Definições de configuração de computação do Spark em ambientes de malha
As experiências de Engenharia de Dados e Ciência de Dados do Microsoft Fabric operam em uma plataforma de computação Spark totalmente gerenciada. Esta plataforma foi concebida para proporcionar uma velocidade e eficiência incomparáveis. Inclui piscinas iniciais e piscinas personalizadas.
Um ambiente de malha contém uma coleção de configurações, incluindo propriedades de computação do Spark que permitem que os usuários configurem a sessão do Spark depois de serem anexados a blocos de anotações e trabalhos do Spark. Com um ambiente, você tem uma maneira flexível de personalizar as configurações de computação para executar seus trabalhos do Spark. Em um ambiente, a seção de computação permite configurar as propriedades de nível de sessão do Spark para personalizar a memória e os núcleos dos executores com base nos requisitos de carga de trabalho.
Os administradores de espaço de trabalho podem habilitar ou desabilitar personalizações de computação com a opção Personalizar configurações de computação para itens na guia Pool da seção Engenharia de Dados/Ciência na tela Configurações do espaço de trabalho.
Os administradores do espaço de trabalho podem delegar aos membros e colaboradores a alteração das configurações de computação de nível de sessão padrão no ambiente s Fabric habilitando essa configuração.
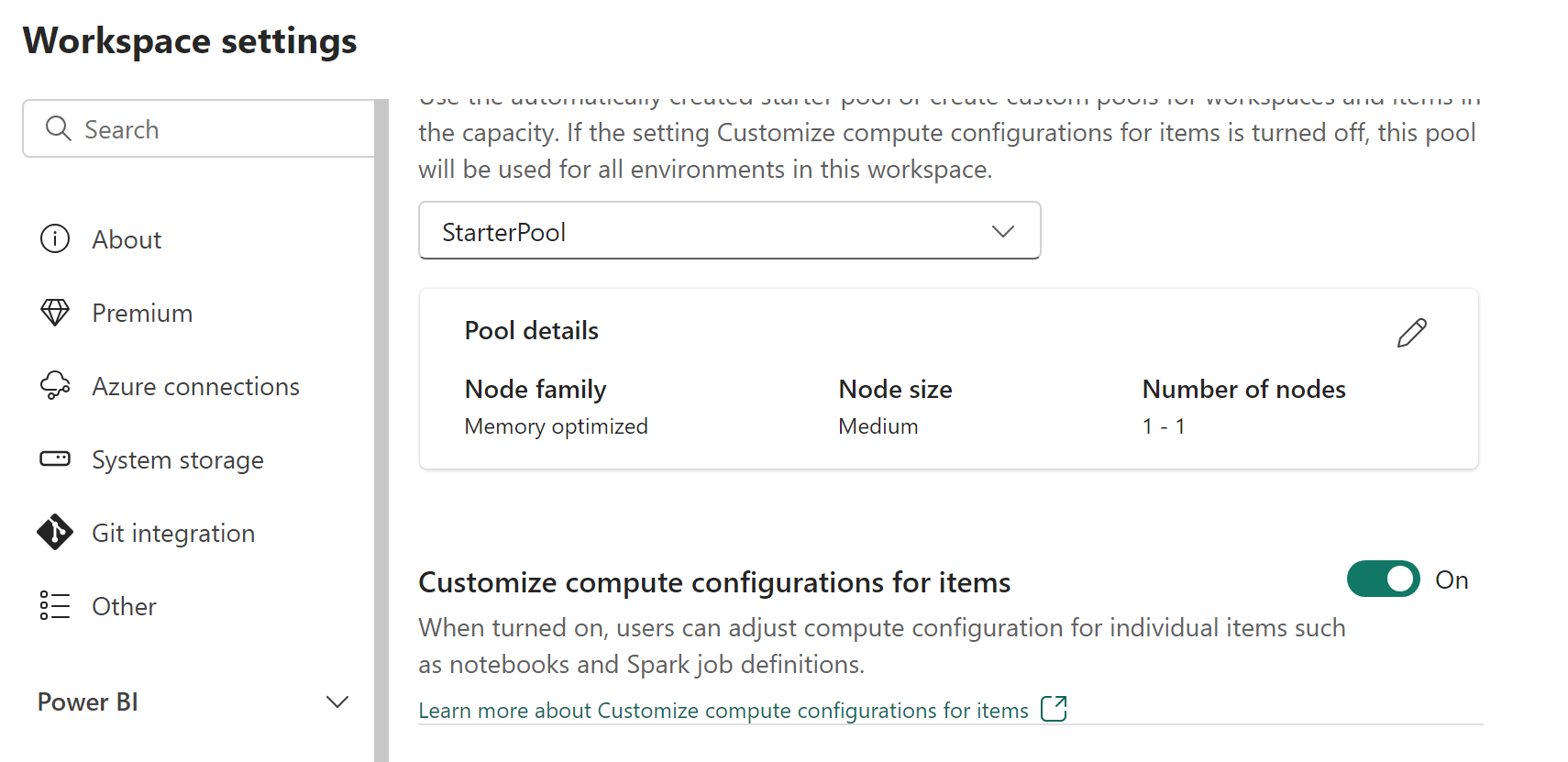
Se o administrador do espaço de trabalho desativar essa opção nas configurações do espaço de trabalho, a seção de computação do ambiente será desabilitada e as configurações de computação do pool padrão para o espaço de trabalho serão usadas para executar trabalhos do Spark.
Personalizando propriedades de computação no nível da sessão em um ambiente
Como usuário, você pode selecionar um pool para o ambiente na lista de pools disponíveis no espaço de trabalho Malha. O administrador do espaço de trabalho Malha cria o pool inicial padrão e os pools personalizados.
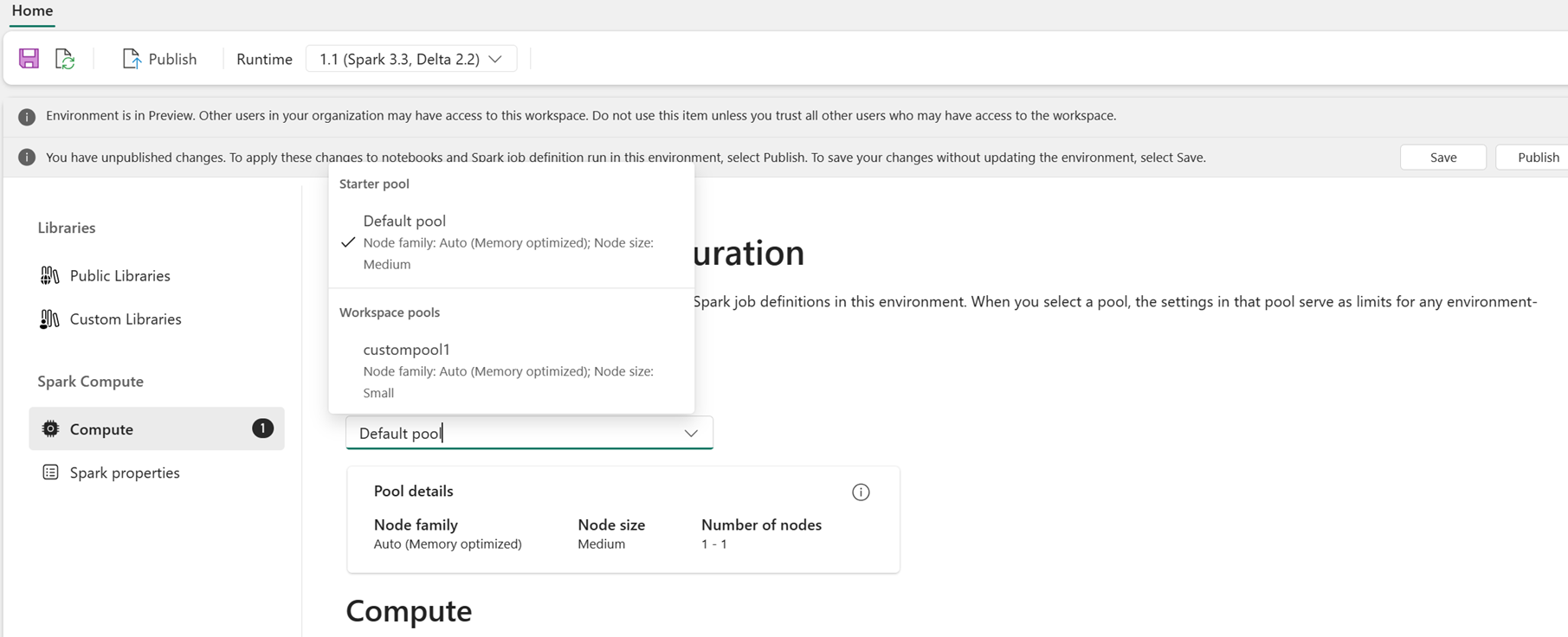
Depois de selecionar um pool na seção Computação , você pode ajustar os núcleos e a memória para os executores dentro dos limites dos tamanhos e limites dos nós do pool selecionado.
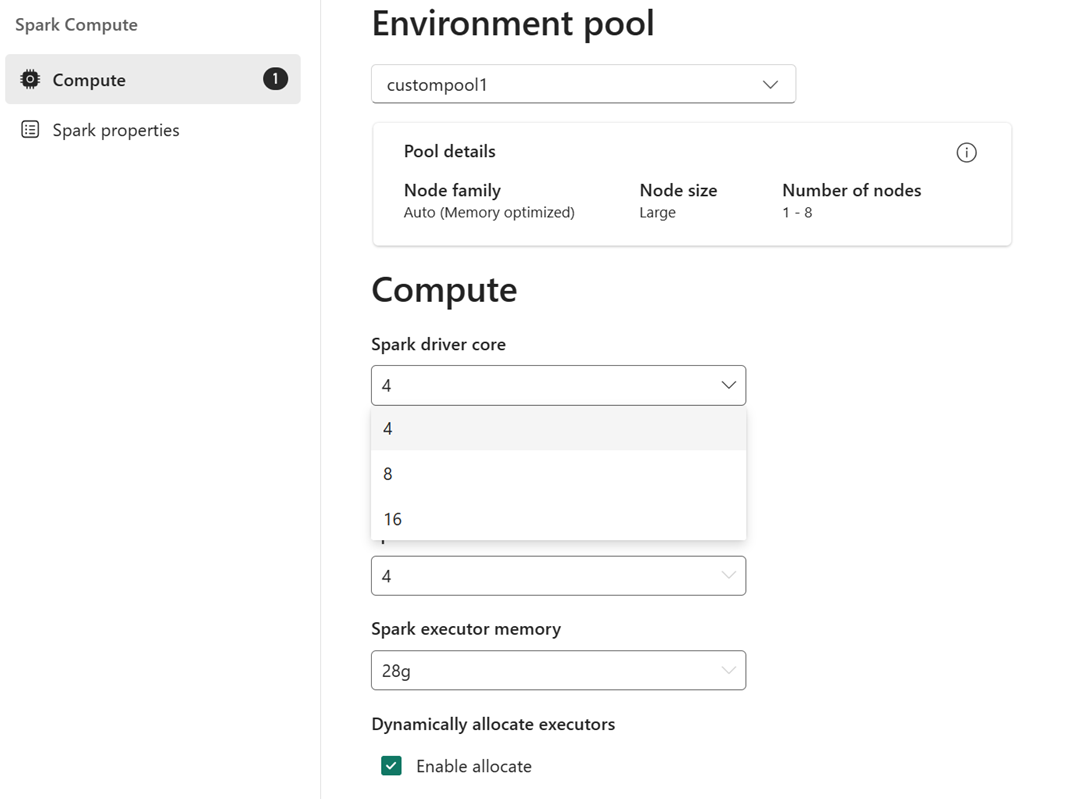
Por exemplo: você seleciona um pool personalizado com tamanho de nó grande, que é 16 Spark vCores, como o pool de ambiente. Você pode então escolher o núcleo do driver/executor para ser 4, 8 ou 16, com base no seu requisito de nível de trabalho. Para a memória alocada para driver e executores, você pode escolher 28 g, 56 g ou 112 g, que estão todos dentro dos limites de um grande limite de memória de nó.
Para obter mais informações sobre tamanhos de computação do Spark e seus núcleos ou opções de memória, consulte O que é a computação do Spark no Microsoft Fabric?.