
global.iniem cada nó do cluster.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/srHook execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR/srHook execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Se você apontar o parâmetro
pathpara o local padrão/usr/share/SAPHanaSR/srHook, o código de gancho do Python será atualizado automaticamente por meio de atualizações do sistema operacional ou atualizações de pacote. O HANA usa as atualizações do código de gancho quando for reiniciado na próxima reinicialização. Com um caminho próprio opcional como/hana/shared/myHookso , você pode desacoplar as atualizações do sistema operacional da versão de gancho que o HANA usará.Você pode ajustar o comportamento do
ChkSrvgancho usando oaction_on_lostparâmetro. Os valores válidos são [ignore| |stopkill].[A] O cluster requer
sudoersconfiguração em cada nó de cluster para <sid>adm. Neste exemplo, isso é conseguido através da criação de um novo ficheiro. Use ovisudocomando para editar o20-saphanaarquivo drop-in comoroot.sudo visudo -f /etc/sudoers.d/20-saphanaInsira as seguintes linhas e guarde:
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] Inicie o SAP HANA em ambos os nós. Executar como <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Verifique a instalação do gancho SRHanaSR. Execute como <sid>adm no site de replicação do sistema HANA ativo.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK[1] Verifique a instalação do gancho ChkSrv. Execute como <sid>adm no site de replicação do sistema HANA ativo.
cdtrace tail -20 nameserver_chksrv.trc
Para obter mais informações sobre a implementação dos ganchos do SAP HANA, consulte Ativando o gancho SAP HANA srConnectionChanged() e Ativando o gancho SAP HANA srServiceStateChanged() para a ação de falha do processo hdbindexserver (opcional).
Criar recursos de cluster do SAP HANA
Crie a topologia HANA. Execute os seguintes comandos em um dos nós de cluster do Pacemaker. Ao longo destas instruções, certifique-se de substituir o número da instância, o ID do sistema HANA, os endereços IP e os nomes do sistema, quando apropriado.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
Em seguida, crie os recursos HANA.
Nota
Este artigo contém referências a um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
Se você estiver criando um cluster no RHEL 7.x, use os seguintes comandos:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
Se você estiver criando um cluster no RHEL 8.x/9.x, use os seguintes comandos:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
Para configurar priority-fencing-delay para o SAP HANA (aplicável somente a partir do pacemaker-2.0.4-6.el8 ou superior), os comandos a seguir precisam ser executados.
Nota
Se você tiver um cluster de dois nós, poderá configurar a propriedade do priority-fencing-delay cluster. Esta propriedade introduz um atraso na vedação de um nó que tem maior prioridade total de recursos quando ocorre um cenário de divisão cerebral. Para obter mais informações, consulte O Pacemaker pode cercar o nó do cluster com o menor número de recursos em execução?.
A propriedade priority-fencing-delay é aplicável para a versão pacemaker-2.0.4-6.el8 ou superior. Se estiver a configurar priority-fencing-delay um cluster existente, certifique-se de que desdefine a pcmk_delay_max opção no dispositivo de esgrima.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Importante
É uma boa ideia definir AUTOMATED_REGISTER como false, enquanto você está executando testes de failover, para evitar que uma instância primária com falha se registre automaticamente como secundária. Após o teste, como prática recomendada, defina AUTOMATED_REGISTER para que, após a aquisição, a true replicação do sistema possa ser retomada automaticamente.
Verifique se o status do cluster está correto e se todos os recursos foram iniciados. O nó em que os recursos estão sendo executados não é importante.
Nota
Os tempos limite na configuração anterior são apenas exemplos e podem precisar ser adaptados à configuração específica do HANA. Por exemplo, talvez seja necessário aumentar o tempo limite de inicialização, se demorar mais para iniciar o banco de dados do SAP HANA.
Use o comando sudo pcs status para verificar o estado dos recursos de cluster criados:
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Configurar a replicação do sistema ativo/habilitado para leitura do HANA no cluster do Pacemaker
A partir do SAP HANA 2.0 SPS 01, o SAP permite configurações ativas/habilitadas para leitura para o SAP HANA System Replication, onde os sistemas secundários do SAP HANA System Replication podem ser usados ativamente para cargas de trabalho de leitura intensa.
Para suportar essa configuração em um cluster, é necessário um segundo endereço IP virtual, que permite que os clientes acessem o banco de dados secundário SAP HANA habilitado para leitura. Para garantir que o local de replicação secundária ainda possa ser acessado após a ocorrência de uma aquisição, o cluster precisa mover o endereço IP virtual com o recurso SAPHana secundário.
Esta seção descreve as outras etapas necessárias para gerenciar a replicação do sistema ativa/habilitada para leitura do HANA em um cluster Red Hat HA com um segundo IP virtual.
Antes de prosseguir, certifique-se de ter configurado totalmente o cluster Red Hat HA gerenciando um banco de dados SAP HANA, conforme descrito nos segmentos anteriores da documentação.
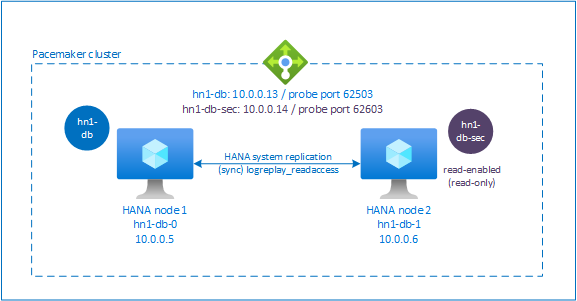
Configuração adicional no Azure Load Balancer para configuração ativa/habilitada para leitura
Para prosseguir com mais etapas sobre o provisionamento de um segundo IP virtual, verifique se você configurou o Balanceador de Carga do Azure conforme descrito na seção Implantar VMs Linux manualmente por meio do portal do Azure.
Para um balanceador de carga padrão , siga estas etapas no mesmo balanceador de carga que você criou em uma seção anterior.
a. Crie um segundo pool de IP front-end:
- Abra o balanceador de carga, selecione pool de IP frontend e selecione Adicionar.
- Digite o nome do segundo pool de IP front-end (por exemplo, hana-secondaryIP).
- Defina Atribuição como Estático e insira o endereço IP (por exemplo, 10.0.0.14).
- Selecione OK.
- Depois que o novo pool de IP front-end for criado, observe o endereço IP do pool.
b. Crie uma sonda de integridade:
- Abra o balanceador de carga, selecione testes de integridade e selecione Adicionar.
- Digite o nome da nova sonda de integridade (por exemplo, hana-secondaryhp).
- Selecione TCP como o protocolo e a porta 62603. Mantenha o valor Intervalo definido como 5 e o valor do limite Não íntegro definido como 2.
- Selecione OK.
c. Crie as regras de balanceamento de carga:
- Abra o balanceador de carga, selecione regras de balanceamento de carga e selecione Adicionar.
- Insira o nome da nova regra do balanceador de carga (por exemplo, hana-secondarylb).
- Selecione o endereço IP front-end, o pool de back-end e a sonda de integridade que você criou anteriormente (por exemplo, hana-secondaryIP, hana-backend e hana-secondaryhp).
- Selecione Portas HA.
- Certifique-se de ativar o IP flutuante.
- Selecione OK.
Configurar a replicação do sistema ativa/habilitada para leitura do HANA
As etapas para configurar a replicação do sistema HANA são descritas na seção Configurar a replicação do sistema SAP HANA 2.0. Se você estiver implantando um cenário secundário habilitado para leitura enquanto estiver configurando a replicação do sistema no segundo nó, execute o seguinte comando como hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
Adicionar um recurso de endereço IP virtual secundário para uma configuração ativa/habilitada para leitura
O segundo IP virtual e a restrição de colocation apropriada podem ser configurados com os seguintes comandos:
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
# Set the priority to primary IPaddr2 and azure-lb resource if priority-fencing-delay is configured
sudo pcs resource update vip_HN1_03 meta priority=5
sudo pcs resource update nc_HN1_03 meta priority=5
pcs property set maintenance-mode=false
Verifique se o status do cluster está correto e se todos os recursos foram iniciados. O segundo IP virtual é executado no site secundário juntamente com o recurso secundário SAPHana.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Na próxima seção, você pode encontrar o conjunto típico de testes de failover a serem executados.
Esteja ciente do segundo comportamento de IP virtual enquanto estiver testando um cluster HANA configurado com secundário habilitado para leitura:
Quando você migra o recurso de cluster SAPHana_HN1_03 para o site secundário hn1-db-1, o segundo IP virtual continua a ser executado no mesmo site hn1-db-1. Se você definiu
AUTOMATED_REGISTER="true"para o recurso e a replicação do sistema HANA é registrada automaticamente em hn1-db-0, seu segundo IP virtual também é movido para hn1-db-0.Ao testar uma falha de servidor, os segundos recursos IP virtuais (secvip_HN1_03) e o recurso de porta do Balanceador de Carga do Azure (secnc_HN1_03) são executados no servidor primário juntamente com os recursos IP virtuais primários. Assim, até o momento em que o servidor secundário estiver inativo, os aplicativos conectados ao banco de dados HANA habilitado para leitura se conectam ao banco de dados HANA primário. O comportamento é esperado porque você não deseja que os aplicativos conectados ao banco de dados HANA habilitado para leitura fiquem inacessíveis até o momento em que o servidor secundário estiver indisponível.
Durante o failover e fallback do segundo endereço IP virtual, as conexões existentes em aplicativos que usam o segundo IP virtual para se conectar ao banco de dados HANA podem ser interrompidas.
A configuração maximiza o tempo que o segundo recurso IP virtual é atribuído a um nó onde uma instância SAP HANA íntegra está em execução.
Testar a configuração do cluster
Esta seção descreve como você pode testar sua configuração. Antes de iniciar um teste, certifique-se de que o Pacemaker não tem nenhuma ação com falha (via status de pcs), não há restrições de localização inesperadas (por exemplo, sobras de um teste de migração) e que o HANA está em estado de sincronização, por exemplo, com systemReplicationStatus.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
Testar a migração
Estado do recurso antes de iniciar o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Você pode migrar o nó principal do SAP HANA executando o seguinte comando como root:
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
O cluster migraria o nó principal do SAP HANA e o grupo que contém o endereço IP virtual para .hn1-db-1
Depois que a migração é feita, a sudo pcs status saída se parece com:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Com AUTOMATED_REGISTER="false"o , o cluster não reiniciaria o banco de dados HANA com falha nem o registraria no novo primário no hn1-db-0. Nesse caso, configure a instância HANA como secundária executando estes comandos, como hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
A migração cria restrições de local que precisam ser excluídas novamente. Execute o seguinte comando como root, ou via sudo:
pcs resource clear SAPHana_HN1_03-master
Monitore o estado do recurso HANA usando pcs status. Depois que o HANA é iniciado, hn1-db-0a saída deve se parecer com:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Bloquear comunicação de rede
Estado do recurso antes de iniciar o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Execute a regra de firewall para bloquear a comunicação em um dos nós.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Quando os nós de cluster não conseguem se comunicar uns com os outros, há um risco de um cenário de cérebro dividido. Em tais situações, os nós de cluster tentam cercar uns aos outros simultaneamente, resultando em uma corrida de cerca. Para evitar tal situação, recomendamos que você defina a propriedade priority-fencing-delay na configuração de cluster (aplicável apenas para pacemaker-2.0.4-6.el8 ou superior).
Ao habilitar a priority-fencing-delay propriedade, o cluster introduz um atraso na ação de esgrima especificamente no nó que hospeda o recurso mestre HANA, permitindo que o nó ganhe a corrida de cerca.
Execute o seguinte comando para excluir a regra de firewall:
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testar o agente de esgrima do Azure
Nota
Este artigo contém referências a um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
Estado do recurso antes de iniciar o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Você pode testar a configuração do agente de esgrima do Azure desativando a interface de rede no nó onde o SAP HANA está sendo executado como Master. Para obter uma descrição sobre como simular uma falha de rede, consulte o artigo 79523 da Base de Conhecimento Red Hat.
Neste exemplo, usamos o net_breaker script como root para bloquear todo o acesso à rede:
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
A VM agora deve reiniciar ou parar, dependendo da configuração do cluster.
Se você definir a stonith-action configuração como off, a VM será interrompida e os recursos serão migrados para a VM em execução.
Depois de iniciar a VM novamente, o recurso SAP HANA não será iniciado como secundário se você definir AUTOMATED_REGISTER="false". Nesse caso, configure a instância HANA como secundária executando este comando como o usuário hn1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Volte para o root e limpe o estado com falha:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Estado do recurso após o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Testar um failover manual
Estado do recurso antes de iniciar o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Você pode testar um failover manual interrompendo o hn1-db-0 cluster no nó, como root:
pcs cluster stop
Após o failover, você pode iniciar o cluster novamente. Se você definir AUTOMATED_REGISTER="false", o recurso SAP HANA no hn1-db-0 nó não será iniciado como secundário. Nesse caso, configure a instância HANA como secundária executando este comando como root:
pcs cluster start
Execute o seguinte como hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Então como raiz:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Estado do recurso após o teste:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1