Quer saber mais sobre o Service Fabric?
O Azure Service Fabric é uma plataforma de sistemas distribuídos que facilita o empacotamento, a implementação e a gestão de microsserviços dimensionáveis e fiáveis. No entanto, o Service Fabric tem uma grande área de superfície e há muito a aprender. Este artigo fornece uma sinopse do Service Fabric e descreve os principais conceitos, modelos de programação, ciclo de vida do aplicativo, testes, clusters e monitoramento de integridade. Leia Visão geral e O que são microsserviços? para obter uma introdução e como o Service Fabric pode ser usado para criar microsserviços. Este artigo não contém uma lista de conteúdo abrangente, mas contém links para artigos de visão geral e introdução para cada área do Service Fabric.
Conceitos-chave
A terminologia do Service Fabric, o modelo de aplicativo e os modelos de programação suportados fornecem mais conceitos e descrições, mas aqui estão as noções básicas.
- Cluster do Service Fabric: verifique este link para obter um vídeo de treinamento para obter uma introdução à arquitetura do Service Fabric e seus principais conceitos e explorar muitos recursos do Service Fabric.
- Conceitos de tempo de execução: verifique este link para obter um vídeo de treinamento para entender os conceitos de tempo de execução e as práticas recomendadas do Service Fabric.
- Conceitos de tipo de design: verifique neste link um vídeo de treinamento para entender o aplicativo, o empacotamento e a implantação, a principal terminologia, abstrações e conceitos do Service Fabric.
Tempo de design: tipo de serviço, pacote de serviço e manifesto, tipo de aplicativo, pacote de aplicativo e manifesto
Um tipo de serviço é o nome/versão atribuído aos pacotes de código, pacotes de dados e pacotes de configuração de um serviço. Isso é definido em um arquivo ServiceManifest.xml. O tipo de serviço é composto de código executável e definições de configuração de serviço, que são carregados em tempo de execução, e dados estáticos que são consumidos pelo serviço.
Um pacote de serviço é um diretório de disco que contém o arquivo ServiceManifest.xml do tipo de serviço, que faz referência ao código, dados estáticos e pacotes de configuração para o tipo de serviço. Por exemplo, um pacote de serviço pode se referir ao código, dados estáticos e pacotes de configuração que compõem um serviço de banco de dados.
Um tipo de aplicativo é o nome/versão atribuído a uma coleção de tipos de serviço. Isso é definido em um arquivo ApplicationManifest.xml.
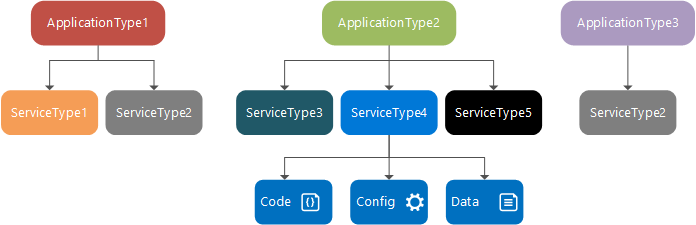
O pacote de aplicativo é um diretório de disco que contém o arquivo ApplicationManifest.xml do tipo de aplicativo, que faz referência aos pacotes de serviço para cada tipo de serviço que compõe o tipo de aplicativo. Por exemplo, um pacote de aplicativo para um tipo de aplicativo de email pode conter referências a um pacote de serviço de fila, um pacote de serviço de front-end e um pacote de serviço de banco de dados.
Os arquivos no diretório do pacote de aplicativos são copiados para o armazenamento de imagens do cluster do Service Fabric. Em seguida, você pode criar um aplicativo nomeado a partir desse tipo de aplicativo, que é executado dentro do cluster. Depois de criar um aplicativo nomeado, você pode criar um serviço nomeado a partir de um dos tipos de serviço do tipo de aplicativo.
Tempo de execução: clusters e nós, aplicativos nomeados, serviços nomeados, partições e réplicas
Um cluster do Service Fabric é um conjunto ligado à rede de máquinas virtuais ou físicas, no qual os microsserviços são implementados e geridos. Os clusters podem ser dimensionados para milhares de máquinas.
Uma máquina ou VM que faça parte de um cluster é denominada um nó. É atribuído um nome de nó (uma cadeia) a cada nó. Os nós têm características, como as propriedades de colocação. Cada máquina ou VM tem um serviço de inicialização automática do Windows, , que começa a ser executado na inicialização e, em seguida, FabricHost.exeinicia dois executáveis: Fabric.exe e FabricGateway.exe. Esses dois executáveis compõem o nó. Para cenários de desenvolvimento ou teste, você pode hospedar vários nós em uma única máquina ou VM executando várias instâncias de Fabric.exe e FabricGateway.exe.
Um aplicativo nomeado é uma coleção de serviços nomeados que executa uma determinada função ou funções. Um serviço executa uma função completa e independente (pode iniciar e executar independentemente de outros serviços) e é composto por código, configuração e dados. Depois que um pacote de aplicativo é copiado para o armazenamento de imagens, você cria uma instância do aplicativo dentro do cluster especificando o tipo de aplicativo do pacote de aplicativo (usando seu nome/versão). A cada instância de tipo de aplicativo é atribuído um nome de URI que se parece com fabric:/MyNamedApp. Dentro de um cluster, você pode criar vários aplicativos nomeados a partir de um único tipo de aplicativo. Você também pode criar aplicativos nomeados de diferentes tipos de aplicativos. Cada aplicativo nomeado é gerenciado e versionado independentemente.
Depois de criar um aplicativo nomeado, você pode criar uma instância de um de seus tipos de serviço (um serviço nomeado) dentro do cluster especificando o tipo de serviço (usando seu nome/versão). A cada instância de tipo de serviço é atribuído um nome de URI com escopo no URI do aplicativo nomeado. Por exemplo, se você criar um serviço nomeado "MyDatabase" dentro de um aplicativo chamado "MyNamedApp", o URI será semelhante a: fabric:/MyNamedApp/MyDatabase. Dentro de um aplicativo nomeado, você pode criar um ou mais serviços nomeados. Cada serviço nomeado pode ter seu próprio esquema de partição e contagens de instância/réplica.
Existem dois tipos de serviços: apátridas e com estado. Os serviços sem estado não armazenam o estado dentro do serviço. Os serviços sem estado não têm armazenamento persistente ou armazenam o estado persistente em um serviço de armazenamento externo, como o Armazenamento do Azure, o Banco de Dados SQL do Azure ou o Azure Cosmos DB. Um serviço com estado armazena o estado dentro do serviço e usa modelos de programação de Coleções Confiáveis ou Atores Confiáveis para gerenciar o estado.
Ao criar um serviço nomeado, você especifica um esquema de partição. Serviços com grandes quantidades de estado dividem os dados entre partições. Cada partição é responsável por uma parte do estado completo do serviço, que está espalhada pelos nós do cluster.
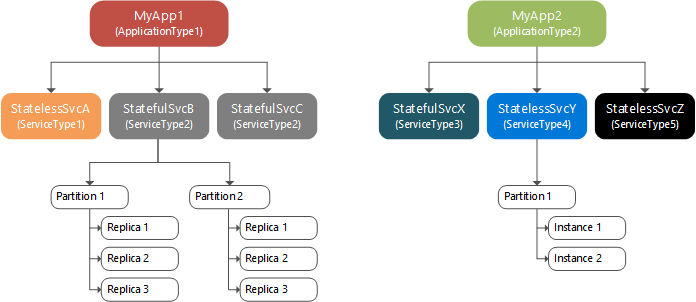
O diagrama a seguir mostra a relação entre aplicativos e instâncias de serviço, partições e réplicas.
Particionamento, dimensionamento e disponibilidade
O particionamento não é exclusivo do Service Fabric. Uma forma bem conhecida de particionamento é o particionamento de dados, ou fragmentação. Serviços com estado com grandes quantidades de estado dividem os dados entre partições. Cada partição é responsável por uma parte do estado completo do serviço.
As réplicas de cada partição estão espalhadas pelos nós do cluster, o que permite que o estado do serviço nomeado seja dimensionado. À medida que as necessidades de dados crescem, as partições crescem e o Service Fabric reequilibra as partições entre nós para fazer uso eficiente dos recursos de hardware. Se você adicionar novos nós ao cluster, o Service Fabric reequilibrará as réplicas de partição no número maior de nós. O desempenho geral do aplicativo melhora e a contenção para acesso à memória diminui. Se os nós no cluster não estiverem sendo usados de forma eficiente, você poderá diminuir o número de nós no cluster. O Service Fabric novamente reequilibra as réplicas de partição no número reduzido de nós para fazer melhor uso do hardware em cada nó.
Dentro de uma partição, os serviços nomeados sem estado têm instâncias, enquanto os serviços nomeados com estado têm réplicas. Normalmente, os serviços nomeados sem estado têm apenas uma partição, uma vez que não têm estado interno, embora haja exceções. As instâncias de partição fornecem disponibilidade. Se uma instância falhar, outras instâncias continuarão a operar normalmente e, em seguida, o Service Fabric criará uma nova instância. Os serviços nomeados com estado mantêm seu estado dentro das réplicas e cada partição tem seu próprio conjunto de réplicas. As operações de leitura e gravação são executadas em uma réplica (chamada de Principal). As alterações no estado das operações de gravação são replicadas para várias outras réplicas (chamadas Secundárias Ativas). Se uma réplica falhar, o Service Fabric criará uma nova réplica a partir das réplicas existentes.
Microsserviços com e sem monitorização de estado para o Service Fabric
O Service Fabric permite-lhe criar aplicações que consistem em microsserviços ou contentores. Os microsserviços sem estado (como gateways de protocolos e proxies Web) não mantêm um estado mutável fora dos pedidos nem na respetiva resposta do serviço. As funções de trabalho dos Serviços Cloud do Azure são um exemplo de serviço sem estado. Os microsserviços com estado (como contas de utilizador, bases de dados, dispositivos, carrinhos de compras e filas) mantêm um estado mutável e autoritativo para lá do pedido e da respetiva resposta. As aplicações à escala da cloud dos nossos dias são compostas por uma combinação de microsserviços com e sem estado.
Uma diferenciação importante com o Service Fabric é seu forte foco na criação de serviços stateful, seja com os modelos de programação integrados ou com serviços stateful em contêineres. Os cenários de aplicação descrevem os cenários em que são utilizados os serviços com estado.
Por que ter microsserviços stateful junto com os apátridas? As duas principais razões são:
- Você pode criar serviços OLTP (processamento de transações online) de alta taxa de transferência, baixa latência e tolerante a falhas, mantendo o código e os dados próximos na mesma máquina. Alguns exemplos são vitrines interativas, pesquisa, sistemas de Internet das Coisas (IoT), sistemas de negociação, processamento de cartões de crédito e sistemas de deteção de fraudes e gerenciamento de registros pessoais.
- Você pode simplificar o design do aplicativo. Os microsserviços com monitoração de estado eliminam a necessidade de filas e caches adicionais, que são tradicionalmente necessários para atender aos requisitos de disponibilidade e latência de um aplicativo puramente sem monitoração de estado. Os serviços com monitoração de estado são naturalmente de alta disponibilidade e baixa latência, o que reduz o número de peças móveis a serem gerenciadas em seu aplicativo como um todo.
Modelos de programação suportados
O Service Fabric oferece várias maneiras de escrever e gerenciar seus serviços. Os serviços podem usar as APIs do Service Fabric para aproveitar ao máximo os recursos e as estruturas de aplicativos da plataforma. Os serviços também podem ser qualquer programa executável compilado escrito em qualquer idioma e hospedado em um cluster do Service Fabric. Para obter mais informações, consulte Modelos de programação suportados.
Contentores
Por padrão, o Service Fabric implanta e ativa serviços como processos. O Service Fabric também pode implantar serviços em contêineres. É importante ressaltar que você pode misturar serviços em processos e serviços em contêineres no mesmo aplicativo. O Service Fabric oferece suporte à implantação de contêineres Linux e Windows no Windows Server 2016. Você pode implantar aplicativos existentes, serviços sem monitoração de estado ou serviços com monitoração de estado em contêineres.
Reliable Services
O Reliable Services é uma estrutura leve para escrever serviços que se integram à plataforma Service Fabric e se beneficiam do conjunto completo de recursos da plataforma. Os Serviços Confiáveis podem ser sem monitoração de estado (semelhante à maioria das plataformas de serviço, como servidores Web ou Funções de Trabalho nos Serviços de Nuvem do Azure), onde o estado é persistido em uma solução externa, como o Banco de Dados do Azure ou o Armazenamento de Tabela do Azure. Os Serviços Confiáveis também podem ser com monitoração de estado, onde o estado é persistido diretamente no próprio serviço usando Coleções Confiáveis. O estado é altamente disponível por meio da replicação e distribuído por particionamento, tudo gerenciado automaticamente pelo Service Fabric.
Reliable Actors
Construída com base em Serviços Confiáveis, a estrutura Reliable Ator é uma estrutura de aplicativo que implementa o padrão Virtual Ator, com base no padrão de design do ator. A estrutura Reliable Ator usa unidades independentes de computação e estado com execução single-threaded chamada actors. A estrutura Reliable Ator fornece comunicação integrada para atores e configurações pré-definidas de persistência de estado e expansão.
ASP.NET Core
O Service Fabric integra-se ao ASP.NET Core como um modelo de programação de primeira classe para a criação de aplicativos Web e API. ASP.NET Core pode ser usado de duas maneiras diferentes no Service Fabric:
- Hospedado como um executável convidado. Isso é usado principalmente para executar aplicativos ASP.NET Core existentes no Service Fabric sem alterações de código.
- Execute dentro de um serviço confiável. Isso permite uma melhor integração com o tempo de execução do Service Fabric e permite serviços ASP.NET Core com monitoração de estado.
Executáveis de convidado
Um executável convidado é um executável existente e arbitrário (escrito em qualquer idioma) hospedado em um cluster do Service Fabric ao lado de outros serviços. Os executáveis convidados não se integram diretamente às APIs do Service Fabric. No entanto, eles ainda se beneficiam de recursos que a plataforma oferece, como relatórios personalizados de integridade e carga e capacidade de descoberta de serviços chamando APIs REST. Eles também têm suporte completo ao ciclo de vida do aplicativo.
Ciclo de vida da aplicação
Assim como em outras plataformas, um aplicativo no Service Fabric geralmente passa pelas seguintes fases: design, desenvolvimento, teste, implantação, atualização, manutenção e remoção. O Service Fabric fornece suporte de primeira classe para todo o ciclo de vida de aplicativos em nuvem, desde o desenvolvimento até a implantação, gerenciamento diário e manutenção até a eventual desativação. O modelo de serviço permite que várias funções diferentes participem independentemente do ciclo de vida do aplicativo. O ciclo de vida do aplicativo Service Fabric fornece uma visão geral das APIs e como elas são usadas pelas diferentes funções ao longo das fases do ciclo de vida do aplicativo Service Fabric.
Todo o ciclo de vida do aplicativo pode ser gerenciado usando cmdlets do PowerShell, comandos CLI, APIs C#, APIs Java e APIs REST. Você também pode configurar pipelines de integração contínua/implantação contínua usando ferramentas como Azure Pipelines ou Jenkins.
Testar aplicações e serviços
Para criar serviços verdadeiramente em escala de nuvem, é fundamental verificar se seus aplicativos e serviços podem resistir a falhas do mundo real. O Serviço de Análise de Falhas foi projetado para testar serviços criados no Service Fabric. Com o Serviço de Análise de Falhas, você pode induzir falhas significativas e executar cenários de teste completos em seus aplicativos. Essas falhas e cenários exercitam e validam os inúmeros estados e transições que um serviço experimentará ao longo de sua vida útil, tudo de forma controlada, segura e consistente.
As ações visam um serviço para teste usando falhas individuais. Um desenvolvedor de serviços pode usá-los como blocos de construção para escrever cenários complicados. Exemplos de falhas simuladas são:
- Reinicie um nó para simular qualquer número de situações em que uma máquina ou VM é reinicializada.
- Mova uma réplica do seu serviço stateful para simular balanceamento de carga, failover ou atualização de aplicativo.
- Invoque a perda de quórum em um serviço com monitoração de estado para criar uma situação em que as operações de gravação não possam prosseguir porque não há réplicas de "backup" ou "secundárias" suficientes para aceitar novos dados.
- Invoque a perda de dados em um serviço com monitoração de estado para criar uma situação em que todo o estado na memória seja completamente apagado.
Os cenários são operações complexas compostas por uma ou mais ações. O Serviço de Análise de Falhas fornece dois cenários completos internos:
- Cenário de caos- simula falhas contínuas e intercaladas (graciosas e desgraçadas) em todo o cluster durante longos períodos de tempo.
- Cenário de failover- uma versão do cenário de teste de caos que tem como alvo uma partição de serviço específica, deixando outros serviços inalterados.
Clusters
Um cluster do Service Fabric é um conjunto ligado à rede de máquinas virtuais ou físicas, no qual os microsserviços são implementados e geridos. Os clusters podem ser dimensionados para milhares de máquinas. Uma máquina ou VM que faz parte de um cluster é chamada de nó de cluster. É atribuído um nome de nó (uma cadeia) a cada nó. Os nós têm características, como as propriedades de colocação. Cada máquina ou VM tem um serviço de inicialização automática, que começa a ser executado na inicialização e, em seguida, FabricHost.exeinicia dois executáveis: Fabric.exe e FabricGateway.exe. Esses dois executáveis compõem o nó. Para cenários de teste, você pode hospedar vários nós em uma única máquina ou VM executando várias instâncias de Fabric.exe e FabricGateway.exe.
Os clusters do Service Fabric podem ser criados em máquinas virtuais ou físicas que executam o Windows Server ou Linux. Você pode implantar e executar aplicativos do Service Fabric em qualquer ambiente em que tenha um conjunto de computadores Windows Server ou Linux interconectados: localmente, no Microsoft Azure ou em qualquer provedor de nuvem.
Clusters no Azure
A execução de clusters do Service Fabric no Azure fornece integração com outros recursos e serviços do Azure, o que torna as operações e o gerenciamento do cluster mais fáceis e confiáveis. Um cluster é um recurso do Azure Resource Manager, portanto, você pode modelar clusters como qualquer outro recurso no Azure. O Resource Manager também fornece gerenciamento fácil de todos os recursos usados pelo cluster como uma única unidade. Os clusters no Azure são integrados com o diagnóstico do Azure e os logs do Azure Monitor. Os tipos de nó de cluster são conjuntos de dimensionamento de máquina virtual, portanto, a funcionalidade de dimensionamento automático é incorporada.
Você pode criar um cluster no Azure por meio do portal do Azure, de um modelo ou do Visual Studio.
O Service Fabric no Linux permite que você crie, implante e gerencie aplicativos altamente disponíveis e escaláveis no Linux, assim como faria no Windows. As estruturas do Service Fabric (Reliable Services e Reliable Actors) estão disponíveis em Java no Linux, além do C# (.NET Core). Você também pode criar serviços executáveis convidados com qualquer linguagem ou estrutura. A orquestração de contêineres do Docker também é suportada. Os contêineres do Docker podem executar executáveis convidados ou serviços nativos do Service Fabric, que usam as estruturas do Service Fabric. Para obter mais informações, leia sobre o Service Fabric no Linux.
Existem alguns recursos que são suportados no Windows, mas não no Linux. Para saber mais, leia Diferenças entre o Service Fabric no Linux e no Windows.
Clusters autónomos
O Service Fabric fornece um pacote de instalação para você criar clusters autônomos do Service Fabric no local ou em qualquer provedor de nuvem. Os clusters autónomos dão-lhe a liberdade de alojar um cluster onde quiser. Se seus dados estiverem sujeitos a restrições regulatórias ou de conformidade, ou se você quiser manter seus dados locais, poderá hospedar seu próprio cluster e aplicativos. Os aplicativos do Service Fabric podem ser executados em vários ambientes de hospedagem sem alterações, portanto, seu conhecimento de criação de aplicativos é transferido de um ambiente de hospedagem para outro.
Crie seu primeiro cluster autônomo do Service Fabric
Os clusters autônomos do Linux ainda não são suportados.
Segurança do cluster
Os clusters devem ser protegidos para impedir que usuários não autorizados se conectem ao cluster, especialmente quando ele tem cargas de trabalho de produção em execução. Embora seja possível criar um cluster não seguro, isso permite que usuários anônimos se conectem a ele se os pontos de extremidade de gerenciamento forem expostos à Internet pública. Não é possível habilitar posteriormente a segurança em um cluster não seguro: a segurança do cluster é habilitada no momento da criação do cluster.
Os cenários de segurança de cluster são:
- Segurança nó a nó
- Segurança cliente-a-nó
- Controle de acesso baseado em função do Service Fabric
Para obter mais informações, leia Proteger um cluster.
Dimensionamento
Se você adicionar novos nós ao cluster, o Service Fabric reequilibrará as réplicas de partição e as instâncias no número maior de nós. O desempenho geral do aplicativo melhora e a contenção para acesso à memória diminui. Se os nós no cluster não estiverem sendo usados de forma eficiente, você poderá diminuir o número de nós no cluster. O Service Fabric reequilibra novamente as réplicas de partição e instâncias no número reduzido de nós para fazer melhor uso do hardware em cada nó. Você pode dimensionar clusters no Azure manualmente ou programaticamente. Os clusters autônomos podem ser dimensionados manualmente.
Atualizações de cluster
Periodicamente, novas versões do tempo de execução do Service Fabric são lançadas. Execute atualizações de tempo de execução ou malha em seu cluster para que você esteja sempre executando uma versão suportada. Além das atualizações de malha, você também pode atualizar a configuração do cluster, como certificados ou portas de aplicativo.
Um cluster do Service Fabric é um recurso que você possui, mas é parcialmente gerenciado pela Microsoft. A Microsoft é responsável por corrigir o sistema operacional subjacente e executar atualizações de malha em seu cluster. Você pode definir seu cluster para receber atualizações automáticas de malha, quando a Microsoft lançar uma nova versão, ou optar por selecionar uma versão de malha suportada desejada. As atualizações de malha e configuração podem ser definidas por meio do portal do Azure ou do Gerenciador de Recursos. Para obter mais informações, leia Atualizar um cluster do Service Fabric.
Um cluster autônomo é um recurso que você possui inteiramente. Você é responsável por corrigir o sistema operacional subjacente e iniciar atualizações de malha. Se o cluster puder se conectar ao https://www.microsoft.com/download, você poderá configurá-lo para baixar e provisionar automaticamente o novo pacote de tempo de execução do Service Fabric. Em seguida, você iniciaria a atualização. Se o cluster não puder acessar https://www.microsoft.com/downloado , você poderá baixar manualmente o novo pacote de tempo de execução de uma máquina conectada à Internet e iniciar a atualização. Para obter mais informações, leia Atualizar um cluster autônomo do Service Fabric.
Monitorização do estado de funcionamento
O Service Fabric apresenta um modelo de integridade projetado para sinalizar condições de cluster e aplicativo não íntegras em entidades específicas (como nós de cluster e réplicas de serviço). O modelo de saúde utiliza repórteres de saúde (componentes do sistema e watchdogs). O objetivo é um diagnóstico e reparação fácil e rápido. Os redatores de serviços precisam pensar antecipadamente sobre saúde e como projetar relatórios de saúde. Qualquer condição que possa afetar a saúde deve ser relatada, especialmente se puder ajudar a sinalizar problemas próximos à raiz. As informações de integridade podem economizar tempo e esforço na depuração e investigação quando o serviço estiver instalado e funcionando em escala na produção.
Os repórteres do Service Fabric monitoram as condições de interesse identificadas. Comunicam essas condições com base na sua visão local. O armazenamento de saúde agrega dados de saúde enviados por todos os repórteres para determinar se as entidades estão globalmente saudáveis. O modelo destina-se a ser rico, flexível e fácil de usar. A qualidade dos relatórios de integridade determina a precisão da exibição de integridade do cluster. Falsos positivos que mostram erroneamente problemas não íntegros podem afetar negativamente atualizações ou outros serviços que usam dados de integridade. Exemplos desses serviços são os serviços de reparação e os mecanismos de alerta. Portanto, é necessário algum pensamento para fornecer relatórios que captem as condições de interesse da melhor maneira possível.
Os relatórios podem ser feitos a partir de:
- A réplica ou instância de serviço do Service Fabric monitorada.
- Vigilantes internos implantados como um serviço do Service Fabric (por exemplo, um serviço sem estado do Service Fabric que monitora condições e emite relatórios). Os vigilantes podem ser implantados em todos os nós ou podem ser afins ao serviço monitorado.
- Vigilantes internos que são executados nos nós do Service Fabric, mas não são implementados como serviços do Service Fabric.
- Watchdogs externos que investigam o recurso de fora do cluster do Service Fabric (por exemplo, serviço de monitoramento como Gomez).
Prontos para uso, os componentes do Service Fabric relatam a integridade de todas as entidades no cluster. Os relatórios de integridade do sistema fornecem visibilidade sobre a funcionalidade do cluster e do aplicativo e sinalizam problemas de integridade. Para aplicativos e serviços, os relatórios de integridade do sistema verificam se as entidades estão implementadas e se comportando corretamente da perspetiva do tempo de execução do Service Fabric. Os relatórios não fornecem nenhum monitoramento de integridade da lógica de negócios do serviço ou detetam processos que pararam de responder. Para adicionar informações de integridade específicas à lógica do seu serviço, implemente relatórios de integridade personalizados em seus serviços.
O Service Fabric fornece várias maneiras de exibir relatórios de integridade agregados no repositório de integridade:
- Service Fabric Explorer ou outras ferramentas de visualização.
- Consultas de integridade (por meio do PowerShell, CLI, APIs do C# FabricClient e APIs do Java FabricClient ou APIs REST).
- Consultas gerais que retornam uma lista de entidades que têm a integridade como uma das propriedades (por meio do PowerShell, da CLI, das APIs ou REST).
Monitorização e diagnóstico
O monitoramento e o diagnóstico são essenciais para desenvolver, testar e implantar aplicativos e serviços em qualquer ambiente. As soluções do Service Fabric funcionam melhor quando você planeja e implementa monitoramento e diagnóstico que ajudam a garantir que os aplicativos e serviços estejam funcionando conforme o esperado em um ambiente de desenvolvimento local ou em produção.
Os principais objetivos da monitorização e diagnóstico são:
- Detetar e diagnosticar problemas de hardware e infraestrutura
- Detete problemas de software e aplicativos, reduza o tempo de inatividade do serviço
- Compreender o consumo de recursos e ajudar a orientar as decisões operacionais
- Otimize o desempenho de aplicativos, serviços e infraestrutura
- Gerar insights de negócios e identificar áreas de melhoria
O fluxo de trabalho geral de monitoramento e diagnóstico consiste em três etapas:
- Geração de eventos: inclui eventos (logs, rastreamentos, eventos personalizados) na infraestrutura (cluster), plataforma e nível de aplicativo/serviço
- Agregação de eventos: os eventos gerados precisam ser coletados e agregados antes de poderem ser exibidos
- Análise: os eventos precisam ser visualizados e acessíveis em algum formato, para permitir a análise e exibição conforme necessário
Estão disponíveis vários produtos que abrangem estas três áreas, e você é livre para escolher diferentes tecnologias para cada uma. Para obter mais informações, leia Monitoramento e diagnóstico do Azure Service Fabric.
Próximos passos
- Saiba como criar um cluster no Azure ou um cluster autónomo no Windows.
- Experimente criar um serviço com os modelos de programação Reliable Services ou Reliable Actors.
- Saiba como migrar dos Serviços na Nuvem.
- Aprenda a monitorizar e diagnosticar serviços.
- Aprenda a testar as suas aplicações e serviços.
- Aprenda a gerenciar e orquestrar recursos de cluster.
- Veja os exemplos do Service Fabric.
- Saiba mais sobre as opções de suporte do Service Fabric.
- Leia o blog da equipe para artigos e anúncios.