Tempos de execução do Apache Spark na malha
O Microsoft Fabric Runtime é uma plataforma integrada ao Azure baseada no Apache Spark que permite a execução e o gerenciamento de experiências de engenharia de dados e ciência de dados. Ele combina componentes-chave de fontes internas e de código aberto, fornecendo aos clientes uma solução abrangente. Para simplificar, nos referimos ao Microsoft Fabric Runtime powered by Apache Spark como Fabric Runtime.
Principais componentes do Fabric Runtime:
Apache Spark - uma poderosa biblioteca de computação distribuída de código aberto que permite processamento de dados em grande escala e tarefas de análise. O Apache Spark fornece uma plataforma versátil e de alto desempenho para experiências de engenharia de dados e ciência de dados.
Delta Lake - uma camada de armazenamento de código aberto que traz transações ACID e outros recursos de confiabilidade de dados para o Apache Spark. Integrado ao Fabric Runtime, o Delta Lake aprimora os recursos de processamento de dados e garante a consistência dos dados em várias operações simultâneas.
Pacotes de nível padrão para Java/Scala, Python e R - pacotes que suportam diversas linguagens de programação e ambientes. Esses pacotes são instalados e configurados automaticamente, permitindo que os desenvolvedores apliquem suas linguagens de programação preferidas para tarefas de processamento de dados.
O Microsoft Fabric Runtime é construído sobre um sistema operacional de código aberto robusto, garantindo compatibilidade com várias configurações de hardware e requisitos do sistema.
Abaixo, você encontra uma comparação abrangente dos principais componentes, incluindo versões do Apache Spark, sistemas operacionais suportados, Java, Scala, Python, Delta Lake e R, para Runtime 1.1 e Runtime 1.2 dentro da plataforma Microsoft Fabric.
Gorjeta
Use sempre a versão mais recente do tempo de execução do GA para sua carga de trabalho de produção, que atualmente é o Runtime 1.2.
| Tempo de execução 1.1 | Tempo de execução 1.2 | Tempo de execução 1.3 | |
|---|---|---|---|
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Sistema operativo | Ubuntu 18.04 | Mariner 2,0 | Mariner 2,0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3,10 | 3,10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.1 |
| R | 4.2.2 | 4.2.2 | 4.3.3 |
Visite Runtime 1.1, Runtime 1.2 ou Runtime 1.3 para explorar detalhes, novos recursos, melhorias e cenários de migração para a versão específica do tempo de execução.
Otimizações de malha
No Microsoft Fabric, tanto o mecanismo Spark quanto as implementações Delta Lake incorporam otimizações e recursos específicos da plataforma. Esses recursos são projetados para usar integrações nativas dentro da plataforma. É importante notar que todos esses recursos podem ser desativados para alcançar a funcionalidade padrão do Spark e Delta Lake. Os tempos de execução do Fabric para Apache Spark abrangem:
- A versão open-source completa do Apache Spark.
- Uma coleção de quase 100 aprimoramentos de desempenho de consulta distintos e integrados. Esses aprimoramentos incluem recursos como cache de partição (habilitando o cache de partição do Sistema de Arquivos para reduzir chamadas de metastore) e Cross Join para Projeção de Subconsulta Escalar.
- Cache inteligente incorporado.
Dentro do Fabric Runtime for Apache Spark e Delta Lake, há recursos de gravador nativos que servem a dois propósitos principais:
- Eles oferecem desempenho diferenciado para cargas de trabalho de escrita, otimizando o processo de escrita.
- Eles padrão para otimização V-Order de arquivos Delta Parquet. A otimização Delta Lake V-Order é crucial para oferecer um desempenho de leitura superior em todos os mecanismos Fabric. Para obter uma compreensão mais profunda de como ele opera e como gerenciá-lo, consulte o artigo dedicado sobre otimização de tabelas Delta Lake e V-Order.
Suporte a vários tempos de execução
O Fabric suporta vários tempos de execução, oferecendo aos usuários a flexibilidade de alternar perfeitamente entre eles, minimizando o risco de incompatibilidades ou interrupções.
Por padrão, todos os novos espaços de trabalho usam a versão mais recente do tempo de execução, que atualmente é o Runtime 1.2.
Para alterar a versão do tempo de execução no nível do espaço de trabalho, vá para Workspace Settings > Data Engineering/Science > Spark Compute > Workspace Level Default e selecione o tempo de execução desejado entre as opções disponíveis.
Depois de fazer essa alteração, todos os itens criados pelo sistema no espaço de trabalho, incluindo Lakehouses, SJDs e Notebooks, funcionarão usando a versão de tempo de execução no nível do espaço de trabalho recém-selecionada a partir da próxima Sessão do Spark. Se você estiver usando um bloco de anotações com uma sessão existente para um trabalho ou qualquer atividade relacionada ao lakehouse, essa sessão do Spark continuará como está. No entanto, a partir da próxima sessão ou trabalho, a versão de tempo de execução selecionada será aplicada.
Consequências das alterações de tempo de execução nas configurações do Spark
Em geral, nosso objetivo é migrar todas as configurações do Spark. No entanto, se identificarmos que a configuração do Spark não é compatível com o Runtime B, emitiremos uma mensagem de aviso e nos absteremos de implementar a configuração.
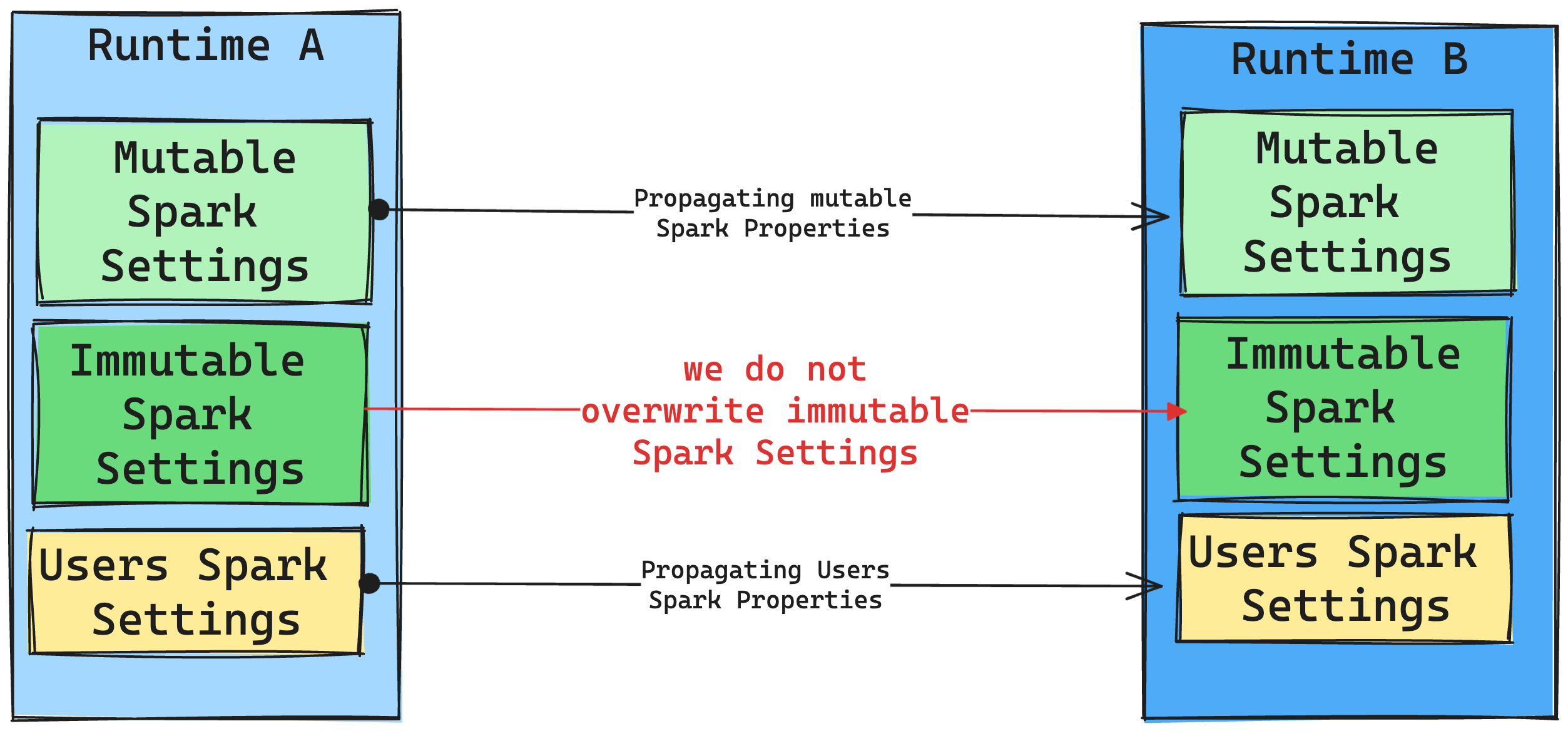
Consequências das alterações de tempo de execução no gerenciamento de bibliotecas
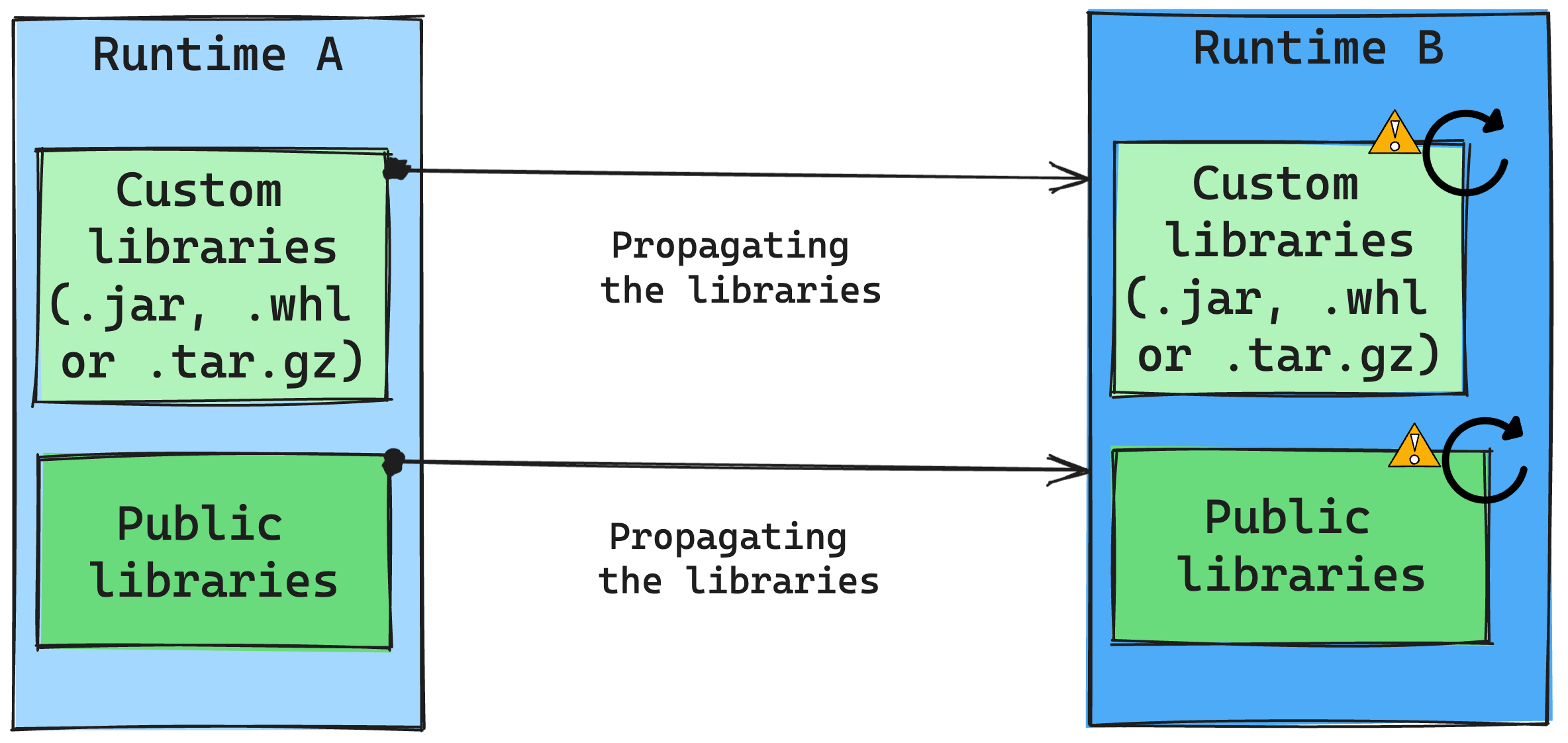
Em geral, nossa abordagem é migrar todas as bibliotecas do Runtime A para o Runtime B, incluindo Public e Custom Runtimes. Se as versões Python e R permanecerem inalteradas, as bibliotecas deverão funcionar corretamente. No entanto, para Jars, há uma probabilidade significativa de que eles podem não funcionar devido a alterações nas dependências e outros fatores, como alterações no Scala, Java, Spark e no sistema operacional.
O usuário é responsável por atualizar ou substituir quaisquer bibliotecas que não funcionem com o Runtime B. Se houver um conflito, o que significa que o Runtime B inclui uma biblioteca originalmente definida no Runtime A, nosso sistema de gerenciamento de bibliotecas tentará criar a dependência necessária para o Runtime B com base nas configurações do usuário. No entanto, o processo de construção falhará se ocorrer um conflito. No log de erros, os usuários podem ver quais bibliotecas estão causando conflitos e fazer ajustes em suas versões ou especificações.
Atualizar o protocolo Delta Lake
Os recursos do Delta Lake são sempre compatíveis com versões anteriores, garantindo que as tabelas criadas em uma versão inferior do Delta Lake possam interagir perfeitamente com versões superiores. No entanto, quando determinados recursos são habilitados (por exemplo, usando delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) o método, a compatibilidade direta com versões inferiores do Delta Lake pode ser comprometida. Nesses casos, é essencial modificar cargas de trabalho fazendo referência às tabelas atualizadas para alinhar com uma versão Delta Lake que mantenha a compatibilidade.
Cada tabela Delta está associada a uma especificação de protocolo, definindo os recursos suportados. Os aplicativos que interagem com a tabela, seja para leitura ou gravação, dependem dessa especificação de protocolo para determinar se são compatíveis com o conjunto de recursos da tabela. Se um aplicativo não tiver a capacidade de lidar com um recurso listado como suportado no protocolo da tabela, ele não poderá ler ou gravar nessa tabela.
A especificação do protocolo é dividida em dois componentes distintos: o protocolo de leitura e o protocolo de gravação. Visite a página "Como o Delta Lake gerencia a compatibilidade de recursos?" para ler detalhes sobre ele.

Os usuários podem executar o comando delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) dentro do ambiente PySpark e no Spark SQL e Scala. Este comando permite que eles iniciem uma atualização na tabela Delta.
É essencial observar que, ao executar essa atualização, os usuários recebem um aviso indicando que a atualização da versão do protocolo Delta é um processo irreversível. Isso significa que, uma vez que a atualização é executada, ela não pode ser desfeita.
As atualizações da versão do protocolo podem potencialmente afetar a compatibilidade dos leitores de tabela, gravadores ou ambos existentes do Delta Lake. Portanto, é aconselhável proceder com cautela e atualizar a versão do protocolo apenas quando necessário, como ao adotar novos recursos no Delta Lake.
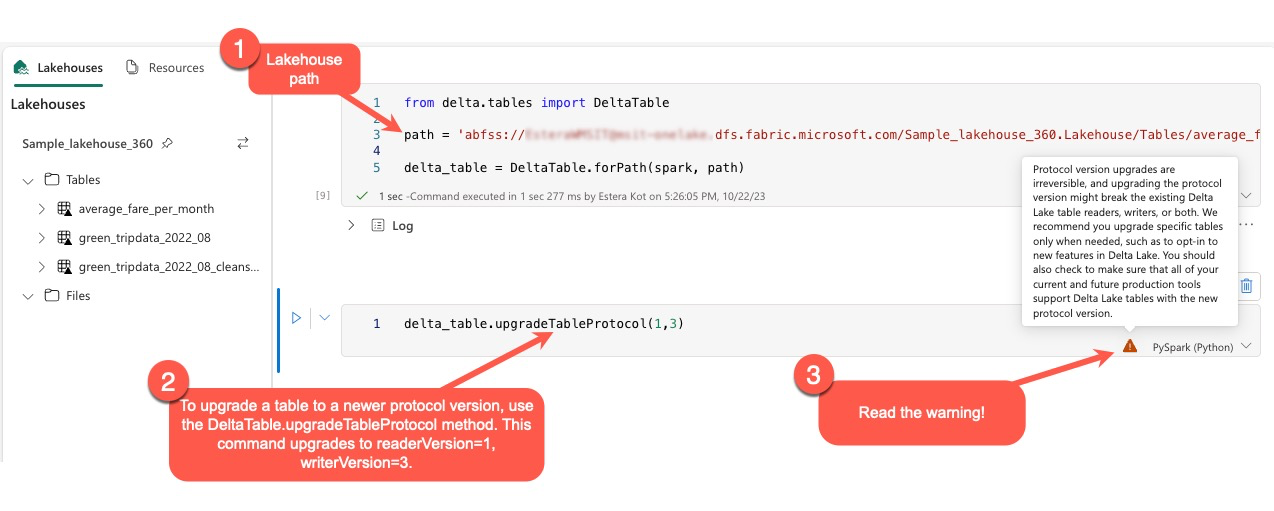
Além disso, os usuários devem verificar se todas as cargas de trabalho e processos de produção atuais e futuros são compatíveis com as tabelas Delta Lake usando a nova versão do protocolo para garantir uma transição perfeita e evitar possíveis interrupções.
Alterações Delta 2.2 vs Delta 2.4
No Fabric Runtime mais recente , versão 1.3 e no Fabric Runtime, versão 1.2, o formato de tabela padrão (spark.sql.sources.default) agora deltaé . Em versões anteriores do Fabric Runtime, versão 1.1 e em todos os Synapse Runtime for Apache Spark contendo Spark 3.3 ou inferior, o formato de tabela padrão era definido como parquet. Verifique na tabela com os detalhes de configuração do Apache Spark as diferenças entre o Azure Synapse Analytics e o Microsoft Fabric.
Todas as tabelas criadas usando Spark SQL, PySpark, Scala Spark e Spark R, sempre que o tipo de tabela for omitido, criarão a tabela como delta por padrão. Se os scripts definirem explicitamente o formato da tabela, isso será respeitado. O comando USING DELTA no Spark create table commands torna-se redundante.
Os scripts que esperam ou assumem o formato de tabela de parquet devem ser revisados. Os seguintes comandos não são suportados em tabelas Delta:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE