Descrição geral de tarefas de importação e exportação de dados
Para criar e gerir trabalhos de importação e exportação de dados, é utilizada a área de trabalho Gestão de dados. Por predefinição, o processo de importação e exportação de dados cria uma tabela de transição para cada entidade na base de dados de destino. As tabelas de transição permitem verificar, limpar ou converter dados antes de os mover.
Nota
Este artigo presume que está familiarizado com entidades de dados.
Processo de importação/exportação de dados
Estes são os passos para importar ou exportar dados.
Crie um trabalho de importação ou exportação onde conclua as seguintes tarefas:
- Definir a categoria de projeto.
- Identificar as entidades a importar ou exportar.
- Definir o formato de dados para o trabalho.
- Sequenciar as entidades, para que sejam processadas em grupos lógicos e numa ordem que faça sentido.
- Determinar se deve utilizar tabelas de transição.
Confirmar que os dados de origem e os dados de destino estão corretamente mapeados.
Verificar a segurança do seu trabalho de importação ou exportação.
Executar o trabalho de importação ou exportação.
Confirmar que o trabalho foi executado como esperado, revendo o histórico de tarefas.
Limpar as tabelas de transição.
As restantes secções deste artigo fornecem mais informações sobre cada passo do processo.
Nota
Para atualizar o formulário de Importação/exportação de dados para ver os últimos progressos, utilize o ícone de atualização do formulário. A atualização do nível do browser não é recomendada, porque interrompe quaisquer trabalhos de importação/exportação que não sejam executados num lote.
Criar um trabalho de importação ou exportação
Um trabalho de importação ou exportação de dados pode ser executado uma ou muitas vezes.
Definir a categoria de projeto
Recomendamos que tome o tempo necessário para selecionar uma categoria de projeto adequada para o seu trabalho de importação ou exportação. As categorias de projetos podem ajudá-lo a gerir trabalhos relacionados.
Identificar as entidades a importar ou exportar
Pode adicionar entidades específicas a um trabalho de importação ou exportação ou selecionar um modelo para aplicar. Os modelos preenchem um trabalho com uma lista de entidades. A opção Aplicar modelo está disponível depois de dar um nome ao trabalho e guardar o trabalho.
Definir o formato de dados para o trabalho
Quando seleciona uma entidade, tem de selecionar o formato dos dados que são exportados ou importados. Define os formatos utilizando o mosaico Configuração de origens de dados. Um formato de origem de dados é uma combinação de Tipo, Formato de ficheiro, Delimitador de linha e Delimitador de coluna. Há outros, mas estes atributos são os atributos principais a compreender. A tabela seguinte lista as combinações válidas.
| Formato de Ficheiro | Delimitador de Linha/Coluna | Estilo XML |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-Elemento XML-Atributo |
| Largura delimitada e fixa | Vírgula, ponto e vírgula, separador, barra vertical, dois pontos | -NA- |
Nota
É importante selecionar o valor correto para Delimitador de linha, Delimitador de coluna e Qualificador de texto, se a opção Formato de ficheiro estiver definida como Delimitado. Certifique-se de que os seus dados não contêm o caráter utilizado como delimitador ou qualificador, pois isso pode resultar em erros durante a importação e exportação.
Nota
Para formatos de ficheiro baseados em XML, certifique-se de que usa apenas carateres legais. Para obter mais informações sobre carateres válidos, consulte Carateres Válidos em XML 1.0. O XML 1.0 não permite carateres de controlo, exceto para tabulações, devoluções de transporte e feeds de linha. Exemplos de carateres ilegais são parênteses retos, chavetas e barras invertidas.
Para importar ou exportar dados, use Unicode em vez de uma página de código específica. Isto ajuda a fornecer resultados mais consistentes e a eliminar falhas nas tarefas de gestão de dados porque incluem carateres Unicode. Todos os formatos de dados de origem definidos pelo sistema que usam Unicode têm todos Unicode no nome de origem. O formato Unicode é aplicado ao selecionar uma página de código ANSI com codificação Unicode como Página de código no separador Definições regionais. Selecione uma das seguintes páginas de código para Unicode:
| Página de código | Nome a apresentar |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Para obter mais informações sobre páginas de código, consulte Identificadores de Página de Código.
Sequenciar as entidades
As entidades podem ser sequenciadas num modelo de dados ou em trabalhos de importação e exportação. Quando executa um trabalho que contém mais do que uma entidade de dados, tem de se certificar de que as entidades de dados estão corretamente sequenciadas. Sequencia entidades principalmente para poder resolver quaisquer dependências funcionais entre entidades. Se as entidades não tiverem quaisquer dependências funcionais, podem ser programadas para importação ou exportação paralelas.
Unidades de execução, níveis e sequências
A unidade de execução, o nível na unidade de execução e a sequência de uma entidade ajudam a controlar a ordem por que os dados são exportados ou importados.
- Em cada unidade de execução, as entidades são processadas em paralelo.
- Em cada unidade de execução, as entidades são processadas em paralelo se tiverem o mesmo nível.
- Em cada nível, as entidades são processadas de acordo com o seu número de sequência nesse nível.
- Depois de um nível ser processado, o nível seguinte é processado.
Resequenciação
Pode pretender resequenciar as suas entidades nas seguintes situações:
- Se for utilizado apenas um trabalho de dados para todas as suas alterações, pode utilizar opções de resequenciação para otimizar o tempo de execução do trabalho completo. Nestes casos, pode utilizar a unidade de execução para representar o módulo, o nível para representar a área de funcionalidade do módulo e a sequência para representar a entidade. Utilizando esta abordagem, pode trabalhar em vários módulos em paralelo, e continuar a trabalhar em sequência num módulo. Para ajudar a garantir que as operações paralelas sejam bem-sucedidas, tem de considerar todas as dependências.
- Se forem utilizados vários trabalhos de dados (por exemplo, um trabalho para cada módulo), pode utilizar a sequenciação para afetar o nível e a sequência de entidades para uma execução ótima.
- Se não houver dependências, pode sequenciar entidades em diferentes unidades de execução para máxima otimização.
O menu Resequenciação está disponível quando são selecionadas várias entidades. Pode resequenciar com base em opções de unidade de execução, nível ou sequência. Pode definir um incremento para resequenciar as entidades que estão selecionadas. O número de unidade, nível e/ou sequência selecionado para cada entidade é atualizado pelo incremento especificado.
Ordenação
A utilização pode utilizar a opção Ordenar por para visualizar a lista de entidades por ordem sequencial.
Truncar
Para projetos de importação, pode optar por truncar registos nas entidades antes de importar. Truncar é útil se os seus registos tiverem de ser importados para um conjunto de tabelas limpo. Esta definição está desativada por predefinição.
Confirmar que os dados de origem e os dados de destino estão corretamente mapeados
O mapeamento é uma função que se aplica tanto a trabalhos de importação, como de exportação.
- No contexto de um trabalho de importação, o mapeamento descreve que colunas do ficheiro de origem se tornam nas colunas da tabela de transição. Por conseguinte, o sistema pode determinar quais os dados da coluna do ficheiro de origem que devem ser copiados para que coluna da tabela de transição.
- No contexto de um trabalho de exportação, o mapeamento descreve que colunas do ficheiro de transição (ou seja, a origem) se tornam nas colunas do ficheiro de destino.
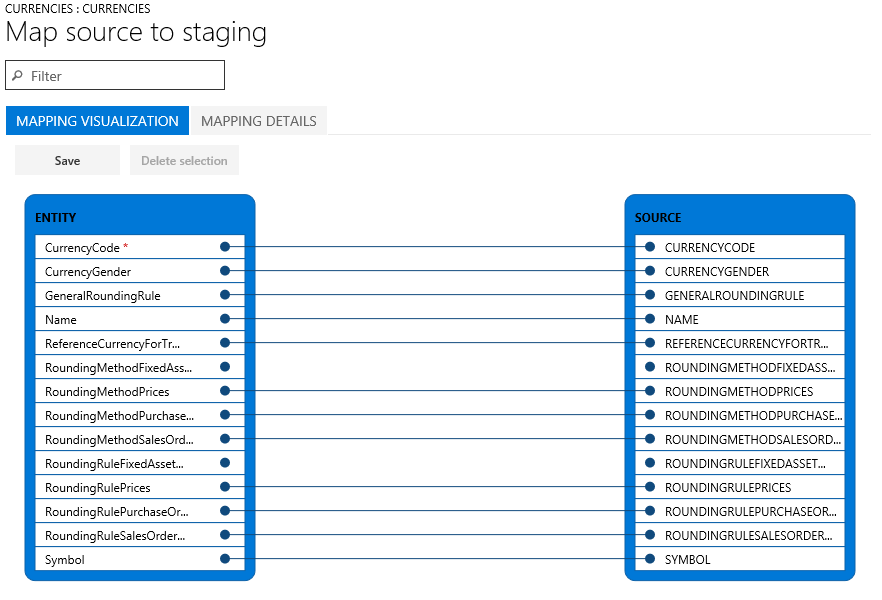
Se os nomes das colunas na tabela de transição e o ficheiro corresponderem, o sistema estabelece automaticamente o mapeamento, com base nos nomes. No entanto, se os nomes diferirem, as colunas não são mapeadas automaticamente. Nestes casos, tem de concluir o mapeamento selecionando a opção 'Ver mapa ' na entidade do trabalho de dados.
Existem duas vistas de mapeamento: Visualização de mapeamento, que é a vista predefinida, e Detalhes de mapeamento. Um asterisco vermelho (*) identifica quaisquer campos obrigatórios na entidade. Estes campos têm de ser mapeados antes de ser possível trabalhar com a entidade. Pode anular o mapeamento de outros campos conforme necessário quando trabalha com a entidade. Para anular o mapeamento de um campo, selecione o campo na coluna Entidade ou na coluna Origem e, em seguida, selecione Eliminar seleção. Selecione Guardar para guardar as suas alterações e, em seguida, feche a página para voltar ao projeto. Pode utilizar o mesmo processo para editar o mapeamento de campos da origem para transição após a sua importação.
Pode gerar um mapeamento na página selecionando Gerar mapeamento da origem. Um mapeamento gerado comporta-se como um mapeamento automático. Portanto, tem de mapear manualmente quaisquer campos não mapeados.
Verificar a segurança do seu trabalho de importação ou exportação
O acesso à área de trabalho de Gestão de dados pode ser restringido, para que os utilizadores não administradores possam aceder apenas a trabalhos de dados específicos. O acesso a um trabalho de dados implica o acesso total ao histórico de execução desse trabalho e o acesso às tabelas de transição. Por isso, deve certificar-se de que existem controlos de acesso adequados quando cria um trabalho de dados.
Proteger um trabalho por funções e utilizadores
Utilize o menu Funções aplicáveis para restringir o trabalho a uma ou mais funções de segurança. Apenas os utilizadores com essas funções têm acesso ao trabalho.
Também pode restringir um trabalho a utilizadores específicos. Quando protege um trabalho por utilizadores em vez de funções, há mais controlo se vários utilizadores forem atribuídos a uma função.
Proteger um emprego por entidade legal
Os trabalhos de dados são de natureza global. Assim, se um trabalho de dados foi criado e utilizado numa entidade legal, esse trabalho está visível noutras entidades legais do sistema. Este comportamento predefinido pode ser preferido nalguns cenários de aplicação. Por exemplo, uma organização que importa faturas utilizando entidades de dados pode fornecer uma equipa centralizada de processamento de faturas que é responsável pela gestão de erros de faturação para todas as divisões da organização. Neste cenário, é útil que a equipa centralizada de processamento de faturas tenha acesso aos trabalhos de importação de faturas de todas as entidades legais. Assim, o comportamento predefinido cumpre o requisito do ponto de vista da entidade legal.
No entanto, uma organização pode querer ter equipas de processamento de faturas distribuídas por entidade legal. Neste caso, uma equipa de uma entidade legal deve ter acesso apenas aos trabalhos de importação de faturas na sua própria entidade legal. Para cumprir este requisito, pode configurar o controlo de acesso baseado em entidades legais sobre os trabalhos de dados, utilizando o menu Entidades legais aplicáveis dentro do trabalho de dados. Depois de a configuração ser feita, os utilizadores só podem ver os trabalhos que estão disponíveis na entidade legal em que têm atualmente sessão iniciada. Para ver trabalhos de outra entidade legal, os utilizadores têm de mudar para essa entidade legal.
Um trabalho pode ser protegido por funções, utilizadores e entidade legal ao mesmo tempo.
Executar o trabalho de importação ou exportação
Pode executar um trabalho uma vez selecionando o botão Importar ou Exportar depois de definir o trabalho. Para configurar um trabalho recorrente, selecione Criar um trabalho de dados recorrente.
Nota
Um trabalho de importação ou exportação pode ser executado selecionando o botão Importar ou Exportar. Esta ação agenda uma tarefa de lote para executar apenas uma vez. A tarefa pode não ser executada imediatamente se o serviço de lote estiver limitado devido à carga no serviço de lote. Os trabalhos também podem ser executados de forma sincronizada selecionando Importar agora ou Exportar agora. Isto inicia o trabalho imediatamente e é útil se o lote não começar devido a limitação. Os trabalhos também podem ser agendados para serem executados mais tarde. Isto pode ser feito escolhendo a opção Executar em lote. Os recursos de lote estão sujeitos a limitações, por isso a tarefa de lote pode não começar imediatamente. A utilização de um lote é a opção recomendada, pois também ajuda com grandes volumes de dados que tenham de ser importados ou exportados. As tarefas de lote podem ser agendadas para serem executadas num grupo de lotes específico, o que permite um maior controlo do ponto de vista do equilíbrio da carga.
Confirmar que o trabalho foi executado como esperado
O histórico de trabalhos está disponível para a resolução de problemas e investigação sobre os trabalhos tanto de importação, como de exportação. Os trabalhos do histórico estão organizados por intervalos de tempo.

Cada trabalho executado disponibiliza os detalhes seguintes:
- Detalhes de execução
- Registo de execução
Os detalhes de execução mostram o estado de cada entidade de dados que o trabalho processou. Assim, pode encontrar rapidamente as seguintes informações:
- As entidades que foram processadas.
- Para uma entidade, quantos registos foram processados com êxito e quantos falharam.
- Os registos de transição de cada entidade.
Pode transferir os dados de transição para um ficheiro para trabalhos de exportação, ou pode transferi-los como um pacote para trabalhos de importação e exportação.
A partir dos detalhes de execução, também pode abrir o registo de execução.
Importações paralelas
Para acelerar a importação de dados, o processamento paralelo da importação de um ficheiro pode ser ativado se a entidade suportar importações paralelas. Para configurar a importação paralela para uma entidade, devem ser seguidos os passos seguintes.
Aceda a Administração do sistema > Áreas de trabalho > Gestão de dados.
Na secção Importar/Exportar, selecione o mosaico Parâmetros da estrutura para abrir a página Parâmetros da estrutura de importação/exportação de dados.
No separador Definições de entidade, selecione Configurar parâmetros de execução da entidade para abrir a página Parâmetros de execução de importação da entidade.
Defina os seguintes campos para configurar a importação paralela para uma entidade:
- No campo Entidade, selecione a entidade. Se o campo da entidade estiver vazio, o valor vazio será utilizado como a predefinição para todas as importações subsequentes, se a entidade suportar importação paralela.
- No campo Contagem de registos de limiar de importação, introduza a contagem de registos de limiar para importação. Isto determina a contagem de registos a ser processada por um tópico. Se um ficheiro tiver mais de 10 mil registos, uma contagem de registos de 2.500 com uma contagem de tarefas de quatro significa que cada tópico processa 2.500 registos.
- No campo de Contagem de tarefas de importação, introduza a contagem de tarefas de importação. Esta contagem não pode exceder o máximo de tópicos de lote atribuídos para processamento de lote em Administração do sistema >Configuração do servidor.
Nota
A adição de muitas tarefas paralelas faz com que a infraestrutura subjacente use a capacidade de recursos em 100% e afete o desempenho do ambiente e outras operações. É sugerido que compreenda a capacidade de recursos do ambiente e do consumo com base nas tarefas de importação paralela configuradas e limite o número de tarefas.
Limpeza do histórico de tarefas
Por predefinição, as entradas do histórico de tarefas e os dados da tabela de teste relacionados com mais de 90 dias são eliminados automaticamente. A funcionalidade de limpeza do histórico de tarefas na gestão de dados pode ser usada para configurar limpeza periódica do histórico de execução com um período de retenção inferior a esta predefinição. Esta funcionalidade substitui a funcionalidade de limpeza da tabela de transição anterior, que é agora preterida. As tabelas seguintes são limpas pelo processo de limpeza.
Todas as tabelas de transição
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
A caraterística Limpeza do histórico de execução é acedida em Gestão de dados > Limpeza do histórico de tarefas.
Parâmetros de agendamento
Quando agenda o processo de limpeza, têm de ser especificados os parâmetros seguintes para definir os critérios de limpeza.
Número de dias para reter o histórico – Esta definição é utilizada para controlar a quantidade de histórico de execução a preservar. O histórico é especificado em número de dias. Quando o trabalho de limpeza é agendado como uma tarefa de lote recorrente, esta definição funciona como uma janela em movimento contínuo, deixando sempre o histórico do número especificado de dias intacto, enquanto elimina o resto. O valor predefinido é de sete dias.
Número de horas para executar o trabalho — Dependendo da quantidade de histórico a limpar, o tempo total de execução para o trabalho de limpeza pode variar de alguns minutos a algumas horas. Este parâmetro tem de ser definido como o número de horas que o trabalho executa. Após o trabalho de limpeza ter sido executado durante o número especificado de horas, o trabalho sai e retoma a limpeza da próxima vez que for executado com base na agenda de recorrência.
Pode ser especificado um tempo máximo de execução definindo um limite máximo de número de horas que o trabalho deve ser executado utilizando esta definição. A lógica de limpeza passa por um ID de execução de trabalho de cada vez numa sequência disposta cronologicamente, com o mais antigo a ser o primeiro para a limpeza do histórico de execução relacionado. Deixa de recolher novos IDs de execução para limpeza quando a duração de execução restante se aproximar dos últimos 10% da duração especificada. Nalguns casos, o trabalho de limpeza continua para além do tempo máximo especificado. Esta duração depende em grande parte do número de registos a eliminar para o ID de execução atual que foi iniciado antes de o limiar de 10% ter sido atingido. A limpeza iniciada tem de ser concluída para garantir a integridade dos dados, o que significa que a limpeza continua apesar de exceder o limite especificado. Quando concluído, não são recolhidos novos IDs de execução e o trabalho de limpeza é concluído. O histórico de execução restante que não foi limpo por falta de tempo de execução suficiente, é recolhido da próxima vez que o trabalho de limpeza estiver agendado. O valor predefinido e mínimo para esta definição está definido para 2 horas.
Lote recorrente — O trabalho de limpeza pode ser executado como uma execução manual única, ou também pode ser agendado para execução recorrente em lote. O lote pode ser agendado utilizando as definições Executar em segundo plano, que é a configuração de lote padrão.
Nota
Se a caraterística de Limpeza do histórico de tarefas não for usada, o histórico de execução com mais de 90 dias ainda será eliminado automaticamente. A limpeza do histórico de tarefas pode ser executada para além desta eliminação automática. Certifique-se de que o trabalho de limpeza está agendado para ser executado com periodicidade. Como explicado acima, em qualquer execução de limpeza o trabalho só limpa o maior número de IDs de execução possível, dentro do máximo de horas indicado.
Limpeza do histórico de trabalhos e arquivo
A funcionalidade de limpeza do histórico de trabalhos e arquivo substitui as versões anteriores da funcionalidade de limpeza. Esta secção explica estas novas capacidades.
Uma das principais alterações na funcionalidade de limpeza é a utilização da tarefa de lote do sistema para limpar o histórico. A utilização da tarefa de lote do sistema permite que as aplicações de finanças e operações tenham a tarefa de lote de limpeza agendada automaticamente e em execução assim que o sistema estiver pronto. Já não é necessário agendar a tarefa de lote manualmente. Neste modo de execução predefinido, a tarefa de lote é executada a cada hora, começando à meia-noite, e retém o histórico de execução dos últimos sete dias. O histórico purgado é arquivado para futura recuperação. A partir da versão 10.0.20, esta funcionalidade está sempre ativada.
A segunda alteração no processo de limpeza é o arquivo do histórico de execução purgado. O trabalho de limpeza arquiva os registos eliminados para o armazenamento de blobs que o DIXF utiliza para integrações regulares. O ficheiro arquivado está no formato de pacote DIXF e está disponível durante sete dias no blob, período durante o qual pode ser transferido. A longevidade predefinida de sete dias para o ficheiro arquivado pode ser alterada para um máximo de 90 dias nos parâmetros.
Alterar as predefinições
Esta funcionalidade encontra-se atualmente em pré-visualização e tem de ser ativada explicitamente, ativando a disponibilização como piloto DMFEnableExecutionHistoryCleanupSystemJob. A caraterística de limpeza de teste também tem de ser acionada à gestão de caraterísticas.
Para alterar a predefinição para a longevidade do ficheiro arquivado, aceda à área de trabalho de gestão de dados e selecione Limpeza do histórico de trabalhos. Defina Dias para reter o pacote no blob para um valor entre 7 e 90 (inclusive). Esta alteração entra em vigor nos arquivos que são criados após efetuar esta alteração.
Transferir o pacote arquivado
Esta funcionalidade encontra-se atualmente em pré-visualização e tem de ser ativada explicitamente, ativando a disponibilização como piloto DMFEnableExecutionHistoryCleanupSystemJob. A caraterística de limpeza de teste também tem de ser acionada à gestão de caraterísticas.
Para transferir o histórico de execuções arquivado, aceda à área de trabalho de gestão de dados e selecione Limpeza do histórico de trabalhos. Selecione Pacote de cópia de segurança do histórico para abrir o formulário do histórico. Este formulário mostra a lista de todos os pacotes arquivados. Um arquivo pode ser selecionado e transferido selecionando Transferir pacote. O pacote transferido está no formato de pacote DIXF e contém os seguintes ficheiros:
- O ficheiro da tabela de transição da entidade
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Ordenar dados de entidades compostas usando xslt
Esta funcionalidade permite-lhe exportar uma entidade composta e aplicar um ficheiro xslt para ordenar os dados no ficheiro xml.
Para ordenar dados de entidades compostas usando xslt, siga estes passos.
- Crie um ficheiro xslt para ordenar os dados no formato XML. Por exemplo, se tiver um ficheiro XSLT para a entidade de origem composta Nota de encomenda V3, poderá ordenar os dados do formato de atributo XML por ordem por INVOICEVENDORACCOUNTNUMBER para PURCHPURCHASEORDERHEADERV2ENTITY e ordenar por LINENUMBER para PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Aceda à área de trabalho Gestão de dados.
- Na lista de projetos de exportação de dados, selecione um projeto com origem de dados XML e selecione Ver mapa.
- Selecione Ver mapa para qualquer entidade.
- Aceda ao separador Transformações
- Selecione Novo e carregue o ficheiro xslt criado no passo 1.