Analise o desempenho do trabalho do Stream Analytics usando métricas e dimensões
Para entender a integridade de um trabalho do Azure Stream Analytics, é importante saber como usar as métricas e dimensões do trabalho. Você pode usar o portal do Azure, a extensão do Visual Studio Code Stream Analytics ou um SDK para obter as métricas e dimensões em que está interessado.
Este artigo demonstra como usar métricas e dimensões de trabalho do Stream Analytics para analisar o desempenho de um trabalho por meio do portal do Azure.
Atraso de marca d'água e eventos de entrada em backlog são as principais métricas para determinar o desempenho do seu trabalho do Stream Analytics. Se o atraso da marca d'água do seu trabalho está aumentando continuamente e os eventos de entrada estão atrasados, seu trabalho não consegue acompanhar a taxa de eventos de entrada e produzir saídas em tempo hábil.
Vejamos vários exemplos para analisar o desempenho de um trabalho por meio dos dados da métrica Atraso da marca d'água como ponto de partida.
Nenhuma entrada para uma determinada partição aumenta o atraso da marca d'água do trabalho
Se o atraso da marca d'água do seu trabalho paralelo está aumentando constantemente, vá para Métricas. Em seguida, use estas etapas para descobrir se a causa raiz é a falta de dados em algumas partições da sua fonte de entrada:
Verifique qual partição tem o atraso crescente da marca d'água. Selecione a métrica Atraso da marca d'água e divida-a pela dimensão ID da partição. No exemplo a seguir, a partição 465 tem um alto atraso de marca d'água.

Verifique se faltam dados de entrada para esta partição. Selecione a métrica Eventos de entrada e filtre-a para esse ID de partição específico.



Que outras medidas pode tomar?
O atraso da marca d'água para esta partição está aumentando porque nenhum evento de entrada está fluindo para essa partição. Se a janela de tolerância do seu trabalho para chegadas tardias for de várias horas e nenhum dado de entrada estiver fluindo para uma partição, espera-se que o atraso da marca d'água para essa partição continue a aumentar até que a janela de chegada tardia seja atingida.
Por exemplo, se a janela de chegada tardia for de 6 horas e os dados de entrada não estiverem fluindo para a partição de entrada 1, o atraso da marca d'água para a partição de saída 1 aumentará até chegar a 6 horas. Você pode verificar se sua fonte de entrada está produzindo dados conforme o esperado.
A distorção dos dados de entrada causa um atraso de marca d'água alto
Como mencionado no caso anterior, quando seu trabalho embaraçosamente paralelo tem um alto atraso de marca d'água, a primeira coisa a fazer é dividir a métrica Atraso de marca d'água pela dimensão ID da partição. Em seguida, você pode identificar se todas as partições têm alto atraso de marca d'água ou apenas algumas delas.
No exemplo a seguir, as partições 0 e 1 têm maior atraso de marca d'água (cerca de 20 a 30 segundos) do que as outras oito partições. Os atrasos da marca d'água das outras partições são sempre estáveis em cerca de 8 a 10 segundos.

Vamos verificar como são os dados de entrada para todas essas partições com a métrica Eventos de entrada divididos por ID de partição:

Que outras medidas pode tomar?
Como mostrado no exemplo, as partições (0 e 1) que têm um atraso de marca d'água alto estão recebendo significativamente mais dados de entrada do que outras partições. Chamamos isso de distorção de dados. Os nós de streaming que estão processando as partições com distorção de dados precisam consumir mais recursos de CPU e memória do que outros, conforme mostrado na captura de tela a seguir.

Os nós de streaming que processam partições com maior inclinação de dados exibirão maior utilização da CPU e/ou unidade de streaming (SU). Essa utilização afetará o desempenho do trabalho e aumentará o atraso da marca d'água. Para atenuar isso, você precisa reparticionar seus dados de entrada de forma mais uniforme.
Você também pode depurar esse problema com o diagrama de trabalho físico, consulte Diagrama de trabalho físico: identificar os eventos de entrada distribuídos irregulares (distorção de dados).
CPU ou memória sobrecarregada aumenta o atraso da marca d'água
Quando um trabalho paralelo embaraçoso tem um atraso crescente na marca d'água, isso pode acontecer não apenas em uma ou várias partições, mas em todas as partições. Como confirma que o seu emprego está a cair neste caso?
Divida a métrica Atraso da marca d'água pelo ID da partição. Por exemplo:

Divida a métrica Eventos de Entrada por ID de Partição para confirmar se há distorção de dados nos dados de entrada para cada partição.
Verifique a utilização da CPU e da SU para ver se a utilização em todos os nós de streaming é muito alta.
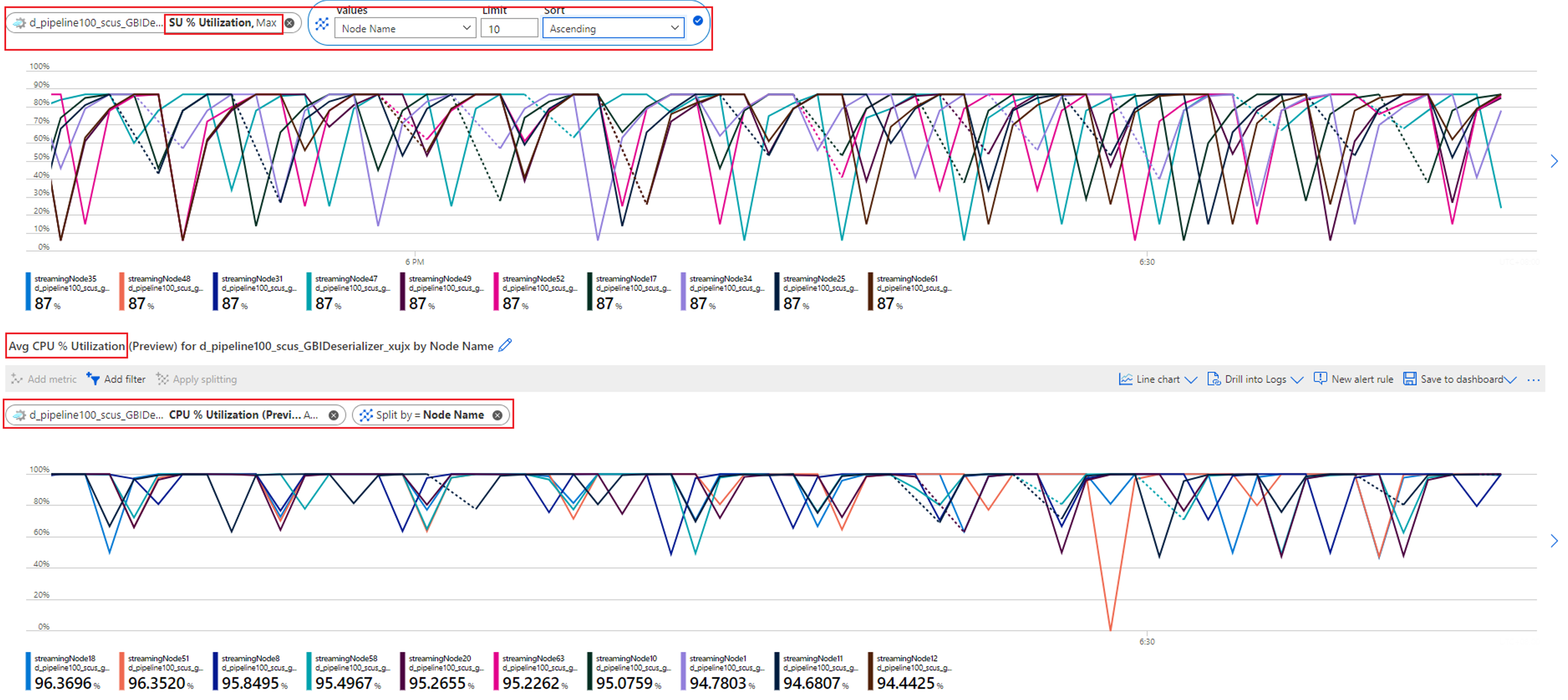
Se a utilização de CPU e SU for muito alta (mais de 80%) em todos os nós de streaming, você pode concluir que esse trabalho tem uma grande quantidade de dados sendo processados dentro de cada nó de streaming.
Você pode verificar ainda quantas partições estão alocadas a um nó de streaming verificando a métrica Eventos de entrada . Filtre por ID do nó de streaming com a dimensão Nome do nó e divida por ID da partição.

A captura de tela anterior mostra que quatro partições são alocadas para um nó de streaming que ocupa cerca de 90 a 100% do recurso do nó de streaming. Você pode usar uma abordagem semelhante para verificar o restante dos nós de streaming para confirmar que eles também estão processando dados de quatro partições.



Que outras medidas pode tomar?
Talvez você queira reduzir a contagem de partições para cada nó de streaming para reduzir os dados de entrada para cada nó de streaming. Para conseguir isso, você pode dobrar os SUs para que cada nó de streaming manipule dados de duas partições. Ou você pode quadruplicar os SUs para que cada nó de streaming manipule dados de uma partição. Para obter informações sobre a relação entre a atribuição de SU e a contagem de nós de streaming, consulte Compreender e ajustar unidades de streaming.
O que você deve fazer se o atraso da marca d'água ainda estiver aumentando quando um nó de streaming estiver manipulando dados de uma partição? Reparticione sua entrada com mais partições para reduzir a quantidade de dados em cada partição. Para obter detalhes, consulte Usar o reparticionamento para otimizar os trabalhos do Azure Stream Analytics.
Você também pode depurar esse problema com o diagrama de trabalho físico, consulte Diagrama de trabalho físico: identificar a causa da CPU ou memória sobrecarregada.