O que é o Model Builder e como funciona?
ML.NET Model Builder é uma extensão gráfica intuitiva do Visual Studio para criar, treinar e implantar modelos de aprendizado de máquina personalizados. Ele usa aprendizado de máquina automatizado (AutoML) para explorar diferentes algoritmos e configurações de aprendizado de máquina para ajudá-lo a encontrar o que melhor se adapta ao seu cenário.
Você não precisa de experiência em aprendizado de máquina para usar o Construtor de Modelos. Tudo o que você precisa é de alguns dados e um problema para resolver. O Construtor de Modelos gera o código para adicionar o modelo ao seu aplicativo .NET.

Criar um projeto do Construtor de Modelos
Quando você inicia o Construtor de Modelos pela primeira vez, ele solicita que você nomeie o projeto e, em seguida, cria um mbconfig arquivo de configuração dentro do projeto. O mbconfig arquivo controla tudo o que você faz no Construtor de Modelos para permitir que você reabra a sessão.
Após o treinamento, três arquivos são gerados sob o arquivo *.mbconfig:
- Model.consumption.cs: Este arquivo contém os
ModelInputesquemas eModelOutputbem como aPredictfunção gerada para consumir o modelo. - Model.training.cs: Este arquivo contém o pipeline de treinamento (transformações de dados, algoritmo, hiperparâmetros de algoritmo) escolhido pelo Construtor de Modelos para treinar o modelo. Você pode usar esse pipeline para treinar novamente seu modelo.
- Model.zip: Este é um arquivo zip serializado que representa seu modelo de ML.NET treinado.
Quando cria o mbconfig ficheiro, é-lhe pedido um nome. Esse nome é aplicado aos arquivos de consumo, treinamento e modelo. Neste caso, o nome usado é Model.
Cenário
Você pode trazer muitos cenários diferentes para o Model Builder, para gerar um modelo de aprendizado de máquina para seu aplicativo.
Um cenário é uma descrição do tipo de previsão que você deseja fazer usando seus dados. Por exemplo:
- Preveja o volume futuro de vendas de produtos com base em dados históricos de vendas.
- Classifique os sentimentos como positivos ou negativos com base nas avaliações dos clientes.
- Detetar se uma transação bancária é fraudulenta.
- Encaminhe os problemas de feedback dos clientes para a equipe correta em sua empresa.
Cada cenário é mapeado para uma tarefa de aprendizado de máquina diferente, que inclui:
| Task | Cenário |
|---|---|
| Classificação binária | Classificação de dados |
| Classificação multiclasse | Classificação de dados |
| Classificação de imagens | Classificação de imagens |
| Classificação de textos | Classificação de textos |
| Regressão | Previsão de valor |
| Recomendação | Recomendação |
| Previsão | Previsão |
Por exemplo, o cenário de classificar os sentimentos como positivos ou negativos seria abrangido pela tarefa de classificação binária.
Para obter mais informações sobre as diferentes tarefas de ML suportadas pelo ML.NET consulte Tarefas de aprendizado de máquina no ML.NET.
Qual cenário de aprendizado de máquina é ideal para mim?
No Construtor de Modelos, você precisa selecionar um cenário. O tipo de cenário depende do tipo de previsão que você está tentando fazer.
Tabular
Classificação de dados
A classificação é usada para categorizar os dados em categorias.
Entrada de amostra
Resultado da Amostra
| SepalLength | SepalWidth | Comprimento da pétala | Largura da pétala | Especificar |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| Espécies previstas |
|---|
| Setosa |
Previsão de valor
A previsão de valor, que se enquadra na tarefa de regressão, é usada para prever números.
Entrada de amostra
Resultado da Amostra
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3,8 | DRFP | 17.5 |
| Tarifa prevista |
|---|
| 4,5 |
Recomendação
O cenário de recomendação prevê uma lista de itens sugeridos para um determinado usuário, com base em quão semelhantes seus gostos e desgostos são aos de outros usuários.
Você pode usar o cenário de recomendação quando tiver um conjunto de usuários e um conjunto de "produtos", como itens para comprar, filmes, livros ou programas de TV, juntamente com um conjunto de "classificações" dos usuários desses produtos.
Entrada de amostra
Resultado da Amostra
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| Avaliação prevista |
|---|
| 4,5 |
Previsão
O cenário de previsão utiliza dados históricos com uma série temporal ou uma componente sazonal.
Você pode usar o cenário de previsão para prever a demanda ou a venda de um produto.
Entrada de amostra
Resultado da Amostra
| Date | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| Previsão para 3 dias |
|---|
| [1000,1001,1002] |
Imagem digitalizada
Classificação de imagens
A classificação de imagens é usada para identificar imagens de diferentes categorias. Por exemplo, diferentes tipos de terreno ou animais ou defeitos de fabrico.
Você pode usar o cenário de classificação de imagens se tiver um conjunto de imagens e quiser classificar as imagens em categorias diferentes.
Entrada de amostra
Resultado da Amostra

| Rótulo previsto |
|---|
| Cão |
Deteção de objetos
A deteção de objetos é usada para localizar e categorizar entidades dentro de imagens. Por exemplo, localizar e identificar carros e pessoas em uma imagem.
Você pode usar a deteção de objetos quando as imagens contêm vários objetos de diferentes tipos.
Entrada de amostra
Resultado da Amostra

Processamento de linguagem natural
Classificação de textos
A classificação de texto categoriza a entrada de texto bruto.
Você pode usar o cenário de classificação de texto se tiver um conjunto de documentos ou comentários e quiser classificá-los em categorias diferentes.
Exemplo de entrada
Exemplo de saída
| Rever |
|---|
| Eu realmente gosto deste bife! |
| Sentimento |
|---|
| Positiva |
Environment
Você pode treinar seu modelo de aprendizado de máquina localmente em sua máquina ou na nuvem no Azure, dependendo do cenário.
Quando treina localmente, trabalha dentro das restrições dos recursos do computador (CPU, memória e disco). Quando você treina na nuvem, pode aumentar seus recursos para atender às demandas do seu cenário, especialmente para grandes conjuntos de dados.
| Cenário | Local CPU | Local GPU | Azure |
|---|---|---|---|
| Classificação de dados | ✔️ | ❌ | ❌ |
| Previsão de valor | ✔️ | ❌ | ❌ |
| Recomendação | ✔️ | ❌ | ❌ |
| Previsão | ✔️ | ❌ | ❌ |
| Classificação de imagens | ✔️ | ✔️ | ✔️ |
| Deteção de objetos | ❌ | ❌ | ✔️ |
| Classificação de textos | ✔️ | ✔️ | ❌ |
Dados
Depois de escolher o cenário, o Construtor de Modelos solicita que você forneça um conjunto de dados. Os dados são usados para treinar, avaliar e escolher o melhor modelo para o seu cenário.

O Construtor de Modelos suporta conjuntos de dados nos formatos .tsv, .csv, .txt e banco de dados SQL. Se você tiver um arquivo .txt, as colunas devem ser separadas com ,, ;ou \t.
Se o conjunto de dados for composto por imagens, os tipos de arquivo suportados serão .jpg e .png.
Para obter mais informações, consulte Carregar dados de treinamento no Construtor de Modelos.
Escolha a saída a prever (rótulo)
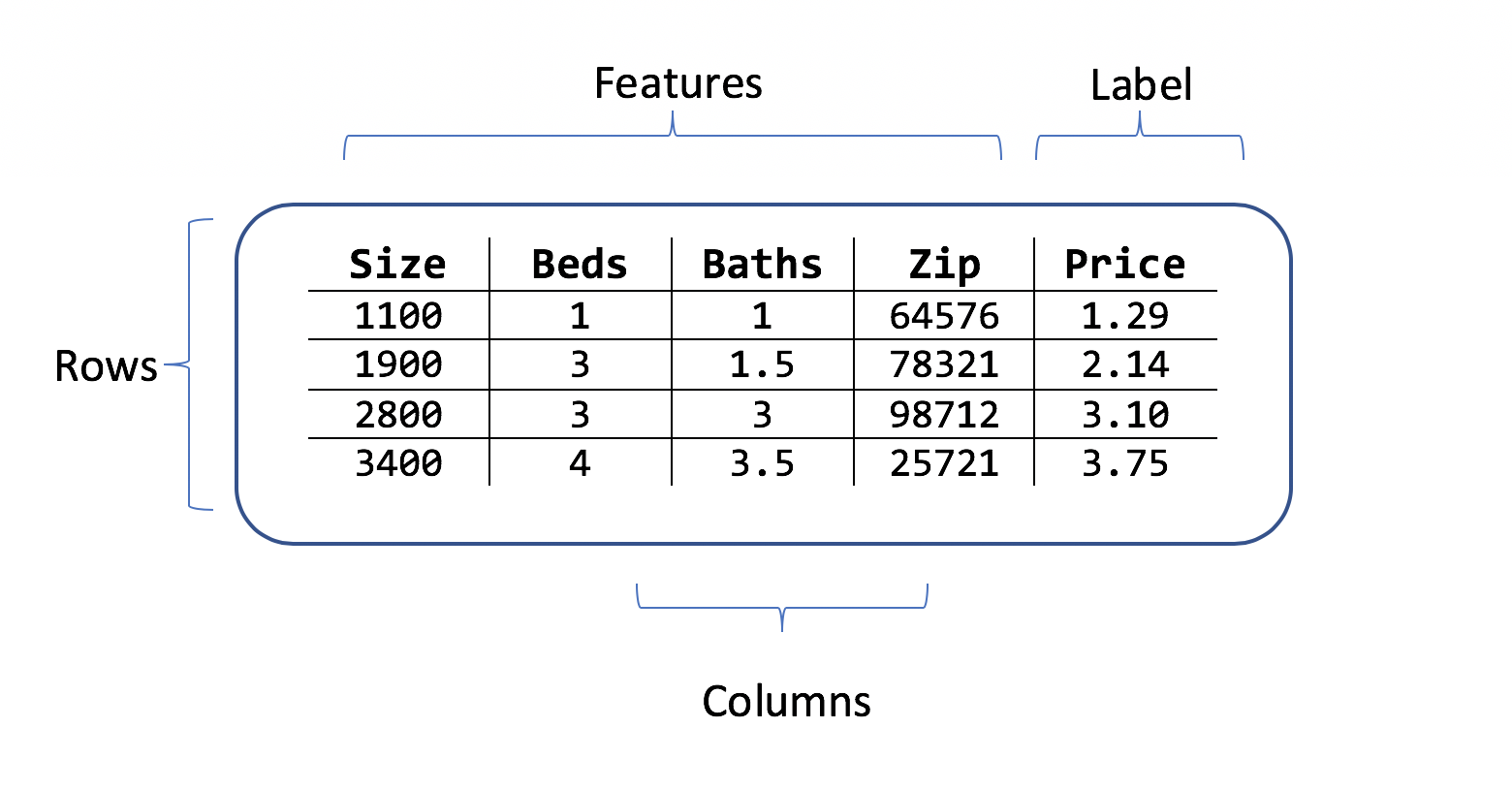
Um conjunto de dados é uma tabela de linhas de exemplos de treinamento e colunas de atributos. Cada linha tem:
- um rótulo (o atributo que você deseja prever)
- recursos (atributos que são usados como entradas para prever o rótulo)
Para o cenário de previsão do preço da casa, as características podem ser:
- A metragem quadrada da casa.
- O número de quartos e banheiros.
- O código postal.
O rótulo é o preço histórico da casa para essa linha de metragem quadrada, valores de quarto e banheiro e código postal.
Exemplos de conjuntos de dados
Se ainda não tiver os seus próprios dados, experimente um destes conjuntos de dados:
| Cenário | Exemplo | Dados | Etiqueta | Funcionalidades |
|---|---|---|---|---|
| Classificação | Prever anomalias de vendas | Dados de vendas de produtos | Vendas de Produtos | Month |
| Prever o sentimento dos comentários do site | Dados de comentários do site | Rótulo (1 quando sentimento negativo, 0 quando positivo) | Comentário, Ano | |
| Preveja transações fraudulentas com cartão de crédito | dados do cartão de crédito | Classe (1 quando fraudulento, 0 caso contrário) | Montante, V1-V28 (recursos anonimizados) | |
| Prever o tipo de problema em um repositório GitHub | Dados de emissão do GitHub | Área | Título, Descrição | |
| Previsão de valor | Prever o preço da tarifa de táxi | Dados da tarifa de táxi | Tarifa | Tempo de viagem, distância |
| Classificação de imagens | Prever a categoria de uma flor | imagens de flores | O tipo de flor: margarida, dente de leão, rosas, girassóis, tulipas | Os próprios dados da imagem |
| Recomendação | Preveja filmes que alguém vai gostar | Classificações de filmes | Usuários, Filmes | Classificações |
Treinar
Depois de selecionar o cenário, o ambiente, os dados e o rótulo, o Construtor de Modelos treina o modelo.
O que é a formação?
O treinamento é um processo automático pelo qual o Construtor de Modelos ensina seu modelo a responder a perguntas para o seu cenário. Uma vez treinado, seu modelo pode fazer previsões com dados de entrada que não viu antes. Por exemplo, se está a prever os preços das casas e uma casa nova chega ao mercado, pode prever o seu preço de venda.
Como o Construtor de Modelos usa aprendizado de máquina automatizado (AutoML), ele não requer nenhuma entrada ou ajuste de você durante o treinamento.
Durante quanto tempo devo treinar?
O Construtor de Modelos usa o AutoML para explorar vários modelos e encontrar o modelo com melhor desempenho.
Períodos de treinamento mais longos permitem que o AutoML explore mais modelos com uma gama mais ampla de configurações.
A tabela abaixo resume o tempo médio necessário para obter um bom desempenho para um conjunto de conjuntos de dados de exemplo, em uma máquina local.
| Tamanho do conjunto de dados | Tempo médio para treinar |
|---|---|
| 0 - 10 MB | 10 s |
| 10 - 100 MB | 10 minutos |
| 100 - 500 MB | 30 minutos |
| 500 - 1 GB | 60 minutos |
| 1 GB+ | 3+ horas |
Estes números são apenas um guia. A duração exata da formação depende de:
- O número de recursos (colunas) que estão sendo usados como entrada para o modelo.
- O tipo de colunas.
- A tarefa de ML.
- O desempenho da CPU, do disco e da memória da máquina usada para treinamento.
É geralmente aconselhável que você use mais de 100 linhas, pois conjuntos de dados com menos do que isso podem não produzir resultados.
Avaliar
A avaliação é o processo de medir o quão bom é o seu modelo. O Construtor de Modelos usa o modelo treinado para fazer previsões com novos dados de teste e, em seguida, mede o quão boas são as previsões.
O Construtor de Modelos divide os dados de treinamento em um conjunto de treinamento e um conjunto de testes. Os dados de treinamento (80%) são usados para treinar seu modelo e os dados de teste (20%) são retidos para avaliar seu modelo.
Como posso entender o desempenho do meu modelo?
Um cenário é mapeado para uma tarefa de aprendizado de máquina. Cada tarefa de ML tem seu próprio conjunto de métricas de avaliação.
Previsão de valor
A métrica padrão para problemas de previsão de valor é RSquared, o valor de RSquared varia entre 0 e 1. 1 é o melhor valor possível, ou seja, quanto mais próximo de 1 for o valor de RSquared, melhor será o desempenho do seu modelo.
Outras métricas relatadas, como perda absoluta, perda quadrada e perda RMS, são métricas adicionais, que podem ser usadas para entender o desempenho do seu modelo e compará-lo com outros modelos de previsão de valor.
Classificação (2 categorias)
A métrica padrão para problemas de classificação é a precisão. A precisão define a proporção de previsões corretas que seu modelo está fazendo sobre o conjunto de dados de teste. Quanto mais próximo de 100% ou 1.0 melhor é.
Outras métricas relatadas, como AUC (Area under the curve), que mede a taxa de positivo verdadeiro versus a taxa de falso positivo devem ser maiores que 0,50 para que os modelos sejam aceitáveis.
Métricas adicionais, como a pontuação F1, podem ser usadas para controlar o equilíbrio entre Precisão e Recall.
Classificação (3+ categorias)
A métrica padrão para a classificação de várias classes é Micro Accuracy. Quanto mais próxima a Micro Accuracy de 100% ou 1.0, melhor ela é.
Outra métrica importante para a classificação Multiclasse é a Macro-precisão, semelhante à Micro-precisão, quanto mais próximo de 1.0 melhor. Uma boa maneira de pensar sobre esses dois tipos de precisão é:
- Micro-precisão: Com que frequência um ticket recebido é classificado para a equipe certa?
- Precisão macro: Para uma equipe média, com que frequência um ticket de entrada é correto para sua equipe?
Mais informações sobre métricas de avaliação
Para obter mais informações, consulte Métricas de avaliação de modelo.
Melhore
Se a pontuação de desempenho do seu modelo não for tão boa quanto você deseja, você pode:
Treine por um longo período de tempo. Com mais tempo, o mecanismo de aprendizado de máquina automatizado experimenta mais algoritmos e configurações.
Adicione mais dados. Às vezes, a quantidade de dados não é suficiente para treinar um modelo de aprendizado de máquina de alta qualidade. Isso é especialmente verdadeiro com conjuntos de dados que têm um pequeno número de exemplos.
Equilibre os seus dados. Para tarefas de classificação, certifique-se de que o conjunto de treinamento esteja equilibrado entre as categorias. Por exemplo, se você tiver quatro classes para 100 exemplos de treinamento e as duas primeiras classes (tag1 e tag2) forem usadas para 90 registros, mas as outras duas (tag3 e tag4) forem usadas apenas nos 10 registros restantes, a falta de dados balanceados pode fazer com que seu modelo tenha dificuldades para prever corretamente tag3 ou tag4.
Consumir
Após a fase de avaliação, o Construtor de Modelos gera um arquivo de modelo e um código que você pode usar para adicionar o modelo ao seu aplicativo. ML.NET modelos são salvos como um arquivo zip. O código para carregar e usar seu modelo é adicionado como um novo projeto em sua solução. O Construtor de Modelos também adiciona um aplicativo de console de exemplo que você pode executar para ver seu modelo em ação.
Além disso, o Construtor de Modelos oferece a opção de criar projetos que consomem seu modelo. Atualmente, o Model Builder criará os seguintes projetos:
- Aplicativo de console: cria um aplicativo de console .NET para fazer previsões a partir do seu modelo.
- API Web: cria uma API Web ASP.NET Core que permite consumir seu modelo pela Internet.
O que se segue?
Instale a extensão do Visual Studio do Construtor de Modelos.
Experimente a previsão de preços ou qualquer cenário de regressão.