Tutorial: Índice de várias fontes de dados usando o SDK do .NET
O Azure AI Search pode importar, analisar e indexar dados de várias fontes de dados em um único índice de pesquisa consolidado.
Este tutorial em C# usa a biblioteca de cliente Azure.Search.Documents no SDK do Azure para .NET para indexar dados de hotel de exemplo de uma instância do Azure Cosmos DB e mescla isso com detalhes de quarto de hotel extraídos de documentos do Armazenamento de Blob do Azure. O resultado é um índice de pesquisa de hotéis combinado contendo documentos de hotéis, com quartos como tipos de dados complexos.
Neste tutorial, você executará as seguintes tarefas:
- Carregue dados de exemplo e crie fontes de dados
- Identificar a chave do documento
- Definir e criar o índice
- Indexar dados de hotel do Azure Cosmos DB
- Mesclar dados de quarto de hotel do armazenamento de blob
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Descrição geral
Este tutorial usa Azure.Search.Documents para criar e executar vários indexadores. Neste tutorial, você configurará duas fontes de dados do Azure para poder configurar um indexador que extrai de ambas para preencher um único índice de pesquisa. Os dois conjuntos de dados devem ter um valor em comum para dar suporte à mesclagem. Neste exemplo, esse campo é um ID. Desde que haja um campo em comum para dar suporte ao mapeamento, um indexador pode mesclar dados de recursos diferentes: dados estruturados do SQL do Azure, dados não estruturados do armazenamento de Blob ou qualquer combinação de fontes de dados com suporte no Azure.
Uma versão concluída do código neste tutorial pode ser encontrada no seguinte projeto:
Pré-requisitos
- Azure Cosmos DB para NoSQL
- Armazenamento do Azure
- Visual Studio
- Azure AI Search (versão 11.x) pacote NuGet
- Azure AI Search
Nota
Você pode usar um serviço de pesquisa gratuito para este tutorial. A camada gratuita limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um de cada. Antes de começar, certifique-se de que tem espaço no seu serviço para aceitar os novos recursos.
1 - Criar serviços
Este tutorial usa o Azure AI Search para indexação e consultas, o Azure Cosmos DB para um conjunto de dados e o Armazenamento de Blob do Azure para o segundo conjunto de dados.
Se possível, crie todos os serviços na mesma região e grupo de recursos para proximidade e capacidade de gerenciamento. Na prática, seus serviços podem estar em qualquer região.
Este exemplo usa dois pequenos conjuntos de dados que descrevem sete hotéis fictícios. Um conjunto descreve os próprios hotéis e será carregado em um banco de dados do Azure Cosmos DB. O outro conjunto contém detalhes do quarto de hotel e é fornecido como sete arquivos JSON separados a serem carregados no Armazenamento de Blobs do Azure.
Comece com o Azure Cosmos DB
Entre no portal do Azure e navegue pela página Visão geral da conta do Azure Cosmos DB.
Selecione Data Explorer e, em seguida, selecione Novo Banco de Dados.

Digite o nome hotel-rooms-db. Aceite os valores padrão para as configurações restantes.
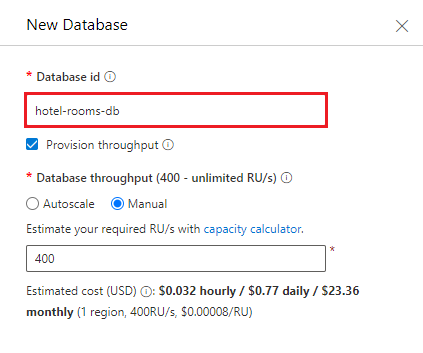
Criar um novo contentor. Use o banco de dados existente que você acabou de criar. Insira hotéis para o nome do contêiner e use /HotelId para a chave de partição.

Selecione Itens em hotéis e, em seguida, selecione Carregar item na barra de comandos. Navegue até e selecione o arquivo cosmosdb/HotelsDataSubset_CosmosDb.json na pasta do projeto.
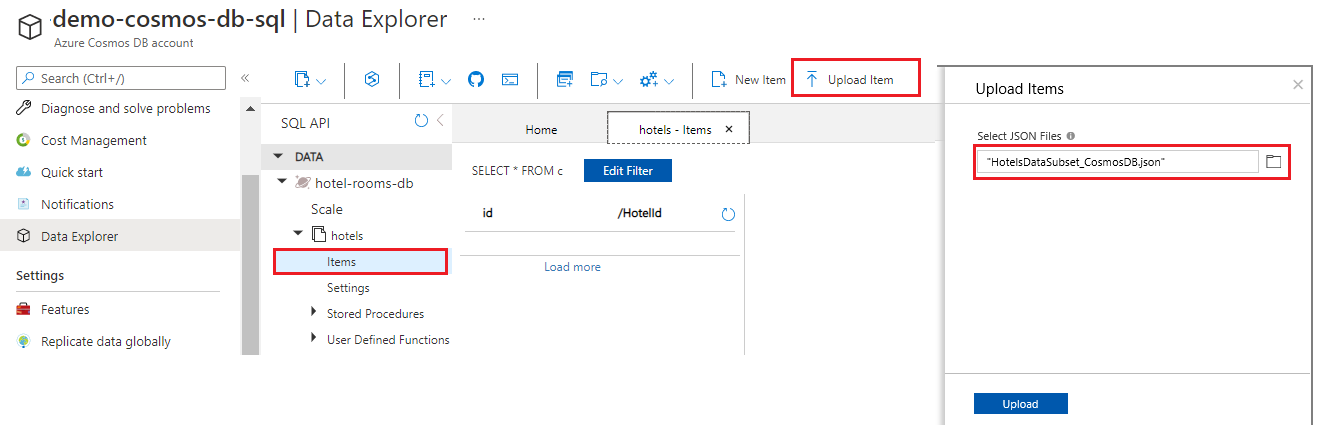
Use o botão Atualizar para atualizar sua exibição dos itens da coleção de hotéis. Você verá sete novos documentos de banco de dados listados.
Copie uma cadeia de conexão da página Teclas para o Bloco de Notas. Você precisará desse valor para appsettings.json em uma etapa posterior. Se você não usou o nome de banco de dados sugerido "hotel-rooms-db", copie o nome do banco de dados também.
Armazenamento de Blobs do Azure
Entre no portal do Azure, navegue até sua conta de armazenamento do Azure, selecione Blobs e selecione + Contêiner.
Crie um contêiner de blob chamado hotel-rooms para armazenar os arquivos JSON de quarto de hotel de exemplo. Você pode definir o Nível de Acesso Público para qualquer um de seus valores válidos.
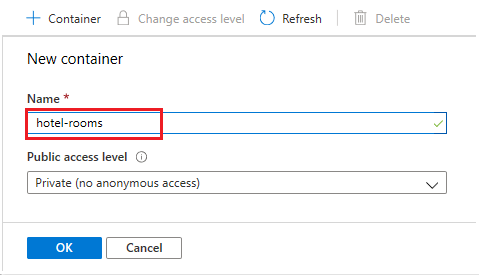
Depois que o contêiner for criado, abra-o e selecione Carregar na barra de comandos. Navegue até a pasta que contém os arquivos de exemplo. Selecione todos eles e, em seguida, selecione Carregar.
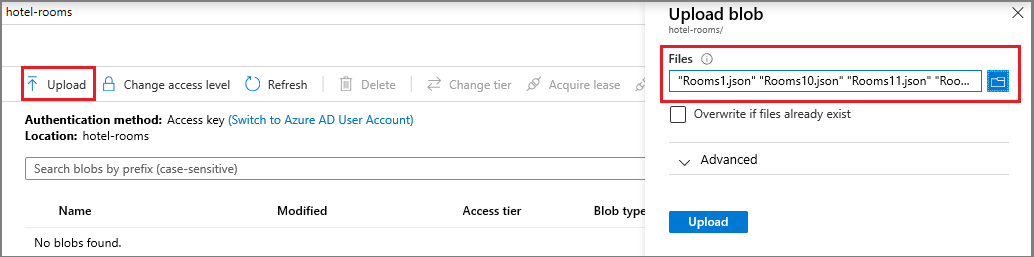
Copie o nome da conta de armazenamento e uma cadeia de conexão da página Teclas de Acesso para o Bloco de Notas . Você precisará de ambos os valores para appsettings.json em uma etapa posterior.
Pesquisa de IA do Azure
O terceiro componente é o Azure AI Search, que você pode criar no portal ou encontrar um serviço de pesquisa existente em seus recursos do Azure.
Copiar uma chave de api de administrador e URL para o Azure AI Search
Para se autenticar no seu serviço de pesquisa, precisará do URL do serviço e de uma chave de acesso.
Entre no portal do Azure e, na página Visão geral do serviço de pesquisa, obtenha a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Teclas de Configurações>, obtenha uma chave de administrador para obter todos os direitos no serviço. Há duas chaves de administrador intercambiáveis, fornecidas para continuidade de negócios no caso de você precisar rolar uma. Você pode usar a chave primária ou secundária em solicitações para adicionar, modificar e excluir objetos.
Ter uma chave válida estabelece fidedignidade, numa base por pedido, entre a aplicação a enviar o pedido e o serviço que o processa.
2 - Configure o seu ambiente
Inicie o Visual Studio e, no menu Ferramentas , selecione Gerenciador de Pacotes NuGet e, em seguida, Gerenciar Pacotes NuGet para Solução....
Na guia Procurar, localize e instale Azure.Search.Documents (versão 11.0 ou posterior).
Procure os pacotes Microsoft.Extensions.Configuration e Microsoft.Extensions.Configuration.Json NuGet e instale-os também.
Abra o arquivo de solução /v11/AzureSearchMultipleDataSources.sln.
No Gerenciador de Soluções, edite o arquivo appsettings.json para adicionar informações de conexão.
{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
As duas primeiras entradas são o URL e as chaves de administração de um serviço de pesquisa. Use o ponto de extremidade completo, por exemplo: https://mydemo.search.windows.net.
As próximas entradas especificam nomes de conta e informações de cadeia de conexão para o Armazenamento de Blob do Azure e as fontes de dados do Azure Cosmos DB.
3 - Mapear campos-chave
A mesclagem de conteúdo requer que ambos os fluxos de dados estejam direcionando os mesmos documentos no índice de pesquisa.
No Azure AI Search, o campo chave identifica exclusivamente cada documento. Cada índice de pesquisa deve ter exatamente um campo chave do tipo Edm.String. Esse campo-chave deve estar presente para cada documento em uma fonte de dados adicionada ao índice. (Na verdade, é o único campo obrigatório.)
Ao indexar dados de várias fontes de dados, verifique se cada linha ou documento de entrada contém uma chave de documento comum para mesclar dados de dois documentos de origem fisicamente distintos em um novo documento de pesquisa no índice combinado.
Muitas vezes, requer algum planejamento inicial para identificar uma chave de documento significativa para seu índice e certificar-se de que ela existe em ambas as fontes de dados. Nesta demonstração, a HotelId chave para cada hotel no Azure Cosmos DB também está presente nas salas de blobs JSON no armazenamento de Blob.
Os indexadores do Azure AI Search podem usar mapeamentos de campo para renomear e até mesmo reformatar campos de dados durante o processo de indexação, para que os dados de origem possam ser direcionados para o campo de índice correto. Por exemplo, no Azure Cosmos DB, o identificador de hotel é chamado HotelIdde . Mas nos arquivos de blob JSON para os quartos de hotel, o identificador do hotel é nomeado Id. O programa lida com essa discrepância mapeando o Id campo dos blobs para o HotelId campo chave no indexador.
Nota
Na maioria dos casos, as chaves de documento geradas automaticamente, como as criadas por padrão por alguns indexadores, não são boas chaves de documento para índices combinados. Em geral, você desejará usar um valor de chave significativo e exclusivo que já existe ou pode ser facilmente adicionado às suas fontes de dados.
4 - Explore o código
Uma vez que os dados e as definições de configuração estejam em vigor, o programa de exemplo em /v11/AzureSearchMultipleDataSources.sln deve estar pronto para ser compilado e executado.
Este aplicativo de console C#/.NET simples executa as seguintes tarefas:
- Cria um novo índice com base na estrutura de dados da classe C# Hotel (que também faz referência às classes Address e Room).
- Cria uma nova fonte de dados e um indexador que mapeia dados do Azure Cosmos DB para campos de índice. Estes são ambos os objetos no Azure AI Search.
- Executa o indexador para carregar dados do Hotel do Azure Cosmos DB.
- Cria uma segunda fonte de dados e um indexador que mapeia dados de blob JSON para campos de índice.
- Executa o segundo indexador para carregar dados de salas do armazenamento de Blob.
Antes de executar o programa, reserve um minuto para estudar o código e as definições de índice e indexador para este exemplo. O código relevante está em dois ficheiros:
- Hotel.cs contém o esquema que define o índice
- Program.cs contém funções que criam o índice do Azure AI Search, fontes de dados e indexadores e carregam os resultados combinados no índice.
Criar um índice
Este programa de exemplo usa CreateIndexAsync para definir e criar um índice do Azure AI Search. Ele aproveita a classe FieldBuilder para gerar uma estrutura de índice a partir de uma classe de modelo de dados C#.
O modelo de dados é definido pela classe Hotel, que também contém referências às classes Address e Room. O FieldBuilder detalha várias definições de classe para gerar uma estrutura de dados complexa para o índice. As tags de metadados são usadas para definir os atributos de cada campo, como se é pesquisável ou classificável.
O programa excluirá qualquer índice existente com o mesmo nome antes de criar o novo, caso você queira executar este exemplo mais de uma vez.
Os seguintes trechos do arquivo Hotel.cs mostram campos únicos, seguidos por uma referência a outra classe de modelo de dados, Room[], que, por sua vez, é definida em Room.cs arquivo (não mostrado).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
No arquivo Program.cs, um SearchIndex é definido com um nome e uma coleção de campos gerados pelo FieldBuilder.Build método e, em seguida, criado da seguinte maneira:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Criar fonte de dados e indexador do Azure Cosmos DB
Em seguida, o programa principal inclui lógica para criar a fonte de dados do Azure Cosmos DB para os dados de hotéis.
Primeiro, ele concatena o nome do banco de dados do Azure Cosmos DB com a cadeia de conexão. Em seguida, ele define um objeto SearchIndexerDataSourceConnection .
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Depois que a fonte de dados é criada, o programa configura um indexador do Azure Cosmos DB chamado hotel-rooms-cosmos-indexer.
O programa atualizará todos os indexadores existentes com o mesmo nome, substituindo o indexador existente pelo conteúdo do código acima. Ele também inclui ações de redefinição e execução, caso você queira executar este exemplo mais de uma vez.
O exemplo a seguir define um agendamento para o indexador, para que ele seja executado uma vez por dia. Você pode remover a propriedade schedule dessa chamada se não quiser que o indexador seja executado automaticamente novamente no futuro.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Este exemplo inclui um bloco try-catch simples para relatar quaisquer erros que possam ocorrer durante a execução.
Depois que o indexador do Azure Cosmos DB for executado, o índice de pesquisa conterá um conjunto completo de documentos de hotel de exemplo. No entanto, o campo de quartos para cada hotel será uma matriz vazia, já que a fonte de dados do Azure Cosmos DB omite detalhes da sala. Em seguida, o programa extrairá do armazenamento de Blob para carregar e mesclar os dados da sala.
Criar indexador e fonte de dados de armazenamento de Blob
Para obter os detalhes da sala, o programa primeiro configura uma fonte de dados de armazenamento de Blob para fazer referência a um conjunto de arquivos de blob JSON individuais.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Depois que a fonte de dados é criada, o programa configura um indexador de blob chamado hotel-rooms-blob-indexer, conforme mostrado abaixo.
Os blobs JSON contêm um campo chave chamado Id em vez de HotelId. O código usa a FieldMapping classe para dizer ao indexador para direcionar o valor do Id campo para a chave do HotelId documento no índice.
Os indexadores de armazenamento de Blob podem usar IndexingParameters para especificar um modo de análise. Você deve definir diferentes modos de análise, dependendo se os blobs representam um único documento ou vários documentos dentro do mesmo blob. Neste exemplo, cada blob representa um único documento JSON, portanto, o código usa o json modo de análise. Para obter mais informações sobre parâmetros de análise de indexador para blobs JSON, consulte Blobs JSON de índice.
Este exemplo define uma agenda para o indexador, para que ele seja executado uma vez por dia. Você pode remover a propriedade schedule dessa chamada se não quiser que o indexador seja executado automaticamente novamente no futuro.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Como o índice já foi preenchido com dados de hotel do banco de dados do Azure Cosmos DB, o indexador de blob atualiza os documentos existentes no índice e adiciona os detalhes da sala.
Nota
Se você tiver os mesmos campos não-chave em ambas as fontes de dados e os dados dentro desses campos não corresponderem, o índice conterá os valores de qualquer indexador executado mais recentemente. No nosso exemplo, ambas as fontes de dados contêm um campo HotelName . Se, por algum motivo, os dados neste campo forem diferentes, para documentos com o mesmo valor de chave, os dados HotelName da fonte de dados indexada mais recentemente serão o valor armazenado no índice.
5 - Pesquisa
Você pode explorar o índice de pesquisa preenchido após a execução do programa, usando o explorador de pesquisa no portal.
No portal do Azure, abra a página Visão geral do serviço de pesquisa e localize o índice de exemplo de quartos de hotel na lista Índices.

Selecione o índice de amostra de quartos de hotel na lista. Você verá uma interface do Search Explorer para o índice. Insira uma consulta para um termo como "Luxo". Você deve ver pelo menos um documento nos resultados, e este documento deve mostrar uma lista de objetos de sala em sua matriz de salas.
Repor e executar novamente
Nos estágios experimentais iniciais de desenvolvimento, a abordagem mais prática para iteração de design é excluir os objetos da Pesquisa de IA do Azure e permitir que seu código os reconstrua. Os nomes dos recursos são exclusivos. Quando elimina um objeto, pode recriá-lo com o mesmo nome.
O código de exemplo verifica se há objetos existentes e os exclui ou atualiza para que você possa executar novamente o programa.
Você também pode usar o portal para excluir índices, indexadores e fontes de dados.
Clean up resources (Limpar recursos)
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos de que já não necessita. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode encontrar e gerenciar recursos no portal, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
Próximos passos
Agora que você está familiarizado com o conceito de ingestão de dados de várias fontes, vamos examinar mais de perto a configuração do indexador, começando com o Azure Cosmos DB.