Ligar ao Azure Data Explorer com o Apache Spark do Azure Synapse Analytics
Este artigo descreve como acessar um banco de dados do Azure Data Explorer do Synapse Studio com o Apache Spark for Azure Synapse Analytics.
Pré-requisitos
- Crie um cluster e um banco de dados do Azure Data Explorer.
- Tenha um espaço de trabalho existente do Azure Synapse Analytics ou crie um novo espaço de trabalho seguindo as etapas em Guia de início rápido: criar um espaço de trabalho do Azure Synapse.
- Tenha um pool Apache Spark existente ou crie um novo pool seguindo as etapas em Guia de início rápido: criar um pool do Apache Spark usando o portal do Azure.
- Crie um aplicativo Microsoft Entra provisionando um aplicativo Microsoft Entra.
- Conceda ao seu aplicativo Microsoft Entra acesso ao seu banco de dados seguindo as etapas em Gerenciar permissões de banco de dados do Azure Data Explorer.
Ir para Synapse Studio
Em um espaço de trabalho do Azure Synapse, selecione Iniciar o Synapse Studio. Na página inicial do Synapse Studio, selecione Dados para ir para o Data Object Explorer.
Conectar um banco de dados do Azure Data Explorer a um espaço de trabalho do Azure Synapse
A conexão de um banco de dados do Azure Data Explorer a um espaço de trabalho é feita por meio de um serviço vinculado. Com um serviço vinculado do Azure Data Explorer, você pode navegar e explorar dados, ler e gravar no Apache Spark for Azure Synapse. Você também pode executar trabalhos de integração em um pipeline.
No Pesquisador de Objetos de Dados, siga estas etapas para conectar diretamente um cluster do Azure Data Explorer:
Selecione o + ícone perto de Dados.
Selecione Conectar para conectar-se a dados externos.
Selecione Azure Data Explorer (Kusto).
Selecione Continuar.
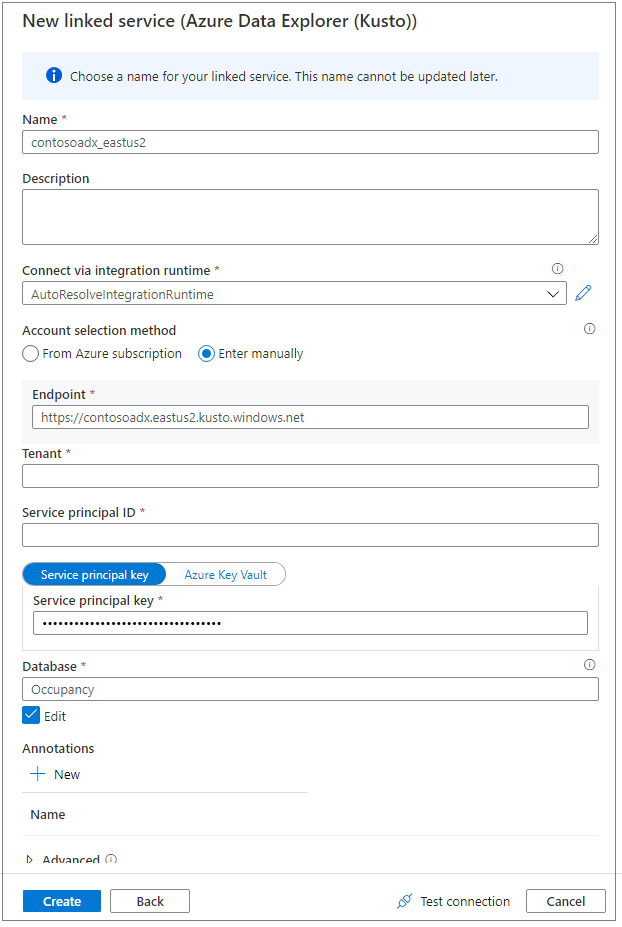
Use um nome amigável para nomear o serviço vinculado. O nome aparecerá no Pesquisador de Objetos de Dados e é usado pelos tempos de execução do Azure Synapse para se conectar ao banco de dados.
Selecione o cluster do Azure Data Explorer na sua assinatura ou insira o URI.
Insira o ID da entidade de serviço e a chave da entidade de serviço. Verifique se essa entidade de serviço tem acesso de visualização no banco de dados para operação de leitura e acesso ingestor para ingestão de dados.
Insira o nome do banco de dados do Azure Data Explorer.
Selecione Testar conexão para garantir que você tenha as permissões certas.
Selecione Criar.
Nota
(Opcional) A conexão de teste não valida o acesso de gravação. Verifique se sua ID da entidade de serviço tem acesso de gravação ao banco de dados do Azure Data Explorer.
Os clusters e bancos de dados do Azure Data Explorer aparecem na guia Vinculado na seção Azure Data Explorer .
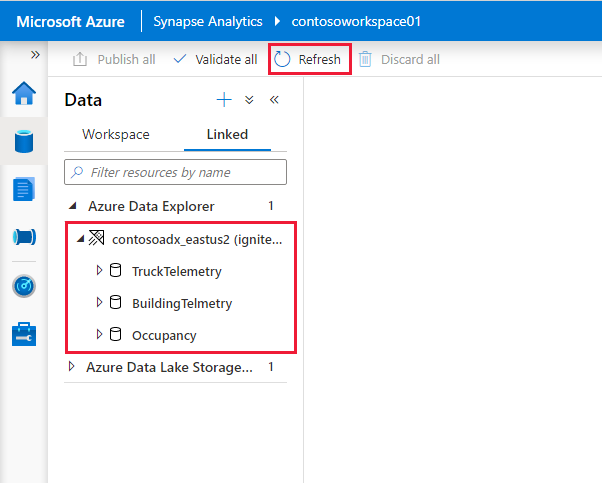
Antes de poder interagir com o serviço vinculado a partir de um bloco de anotações, ele deve ser publicado no espaço de trabalho. Clique em Publicar na barra de ferramentas, revise as alterações pendentes e clique em OK.
Nota
Na versão atual, os objetos de banco de dados são preenchidos com base nas permissões da sua conta do Microsoft Entra nos bancos de dados do Azure Data Explorer. Quando você executa os blocos de anotações ou trabalhos de integração do Apache Spark, a credencial no serviço de link será usada (por exemplo, entidade de serviço).
Interaja rapidamente com ações geradas por código
Quando você clica com o botão direito do mouse em um banco de dados ou tabela, uma lista de blocos de anotações Spark de exemplo é exibida. Selecione uma opção para ler, gravar ou transmitir dados para o Azure Data Explorer.

Aqui está um exemplo de leitura de dados. Conecte o bloco de anotações ao pool do Spark e execute a célula.

Nota
A primeira execução pode levar mais de três minutos para iniciar a sessão do Spark. As execuções subsequentes serão significativamente mais rápidas.
Limitações
Atualmente, o conector do Azure Data Explorer não é suportado com redes virtuais gerenciadas pelo Azure Synapse.