Tutorial: Analisar relatórios de inventário de blob
Ao entender como seus blobs e contêineres são armazenados, organizados e usados na produção, você pode otimizar melhor as compensações entre custo e desempenho.
Este tutorial mostra como gerar e visualizar estatísticas, como crescimento de dados ao longo do tempo, dados adicionados ao longo do tempo, número de arquivos modificados, tamanhos de instantâneo de blob, padrões de acesso em cada camada e como os dados são distribuídos atualmente e ao longo do tempo (por exemplo: dados entre camadas, tipos de arquivo, em contêineres e tipos de blob).
Neste tutorial, irá aprender a:
- Gerar um relatório de inventário de blob
- Configurar um espaço de trabalho Synapse
- Configurar o Synapse Studio
- Gerar dados analíticos no Synapse Studio
- Visualizar os resultados no Power BI
Pré-requisitos
Uma subscrição do Azure - crie uma conta gratuitamente
Uma conta de armazenamento do Azure - criar uma conta de armazenamento
Certifique-se de que sua identidade de usuário tenha a função de Colaborador de Dados de Blob de Armazenamento atribuída a ela.
Gerar um relatório de inventário
Habilite relatórios de inventário de blob para sua conta de armazenamento. Consulte Habilitar relatórios de inventário de blob de armazenamento do Azure.
Talvez seja necessário aguardar até 24 horas após habilitar os relatórios de inventário para que seu primeiro relatório seja gerado.
Configurar um espaço de trabalho Synapse
Crie um espaço de trabalho do Azure Synapse. Consulte Criar um espaço de trabalho do Azure Synapse.
Nota
Como parte da criação do espaço de trabalho, você criará uma conta de armazenamento que tenha um namespace hierárquico. O Azure Synapse armazena tabelas do Spark e logs de aplicativos nessa conta. O Azure Synapse refere-se a esta conta como a conta de armazenamento principal. Para evitar confusão, este artigo usa o termo conta de relatório de inventário para se referir à conta que contém relatórios de inventário.
No espaço de trabalho Sinapse, atribua a função de Colaborador à sua identidade de usuário. Consulte Azure RBAC: Função de proprietário para o espaço de trabalho.
Dê permissão ao espaço de trabalho Synapse para acessar os relatórios de inventário em sua conta de armazenamento navegando até sua conta de relatório de inventário e, em seguida, atribuindo a função de Colaborador de Dados de Blob de Armazenamento à identidade gerenciada pelo sistema do espaço de trabalho. Veja Atribuir funções do Azure com o portal do Azure.
Navegue até a conta de armazenamento principal e atribua a função de Colaborador de Armazenamento de Blob à sua identidade de usuário.
Configurar o Synapse Studio
Abra o espaço de trabalho Synapse no Synapse Studio. Consulte Open Synapse Studio.
No Synapse Studio, certifique-se de que a sua identidade está atribuída a função de administrador Synapse. Consulte Synapse RBAC: Synapse Administrator role para o espaço de trabalho.
Crie um pool do Apache Spark. Consulte Criar um pool do Apache Spark sem servidor.
Configurar e executar o bloco de notas de exemplo
Nesta seção, você gerará dados estatísticos que visualizará em um relatório. Para simplificar este tutorial, esta seção usa um arquivo de configuração de exemplo e um bloco de anotações PySpark de exemplo. O bloco de anotações contém uma coleção de consultas que são executadas no Azure Synapse Studio.
Modificar e carregar o arquivo de configuração de exemplo
Transfira o ficheiro BlobInventoryStorageAccountConfiguration.json .
Atualize os seguintes espaços reservados desse arquivo:
Defina
storageAccountNamecomo o nome da sua conta de relatório de inventário.Defina
destinationContainercomo o nome do contêiner que contém os relatórios de inventário.Defina
blobInventoryRuleNamecomo o nome da regra de relatório de inventário que gerou os resultados que você deseja analisar.Defina
accessKeycomo a chave de conta da conta de relatório de inventário.
Carregue esse arquivo para o contêiner em sua conta de armazenamento principal que você especificou quando criou o espaço de trabalho Sinapse.
Importar o bloco de anotações PySpark de exemplo
Baixe o bloco de anotações de exemplo ReportAnalysis.ipynb .
Nota
Certifique-se de salvar este arquivo com a
.ipynbextensão.Abra o espaço de trabalho Synapse no Synapse Studio. Consulte Open Synapse Studio.
No Synapse Studio, selecione a guia Desenvolver .
Selecione o sinal de adição (+) para adicionar um item.
Selecione Importar, navegue até o arquivo de exemplo que você baixou, selecione esse arquivo e selecione Abrir.
A caixa de diálogo Propriedades é exibida.
Na caixa de diálogo Propriedades, selecione o link Configurar sessão.

A caixa de diálogo Configurar sessão é aberta.
Na lista suspensa Anexar a da caixa de diálogo Configurar sessão, selecione o pool do Spark criado anteriormente neste artigo. Em seguida, selecione o botão Aplicar .
Modificar o bloco de anotações Python
Na primeira célula do bloco de anotações Python, defina o
storage_accountvalor da variável como o nome da conta de armazenamento principal.Atualize o
container_namevalor da variável para o nome do contêiner nessa conta que você especificou quando criou o espaço de trabalho Sinapse.Selecione o botão Publicar.
Execute o bloco de anotações PySpark
No bloco de anotações PySpark, selecione Executar tudo.
Levará alguns minutos para iniciar a sessão do Spark e outros minutos para processar os relatórios de inventário. A primeira execução pode demorar um pouco se houver vários relatórios de inventário para processar. As execuções subsequentes processarão apenas os novos relatórios de inventário criados desde a última execução.
Nota
Se você fizer alterações no bloco de anotações em execução, publique essas alterações usando o botão Publicar .
Verifique se o bloco de anotações foi executado com êxito selecionando a guia Dados .
Um banco de dados chamado reportdata deve aparecer na guia Espaço de trabalho do painel Dados. Se esse banco de dados não aparecer, talvez seja necessário atualizar a página da Web.
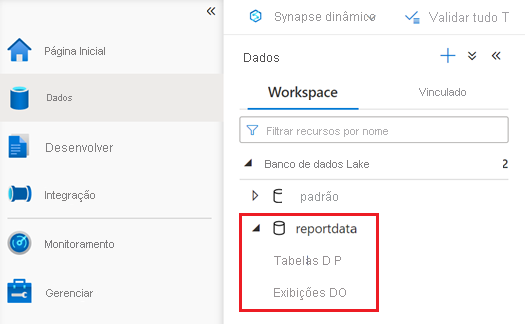
O banco de dados contém um conjunto de tabelas. Cada tabela contém informações obtidas ao executar as consultas do bloco de anotações PySpark.
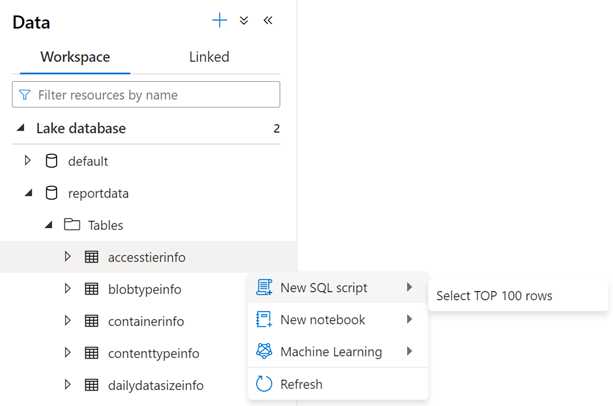
Para examinar o conteúdo de uma tabela, expanda a pasta Tabelas do banco de dados reportdata . Em seguida, clique com o botão direito do rato numa tabela, selecione Selecionar script SQL e, em seguida, selecione Selecionar TOP 100 linhas.
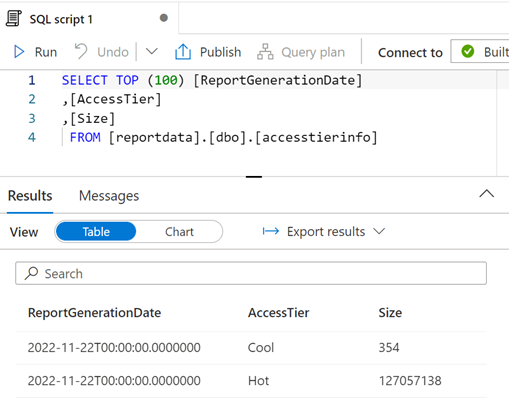
Você pode modificar a consulta conforme necessário e, em seguida, selecionar Executar para exibir os resultados.
Ver os dados
Baixe o arquivo de relatório de exemplo ReportAnalysis.pbit .
Abra Power BI Desktop. Para obter orientações de instalação, consulte Obter o Power BI Desktop.
No Power BI, selecione Ficheiro, Abrir relatório e, em seguida , Procurar relatórios.
Na caixa de diálogo Abrir, altere o tipo de arquivo para arquivos de modelo do Power BI (*.pbit).

Navegue até o local do arquivo ReportAnalysis.pbit que você baixou e selecione Abrir.
É exibida uma caixa de diálogo que solicita que você forneça o nome do espaço de trabalho Synapse e o nome do banco de dados.
Na caixa de diálogo, defina o campo synapse_workspace_name como o nome do espaço de trabalho e defina o campo database_name como
reportdata. Em seguida, selecione o botão Carregar .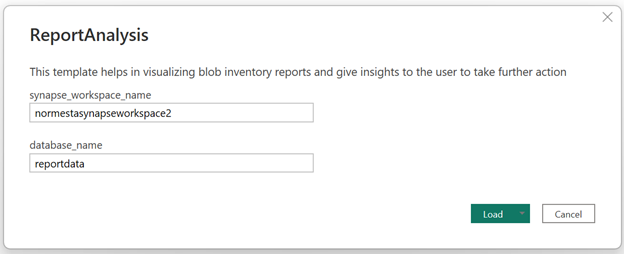
É apresentado um relatório que fornece visualizações dos dados recuperados pelo bloco de notas. As imagens a seguir mostram os tipos de gráficos que aparecem neste relatório.
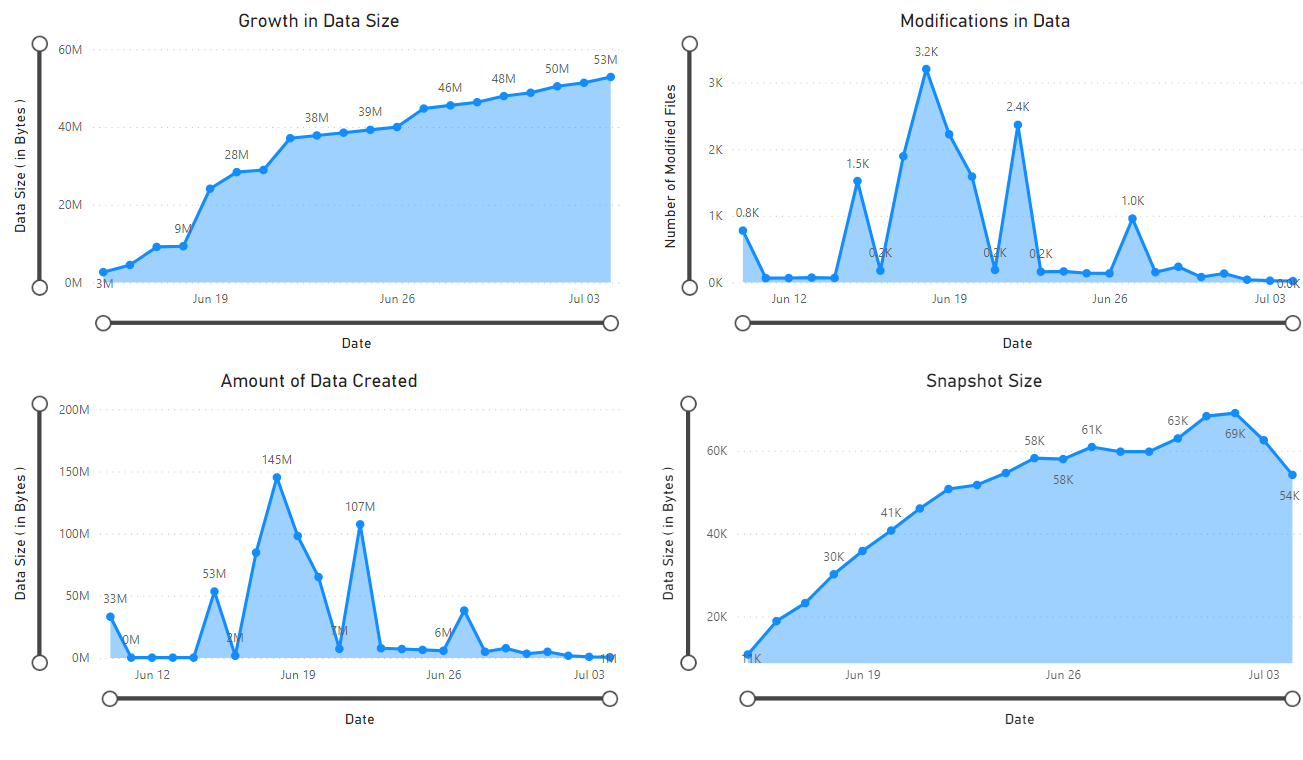
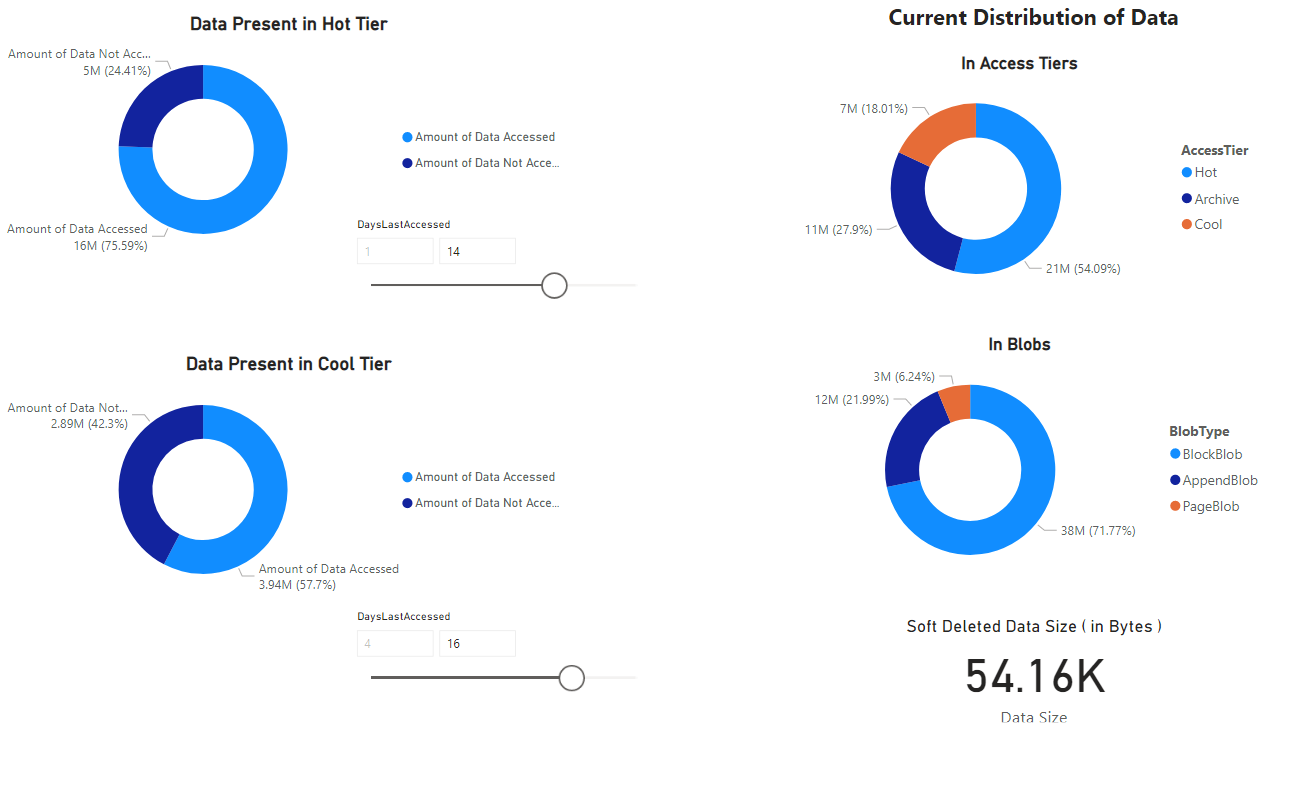
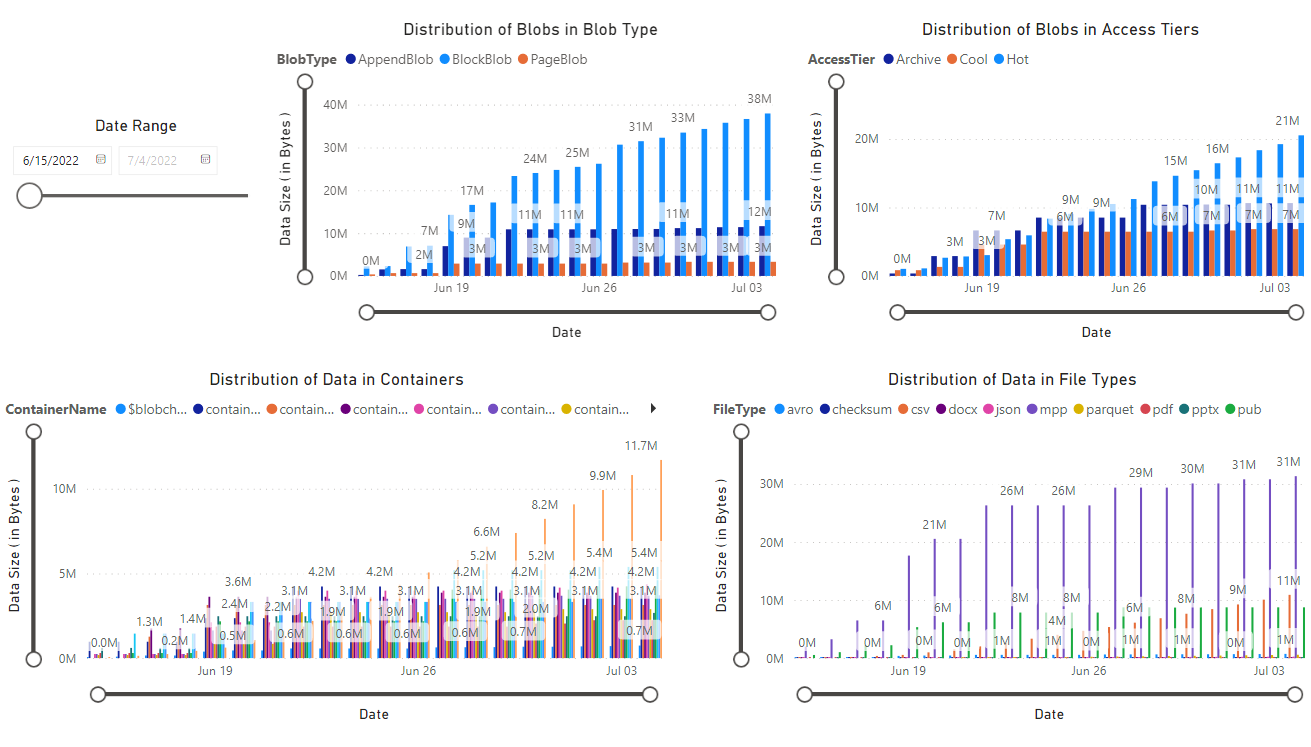
Próximos passos
Configure um pipeline do Azure Synapse para continuar executando seu bloco de anotações em intervalos regulares. Dessa forma, você pode processar novos relatórios de inventário à medida que eles são criados. Após a execução inicial, cada uma das próximas execuções analisará dados incrementais e, em seguida, atualizará as tabelas com os resultados dessa análise. Para obter orientações, consulte Integrar com pipelines.
Saiba mais sobre maneiras de analisar contêineres individuais em sua conta de armazenamento. Veja estes artigos:
Tutorial: Calcular estatísticas de contêiner usando Databricks
Saiba mais sobre maneiras de otimizar seus custos com base na análise de seus blobs e contêineres. Veja estes artigos:
Planear e gerir os custos do Armazenamento de Blobs do Azure
Estimar o custo de arquivamento de dados
Otimize os custos gerenciando automaticamente o ciclo de vida dos dados