Dados SQL vs. NoSQL
Gorjeta
Este conteúdo é um excerto do eBook, Architecting Cloud Native .NET Applications for Azure, disponível no .NET Docs ou como um PDF transferível gratuito que pode ser lido offline.

Relacional (SQL) e não relacional (NoSQL) são dois tipos de sistemas de banco de dados comumente implementados em aplicativos nativos da nuvem. Eles são construídos de forma diferente, armazenam dados de forma diferente e são acessados de forma diferente. Nesta seção, veremos ambos. Mais adiante neste capítulo, veremos uma tecnologia de banco de dados emergente chamada NewSQL.
Os bancos de dados relacionais têm sido uma tecnologia predominante há décadas. Eles são maduros, comprovados e amplamente implementados. Produtos de banco de dados, ferramentas e experiência concorrentes são abundantes. Os bancos de dados relacionais fornecem um armazenamento de tabelas de dados relacionadas. Essas tabelas têm um esquema fixo, usam SQL (Structured Query Language) para gerenciar dados e suportam garantias ACID: atomicidade, consistência, isolamento e durabilidade.
Os bancos de dados NoSQL referem-se a armazenamentos de dados não relacionais de alto desempenho. Eles se destacam em suas características de facilidade de uso, escalabilidade, resiliência e disponibilidade. Em vez de unir tabelas de dados normalizados, o NoSQL armazena dados não estruturados ou semiestruturados, geralmente em pares chave-valor ou documentos JSON. Os bancos de dados NoSQL normalmente não fornecem garantias ACID além do escopo de uma única partição de banco de dados. Serviços de alto volume que exigem tempo de resposta inferior a um segundo favorecem os armazenamentos de dados NoSQL.
O impacto das tecnologias NoSQL para sistemas distribuídos nativos da nuvem não pode ser exagerado. A proliferação de novas tecnologias de dados neste espaço interrompeu soluções que antes dependiam exclusivamente de bancos de dados relacionais.
Os bancos de dados NoSQL incluem vários modelos diferentes para acessar e gerenciar dados, cada um adequado para casos de uso específicos. A Figura 5-9 apresenta quatro modelos comuns.
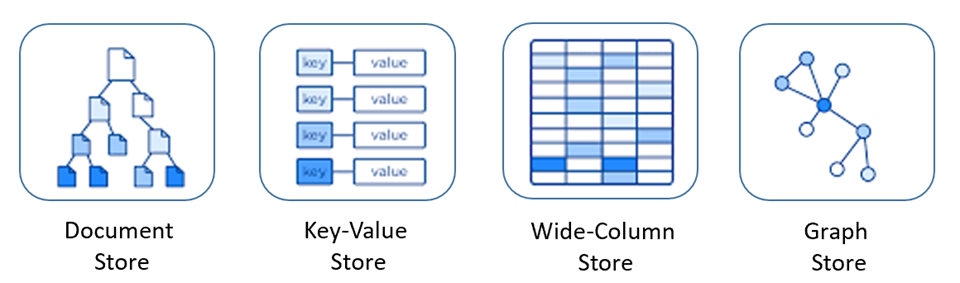
Figura 5-9: Modelos de dados para bancos de dados NoSQL
| Modelo | Características |
|---|---|
| Arquivo de Documentos | Os dados e metadados são armazenados hierarquicamente em documentos baseados em JSON dentro do banco de dados. |
| Armazenamento de Valor Chave | O mais simples dos bancos de dados NoSQL, os dados são representados como uma coleção de pares chave-valor. |
| Loja de coluna larga | Os dados relacionados são armazenados como um conjunto de pares chave/valor aninhados em uma única coluna. |
| Arquivo de Grafos | Os dados são armazenados em uma estrutura gráfica como propriedades de nó, borda e dados. |
teorema CAP
Como forma de compreender as diferenças entre estes tipos de bases de dados, considere o teorema CAP, um conjunto de princípios aplicados a sistemas distribuídos que armazenam estado. A Figura 5-10 mostra as três propriedades do teorema da PAC.
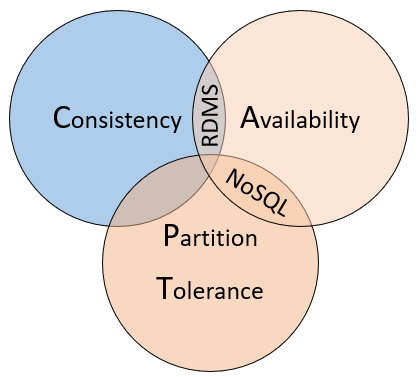
Figura 5-10. teorema CAP
O teorema afirma que os sistemas de dados distribuídos oferecerão um compromisso entre consistência, disponibilidade e tolerância de partição. E que qualquer banco de dados só pode garantir duas das três propriedades:
Consistência. Cada nó no cluster responde com os dados mais recentes, mesmo que o sistema precise bloquear a solicitação até que todas as réplicas sejam atualizadas. Se você consultar um "sistema consistente" para um item que está sendo atualizado no momento, aguardará essa resposta até que todas as réplicas sejam atualizadas com êxito. No entanto, você receberá os dados mais atuais. Deve entender-se que o termo "consistência" tal como é usado no contexto do teorema da PAC tem um significado técnico que é distinto da forma como "consistência" é definida no contexto das garantias ACID.
Disponibilidade. Cada solicitação recebida por um nó sem falha no sistema deve resultar em uma resposta. Simplificando, se você consultar um "sistema disponível" para um item que está atualizando, você obterá a melhor resposta possível que o serviço pode fornecer naquele momento. Mas note que a "disponibilidade", tal como definida pelo teorema da PAC, é tecnicamente diferente da "alta disponibilidade", como é convencionalmente conhecida para sistemas distribuídos.
Tolerância de partição. Garante que o sistema continue a operar mesmo se um nó de dados replicado falhar ou perder a conectividade com outros nós de dados replicados.
O teorema CAP explica as compensações associadas ao gerenciamento de consistência e disponibilidade durante uma partição de rede; no entanto, também existem compensações em relação à consistência e desempenho com a ausência de uma partição de rede. O teorema da PAC é frequentemente estendido à PACELC para explicar as compensações de forma mais abrangente.
Nota
Mesmo que você escolha a disponibilidade em vez da consistência, em tempos de partição de rede, a disponibilidade será prejudicada. O sistema CAP disponível está mais disponível para alguns dos seus clientes, mas não é necessariamente "altamente disponível" para todos os seus clientes.
Os bancos de dados relacionais normalmente fornecem consistência e disponibilidade, mas não tolerância de partição. Eles geralmente são provisionados para um único servidor e dimensionados verticalmente adicionando mais recursos à máquina.
Muitos sistemas de banco de dados relacional oferecem suporte a recursos internos de replicação em que cópias do banco de dados primário podem ser feitas para outras instâncias de servidor secundário. As operações de gravação são feitas na instância primária e replicadas para cada um dos secundários. Em caso de falha, a instância principal pode fazer failover para uma secundária para fornecer alta disponibilidade. Os secundários também podem ser usados para distribuir operações de leitura. Embora as operações de gravação sempre vão contra a réplica primária, as operações de leitura podem ser roteadas para qualquer um dos secundários para reduzir a carga do sistema.
Os dados também podem ser particionados horizontalmente em vários nós, como com fragmentação. Mas, a fragmentação aumenta drasticamente a sobrecarga operacional ao cuspir dados em muitas partes que não podem se comunicar facilmente. A sua gestão pode ser dispendiosa e demorada. Recursos relacionais que incluem junções de tabelas, transações e integridade referencial exigem penalidades de desempenho acentuadas em implantações fragmentadas.
A consistência da replicação e os objetivos de ponto de recuperação podem ser ajustados configurando se a replicação ocorre de forma síncrona ou assíncrona. Se as réplicas de dados perdessem a conectividade de rede em um cluster de banco de dados relacional "altamente consistente" ou síncrono, você não poderia gravar no banco de dados. O sistema rejeitaria a operação de gravação, pois não pode replicar essa alteração para a outra réplica de dados. Cada réplica de dados precisa ser atualizada antes que a transação possa ser concluída.
Os bancos de dados NoSQL normalmente suportam alta disponibilidade e tolerância de partição. Eles são dimensionados horizontalmente, muitas vezes em servidores de mercadoria. Esta abordagem proporciona uma enorme disponibilidade, tanto dentro como entre regiões geográficas a um custo reduzido. Você particiona e replica dados entre essas máquinas ou nós, fornecendo redundância e tolerância a falhas. A consistência é normalmente ajustada através de protocolos de consenso ou mecanismos de quórum. Eles fornecem mais controle ao navegar por compensações entre o ajuste da replicação síncrona versus assíncrona em sistemas relacionais.
Se as réplicas de dados perderem a conectividade em um cluster de banco de dados NoSQL "altamente disponível", você ainda poderá concluir uma operação de gravação no banco de dados. O cluster de banco de dados permitiria a operação de gravação e atualizaria cada réplica de dados à medida que ela se tornasse disponível. Os bancos de dados NoSQL que suportam várias réplicas graváveis podem fortalecer ainda mais a alta disponibilidade, evitando a necessidade de failover ao otimizar o objetivo de tempo de recuperação.
Os bancos de dados NoSQL modernos normalmente implementam recursos de particionamento como um recurso do design do sistema. O gerenciamento de partições geralmente é incorporado ao banco de dados, e o roteamento é alcançado por meio de dicas de posicionamento - muitas vezes chamadas de chaves de partição. Um modelo de dados flexível permite que os bancos de dados NoSQL reduzam a carga do gerenciamento de esquema e melhorem a disponibilidade ao implantar atualizações de aplicativos que exigem alterações no modelo de dados.
A alta disponibilidade e a escalabilidade massiva são muitas vezes mais críticas para os negócios do que as junções de tabelas relacionais e a integridade referencial. Os desenvolvedores podem implementar técnicas e padrões como Sagas, CQRS e mensagens assíncronas para adotar uma eventual consistência.
Hoje em dia, é preciso ter cuidado ao considerar as restrições do teorema da PAC. Um novo tipo de banco de dados, chamado NewSQL, surgiu que estende o mecanismo de banco de dados relacional para suportar a escalabilidade horizontal e o desempenho escalável de sistemas NoSQL.
Considerações para sistemas relacionais versus NoSQL
Com base em requisitos de dados específicos, um microsserviço baseado em nuvem pode implementar um armazenamento de dados relacional, NoSQL ou ambos.
| Considere um armazenamento de dados NoSQL quando: | Considere um banco de dados relacional quando: |
|---|---|
| Você tem cargas de trabalho de alto volume que exigem latência previsível em grande escala (por exemplo, latência medida em milissegundos ao executar milhões de transações por segundo) | Seu volume de carga de trabalho geralmente se encaixa em milhares de transações por segundo |
| Os seus dados são dinâmicos e mudam frequentemente | Os seus dados são altamente estruturados e requerem integridade referencial |
| As relações podem ser modelos de dados desnormalizados | As relações são expressas por meio de junções de tabela em modelos de dados normalizados |
| A recuperação de dados é simples e expressa sem junções de tabelas | Você trabalha com consultas e relatórios complexos |
| Normalmente, os dados são replicados em regiões geográficas e requerem um controle mais preciso sobre consistência, disponibilidade e desempenho | Os dados são normalmente centralizados ou podem ser replicados regiões de forma assíncrona |
| Seu aplicativo será implantado em hardware de mercadoria, como com nuvens públicas | Seu aplicativo será implantado em hardware grande e high-end |
Nas próximas seções, exploraremos as opções disponíveis na nuvem do Azure para armazenar e gerenciar seus dados nativos da nuvem.
Banco de dados como serviço
Para começar, você pode provisionar uma máquina virtual do Azure e instalar seu banco de dados de escolha para cada serviço. Embora você tivesse controle total sobre o ambiente, abriria mão de muitos recursos integrados da plataforma de nuvem. Você também seria responsável por gerenciar a máquina virtual e o banco de dados para cada serviço. Esta abordagem pode rapidamente tornar-se demorada e dispendiosa.
Em vez disso, os aplicativos nativos da nuvem favorecem os serviços de dados expostos como um banco de dados como serviço (DBaaS). Totalmente gerenciados por um fornecedor de nuvem, esses serviços fornecem segurança, escalabilidade e monitoramento integrados. Em vez de possuir o serviço, você simplesmente o consome como um serviço de suporte. O provedor opera o recurso em escala e assume a responsabilidade pelo desempenho e manutenção.
Eles podem ser configurados em zonas e regiões de disponibilidade de nuvem para obter alta disponibilidade. Todos eles suportam capacidade just-in-time e um modelo de pagamento conforme o uso. O Azure apresenta diferentes tipos de opções de serviço de dados gerenciados, cada uma com benefícios específicos.
Primeiro, examinaremos os serviços DBaaS relacionais disponíveis no Azure. Você verá que o principal banco de dados SQL Server da Microsoft está disponível junto com várias opções de código aberto. Em seguida, falaremos sobre os serviços de dados NoSQL no Azure.
Bancos de dados relacionais do Azure
Para microsserviços nativos da nuvem que exigem dados relacionais, o Azure oferece quatro ofertas de bancos de dados relacionais gerenciados como serviço (DBaaS), mostradas na Figura 5-11.

Figura 5-11. Bancos de dados relacionais gerenciados disponíveis no Azure
Na figura anterior, observe como cada um se posiciona em uma infraestrutura DBaaS comum que apresenta recursos importantes sem custo adicional.
Esses recursos são especialmente importantes para organizações que fornecem um grande número de bancos de dados, mas têm recursos limitados para administrá-los. Você pode provisionar um banco de dados do Azure em minutos, selecionando a quantidade de núcleos de processamento, memória e armazenamento subjacente. Você pode dimensionar o banco de dados rapidamente e ajustar dinamicamente os recursos com pouco ou nenhum tempo de inatividade.
Base de Dados SQL do Azure
As equipes de desenvolvimento com experiência em Microsoft SQL Server devem considerar o Banco de Dados SQL do Azure. É um banco de dados relacional como serviço (DBaaS) totalmente gerenciado com base no Mecanismo de Banco de Dados do Microsoft SQL Server. O serviço compartilha muitos recursos encontrados na versão local do SQL Server e executa a versão estável mais recente do Mecanismo de Banco de Dados do SQL Server.
Para uso com um microsserviço nativo da nuvem, o Banco de Dados SQL do Azure está disponível com três opções de implantação:
Um Banco de Dados Único representa um Banco de Dados SQL totalmente gerenciado em execução em um servidor do Banco de Dados SQL do Azure na nuvem do Azure. O banco de dados é considerado contido , pois não tem dependências de configuração no servidor de banco de dados subjacente.
Uma Instância Gerenciada é uma instância totalmente gerenciada do Mecanismo de Banco de Dados do Microsoft SQL Server que fornece quase 100% de compatibilidade com um SQL Server local. Esta opção suporta bases de dados maiores, até 35 TB e é colocada numa Rede Virtual do Azure para um melhor isolamento.
O Banco de Dados SQL do Azure sem servidor é uma camada de computação para um único banco de dados que é dimensionado automaticamente com base na demanda de carga de trabalho. Ele cobra apenas pela quantidade de computação usada por segundo. O serviço é adequado para cargas de trabalho com padrões de uso intermitentes e imprevisíveis, intercalados com períodos de inatividade. A camada de computação sem servidor também pausa automaticamente os bancos de dados durante períodos inativos para que apenas as cobranças de armazenamento sejam cobradas. Ele é retomado automaticamente quando a atividade retorna.
Além da pilha tradicional do Microsoft SQL Server, o Azure também apresenta versões gerenciadas de três bancos de dados de código aberto populares.
Bancos de dados de código aberto no Azure
Os bancos de dados relacionais de código aberto tornaram-se uma escolha popular para aplicativos nativos da nuvem. Muitas empresas os favorecem em detrimento de produtos de banco de dados comerciais, especialmente para economia de custos. Muitas equipes de desenvolvimento desfrutam de sua flexibilidade, desenvolvimento apoiado pela comunidade e ecossistema de ferramentas e extensões. Os bancos de dados de código aberto podem ser implantados em vários provedores de nuvem, ajudando a minimizar a preocupação com a "dependência do fornecedor".
Os desenvolvedores podem facilmente hospedar automaticamente qualquer banco de dados de código aberto em uma VM do Azure. Ao mesmo tempo em que fornece controle total, essa abordagem coloca você no gancho para o gerenciamento, monitoramento e manutenção do banco de dados e da VM.
No entanto, a Microsoft continua seu compromisso de manter o Azure uma "plataforma aberta", oferecendo vários bancos de dados de código aberto populares como serviços DBaaS totalmente gerenciados .
Base de Dados do Azure para MySQL
MySQL é um banco de dados relacional de código aberto e um pilar para aplicações construídas na pilha de software LAMP. Amplamente escolhido para ler cargas de trabalho pesadas , é usado por muitas grandes organizações, incluindo Facebook, Twitter e YouTube. A edição comunitária está disponível gratuitamente, enquanto a edição empresarial requer a compra de uma licença. Criado originalmente em 1995, o produto foi comprado pela Sun Microsystems em 2008. A Oracle adquiriu a Sun e a MySQL em 2010.
O Banco de Dados do Azure para MySQL é um serviço de banco de dados relacional gerenciado baseado no mecanismo de código aberto do MySQL Server. Ele usa a edição MySQL Community. O servidor MySQL do Azure é o ponto administrativo do serviço. É o mesmo mecanismo de servidor MySQL usado para implantações locais. O mecanismo pode criar um único banco de dados por servidor ou vários bancos de dados por servidor que compartilham recursos. Você pode continuar a gerenciar dados usando as mesmas ferramentas de código aberto sem ter que aprender novas habilidades ou gerenciar máquinas virtuais.
Azure Database for MariaDB
O MariaDB Server é outro popular servidor de banco de dados de código aberto. Foi criado como um fork do MySQL quando a Oracle comprou a Sun Microsystems, que era proprietária do MySQL. A intenção era garantir que o MariaDB permanecesse de código aberto. Como o MariaDB é uma bifurcação do MySQL, os dados e as definições de tabela são compatíveis, e os protocolos, estruturas e APIs do cliente são muito unidos.
MariaDB tem uma comunidade forte e é usado por muitas grandes empresas. Enquanto a Oracle continua a manter, aprimorar e dar suporte ao MySQL, a fundação MariaDB gerencia o MariaDB, permitindo contribuições públicas para o produto e a documentação.
O Banco de Dados do Azure para MariaDB é um banco de dados relacional totalmente gerenciado como um serviço na nuvem do Azure. O serviço é baseado no mecanismo de servidor MariaDB community edition. Ele pode lidar com cargas de trabalho de missão crítica com desempenho previsível e escalabilidade dinâmica.
Base de Dados do Azure para PostgreSQL
O PostgreSQL é um banco de dados relacional de código aberto com mais de 30 anos de desenvolvimento ativo. O PostgreSQL tem uma forte reputação de confiabilidade e integridade de dados. É rico em recursos, compatível com SQL e considerado mais eficiente do que o MySQL - especialmente para cargas de trabalho com consultas complexas e gravações pesadas. Muitas grandes empresas, incluindo Apple, Red Hat e Fujitsu, construíram produtos usando PostgreSQL.
O Banco de Dados do Azure para PostgreSQL é um serviço de banco de dados relacional totalmente gerenciado, baseado no mecanismo de banco de dados Postgres de código aberto. O serviço suporta muitas plataformas de desenvolvimento, incluindo C++, Java, Python, Node, C# e PHP. Você pode migrar bancos de dados PostgreSQL para ele usando a ferramenta de interface de linha de comando ou o Serviço de Migração de Dados do Azure.
O Banco de Dados do Azure para PostgreSQL está disponível com duas opções de implantação:
A opção de implantação de Servidor Único é um ponto administrativo central para vários bancos de dados nos quais você pode implantar muitos bancos de dados. O preço é estruturado por servidor com base em núcleos e armazenamento.
A opção Hyperscale (Citus) é alimentada pela tecnologia Citus Data. Ele permite alto desempenho dimensionando horizontalmente um único banco de dados em centenas de nós para oferecer desempenho e dimensionamento rápidos. Essa opção permite que o mecanismo ajuste mais dados na memória, paralelize consultas em centenas de nós e indexe dados mais rapidamente.
Dados NoSQL no Azure
O Cosmos DB é um serviço de banco de dados NoSQL totalmente gerenciado e distribuído globalmente na nuvem do Azure. Foi adotado por muitas grandes empresas em todo o mundo, incluindo Coca-Cola, Skype, ExxonMobil e Liberty Mutual.
Se seus serviços exigem resposta rápida de qualquer lugar do mundo, alta disponibilidade ou escalabilidade elástica, o Cosmos DB é uma ótima escolha. A Figura 5-12 mostra o Cosmos DB.
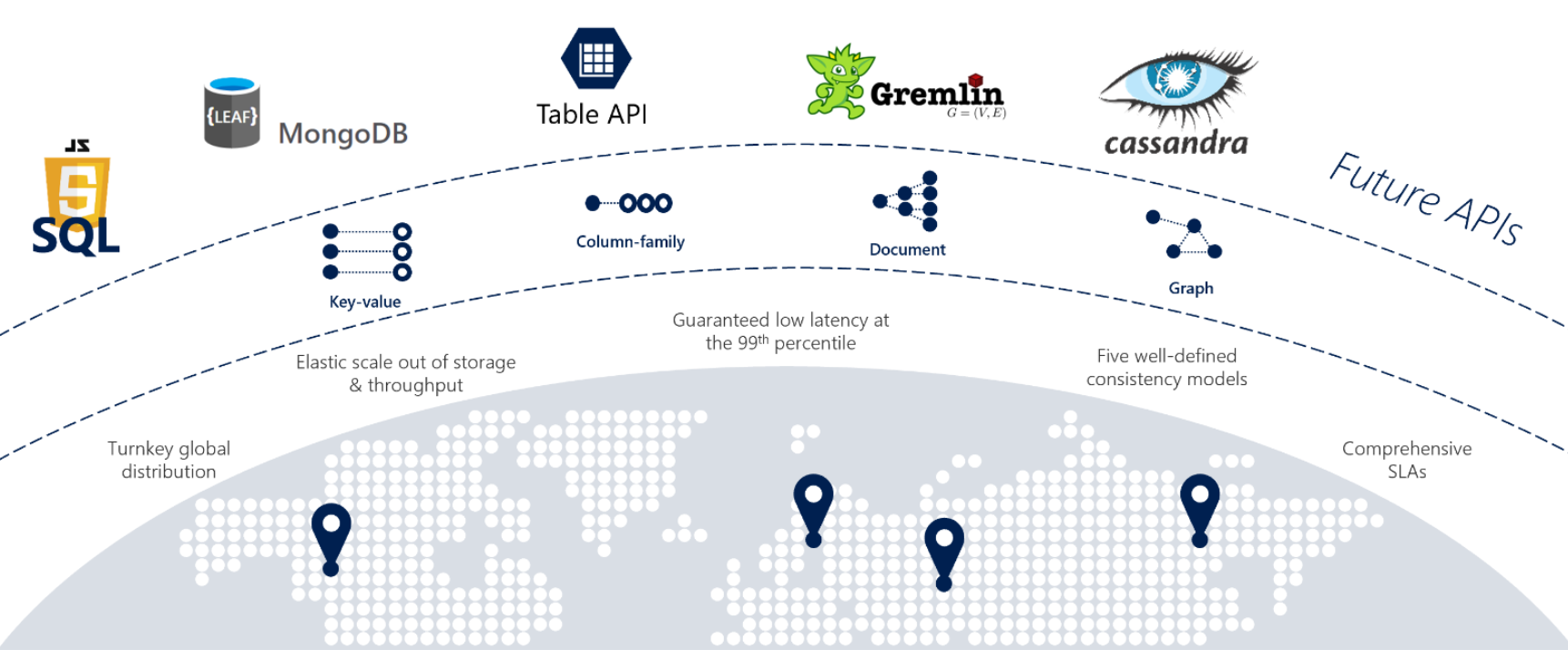
Figura 5-12: Visão geral do Azure Cosmos DB
A figura anterior apresenta muitos dos recursos internos nativos da nuvem disponíveis no Cosmos DB. Nesta seção, vamos dar uma olhada mais de perto neles.
Suporte global
Os aplicativos nativos da nuvem geralmente têm um público global e exigem escala global.
Você pode distribuir bancos de dados Cosmos entre regiões ou ao redor do mundo, colocando dados perto de seus usuários, melhorando o tempo de resposta e reduzindo a latência. Você pode adicionar ou remover um banco de dados de uma região sem pausar ou reimplantar seus serviços. Em segundo plano, o Cosmos DB replica os dados de forma transparente para cada uma das regiões configuradas.
O Cosmos DB suporta clustering ativo/ativo em nível global, permitindo que você configure qualquer uma das regiões do banco de dados para suportar gravações e leituras.
O protocolo de gravação de várias regiões é um recurso importante no Cosmos DB que permite a seguinte funcionalidade:
Escalabilidade ilimitada de gravação elástica e leitura.
99,999% de disponibilidade de leitura e escrita em todo o mundo.
Leituras e gravações garantidas servidas em menos de 10 milissegundos no percentil 99.
Com as APIs Multi-Homing do Cosmos DB, seu microsserviço reconhece automaticamente a região do Azure mais próxima e envia solicitações para ela. A região mais próxima é identificada pelo Cosmos DB sem alterações de configuração. Se uma região ficar indisponível, o recurso Multi-Homing encaminhará automaticamente as solicitações para a próxima região disponível mais próxima.
Suporte a vários modelos
Ao reformular aplicativos monolíticos para uma arquitetura nativa da nuvem, as equipes de desenvolvimento às vezes precisam migrar armazenamentos de dados NoSQL de código aberto. O Cosmos DB pode ajudá-lo a preservar seu investimento nesses armazenamentos de dados NoSQL com sua plataforma de dados multimodelo . A tabela a seguir mostra as APIs de compatibilidade NoSQL suportadas.
| Provider | Description |
|---|---|
| NoSQL API | API para NoSQL armazena dados em formato de documento |
| API do MongoDB | Suporta APIs de banco de dados Mongo e documentos JSON |
| API do Gremlin | Suporta Gremlin API com nós baseados em gráficos e representações de dados de borda |
| API para Cassandra | Suporta Casandra API para representações de dados de coluna ampla |
| API de Tabela | Suporta o Armazenamento de Tabela do Azure com melhorias premium |
| PostgreSQL API | Serviço gerenciado para executar PostgreSQL em qualquer escala |
As equipes de desenvolvimento podem migrar bancos de dados Mongo, Gremlin ou Cassandra existentes para o Cosmos DB com alterações mínimas em dados ou código. Para novos aplicativos, as equipes de desenvolvimento podem escolher entre opções de código aberto ou o modelo interno da API SQL.
Internamente, o Cosmos armazena os dados em um formato struct simples composto por tipos de dados primitivos. Para cada solicitação, o mecanismo de banco de dados converte os dados primitivos na representação do modelo selecionado.
Na tabela anterior, observe a opção API de tabela. Esta API é uma evolução do Armazenamento de Tabela do Azure. Ambos compartilham o mesmo modelo de tabela subjacente, mas a API de Tabela do Cosmos DB adiciona aprimoramentos premium não disponíveis na API de Armazenamento do Azure. A tabela a seguir contrasta os recursos.
| Caraterística | Armazenamento de Tabelas do Azure | Azure Cosmos DB |
|---|---|---|
| Latência | Rápido | Latência de milissegundos de um dígito para leituras e gravações em qualquer lugar do mundo |
| Débito | Limite de 20.000 operações por tabela | Operações ilimitadas por tabela |
| Distribuição Global | Região única com região de leitura secundária única opcional | Distribuições chave na mão para todas as regiões com failover automático |
| Indexação | Disponível apenas para propriedades de partição e chave de linha | Indexação automática de todas as propriedades |
| Preços | Otimizado para cargas de trabalho frias (baixa taxa de transferência: taxa de armazenamento) | Otimizado para cargas de trabalho quentes (alto rendimento: taxa de armazenamento) |
Os microsserviços que consomem o armazenamento de Tabela do Azure podem migrar facilmente para a API de Tabela do Cosmos DB. Não são necessárias alterações de código.
Consistência adaptável
No início da seção Relacional vs. NoSQL, discutimos o assunto da consistência de dados. A consistência dos dados refere-se à integridade dos seus dados. Os serviços nativos da nuvem com dados distribuídos dependem da replicação e devem fazer uma compensação fundamental entre consistência de leitura, disponibilidade e latência.
A maioria dos bancos de dados distribuídos permite que os desenvolvedores escolham entre dois modelos de consistência: consistência forte e consistência eventual. Forte consistência é o padrão ouro de programação de dados. Ele garante que uma consulta sempre retornará os dados mais atuais - mesmo que o sistema deva incorrer em latência aguardando que uma atualização seja replicada em todas as cópias do banco de dados. Enquanto um banco de dados configurado para eventual consistência retornará dados imediatamente, mesmo que esses dados não sejam a cópia mais atual. Esta última opção permite maior disponibilidade, maior escala e maior desempenho.
O Azure Cosmos DB oferece cinco modelos de consistência bem definidos mostrados na Figura 5-13.

Figura 5-13: Níveis de consistência do Cosmos DB
Essas opções permitem que você faça escolhas precisas e compensações granulares para consistência, disponibilidade e desempenho de seus dados. Os níveis são apresentados na tabela seguinte.
| Nível de Consistência | Description |
|---|---|
| Eventual | Sem garantia de encomenda de leituras. As réplicas acabarão por convergir. |
| Prefixo constante | As leituras ainda são eventuais, mas os dados são retornados na ordem em que são gravados. |
| Sessão | Garante que você pode ler todos os dados escritos durante a sessão atual. É o nível de consistência padrão. |
| Ecletismo | Lê gravações de trilha por intervalo especificado. |
| Forte | É garantido que as leituras retornarão a versão confirmada mais recente de um item. Um cliente nunca vê uma leitura parcial ou não comprometida. |
No artigo Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained, o gerente de programas da Microsoft, Jeremy Likness, fornece uma excelente explicação dos cinco modelos.
Criação de partições
O Azure Cosmos DB adota o particionamento automático para dimensionar um banco de dados para atender às necessidades de desempenho de seus serviços nativos da nuvem.
Você gerencia dados em dados do Cosmos DB criando bancos de dados, contêineres e itens.
Os contêineres vivem em um banco de dados do Cosmos DB e representam um agrupamento de itens independente de esquema. Itens são os dados que você adiciona ao contêiner. Eles são representados como documentos, linhas, nós ou bordas. Todos os itens adicionados a um contêiner são indexados automaticamente.
Para particionar o contêiner, os itens são divididos em subconjuntos distintos chamados partições lógicas. As partições lógicas são preenchidas com base no valor de uma chave de partição associada a cada item em um contêiner. A Figura 5-14 mostra dois contêineres, cada um com uma partição lógica baseada em um valor de chave de partição.
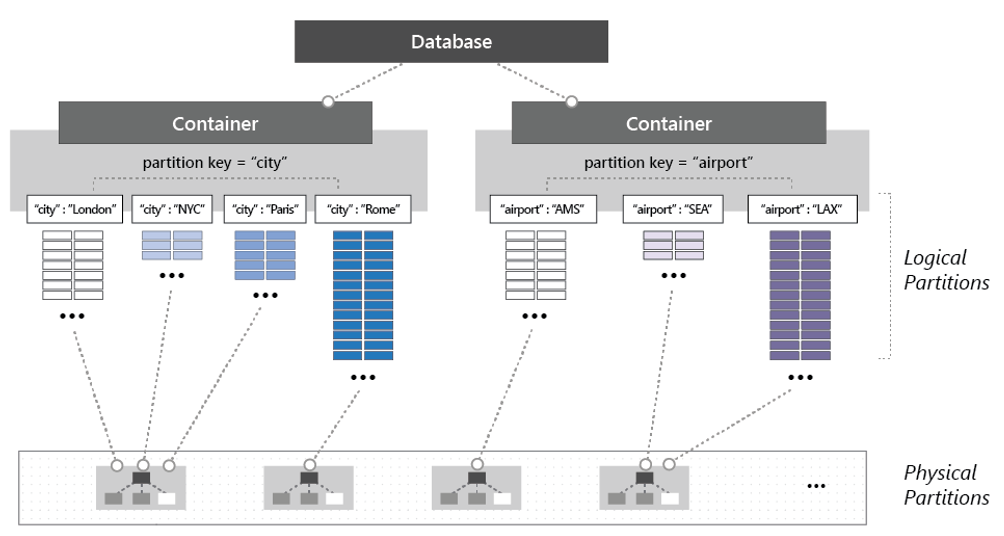
Figura 5-14: Mecânica de particionamento do Cosmos DB
Observe na figura anterior como cada item inclui uma chave de partição de 'cidade' ou 'aeroporto'. A chave determina a partição lógica do item. Itens com um código de cidade são atribuídos ao contêiner à esquerda, e itens com um código de aeroporto, ao contêiner à direita. A combinação do valor da chave de partição com o valor de ID cria o índice de um item, que identifica exclusivamente o item.
Internamente, o Cosmos DB gerencia automaticamente o posicionamento de partições lógicas em partições físicas para satisfazer as necessidades de escalabilidade e desempenho do contêiner. À medida que a taxa de transferência do aplicativo e os requisitos de armazenamento aumentam, o Azure Cosmos DB redistribui partições lógicas em um número maior de servidores. As operações de redistribuição são gerenciadas pelo Cosmos DB e invocadas sem interrupção ou tempo de inatividade.
Bases de dados NewSQL
NewSQL é uma tecnologia de banco de dados emergente que combina a escalabilidade distribuída do NoSQL com as garantias ACID de um banco de dados relacional. Os bancos de dados NewSQL são importantes para sistemas de negócios que devem processar grandes volumes de dados, em ambientes distribuídos, com suporte transacional total e conformidade com ACID. Embora um banco de dados NoSQL possa fornecer escalabilidade maciça, ele não garante a consistência dos dados. Problemas intermitentes de dados inconsistentes podem sobrecarregar a equipe de desenvolvimento. Os desenvolvedores devem construir salvaguardas em seu código de microsserviço para gerenciar problemas causados por dados inconsistentes.
A Cloud Native Computing Foundation (CNCF) apresenta vários projetos de banco de dados NewSQL.
| Project | Características |
|---|---|
| Barata DB | Um banco de dados relacional compatível com ACID que pode ser dimensionado globalmente. Adicione um novo nó a um cluster e o CockroachDB cuida de equilibrar os dados entre instâncias e regiões. Ele cria, gerencia e distribui réplicas para garantir a confiabilidade. É de código aberto e disponível gratuitamente. |
| TiDB | Um banco de dados de código aberto que suporta cargas de trabalho de processamento analítico e transacional híbrido (HTAP). É compatível com MySQL e apresenta escalabilidade horizontal, forte consistência e alta disponibilidade. O TiDB age como um servidor MySQL. Você pode continuar a usar as bibliotecas de cliente MySQL existentes, sem exigir extensas alterações de código em seu aplicativo. |
| YugabyteDB | Um banco de dados SQL distribuído, de código aberto, de alto desempenho. Ele suporta baixa latência de consulta, resiliência contra falhas e distribuição global de dados. O YugabyteDB é compatível com PostgreSQL e lida com RDBMS escalável e cargas de trabalho OLTP em escala de Internet. O produto também suporta NoSQL e é compatível com Cassandra. |
| Vitess | O Vitess é uma solução de banco de dados para implantação, dimensionamento e gerenciamento de grandes clusters de instâncias do MySQL. Ele pode ser executado em uma arquitetura de nuvem pública ou privada. Vitess combina e estende muitos recursos importantes do MySQL e apresenta suporte a fragmentação vertical e horizontal. Originado pelo YouTube, o Vitess atende todo o tráfego do banco de dados do YouTube desde 2011. |
Os projetos de código aberto na figura anterior estão disponíveis na Cloud Native Computing Foundation. Três das ofertas são produtos de banco de dados completos, que incluem suporte a .NET. O outro, Vitess, é um sistema de clustering de banco de dados que dimensiona horizontalmente grandes clusters de instâncias do MySQL.
Um dos principais objetivos de design para bancos de dados NewSQL é trabalhar nativamente no Kubernetes, aproveitando a resiliência e a escalabilidade da plataforma.
Os bancos de dados NewSQL são projetados para prosperar em ambientes de nuvem efêmeros onde as máquinas virtuais subjacentes podem ser reiniciadas ou reagendadas a qualquer momento. Os bancos de dados são projetados para sobreviver a falhas de nó sem perda de dados nem tempo de inatividade. O CockroachDB, por exemplo, é capaz de sobreviver a uma perda de máquina mantendo três réplicas consistentes de quaisquer dados entre os nós em um cluster.
O Kubernetes usa uma construção Services para permitir que um cliente aborde um grupo de processos idênticos de bancos de dados NewSQL a partir de uma única entrada DNS. Ao dissociar as instâncias de banco de dados do endereço do serviço ao qual ele está associado, podemos dimensionar sem interromper as instâncias de aplicativos existentes. Enviar um pedido para qualquer serviço num determinado momento produzirá sempre o mesmo resultado.
Nesse cenário, todas as instâncias de banco de dados são iguais. Não existem relações primárias ou secundárias. Técnicas como a replicação de consenso encontradas no CockroachDB permitem que qualquer nó de banco de dados manipule qualquer solicitação. Se o nó que recebe uma solicitação com balanceamento de carga tiver os dados de que precisa localmente, ele responderá imediatamente. Caso contrário, o nó se torna um gateway e encaminha a solicitação para os nós apropriados para obter a resposta correta. Do ponto de vista do cliente, cada nó de banco de dados é o mesmo: eles aparecem como um único banco de dados lógico com as garantias de consistência de um sistema de máquina única, apesar de ter dezenas ou até centenas de nós que estão trabalhando nos bastidores.
Para obter uma visão detalhada da mecânica por trás dos bancos de dados NewSQL, consulte o artigo DASH: Four Properties of Kubernetes-Native Databases .
Migração de dados para a nuvem
Uma das tarefas mais demoradas é migrar dados de uma plataforma de dados para outra. O Serviço de Migração de Dados do Azure pode ajudar a agilizar esses esforços. Ele pode migrar dados de várias fontes de banco de dados externas para plataformas de Dados do Azure com o mínimo de tempo de inatividade. As plataformas de destino incluem os seguintes serviços:
- Base de Dados SQL do Azure
- Base de Dados do Azure para MySQL
- Azure Database for MariaDB
- Base de Dados do Azure para PostgreSQL
- Azure Cosmos DB
O serviço fornece recomendações para guiá-lo através das alterações necessárias para executar uma migração, pequena ou grande.