Início Rápido: mova e transforme dados com fluxos e pipelines de dados
Neste tutorial, você descobre como a experiência de fluxo de dados e pipeline de dados pode criar uma solução de Data Factory poderosa e abrangente.
Pré-requisitos
Para começar, você deve ter os seguintes pré-requisitos:
- Uma conta de locatário com uma assinatura ativa. Crie uma conta gratuita .
- Certifique-se de que tem um espaço de trabalho habilitado para o Microsoft Fabric: Criar um espaço de trabalho que não seja o padrão O meu espaço de trabalho.
- Um banco de dados SQL do Azure com dados de tabela.
- Uma conta de Armazenamento de Blob.
Fluxos de dados em comparação com linhas de processamento
O Dataflows Gen2 permite que você use uma interface low-code e 300+ transformações baseadas em IA para limpar, preparar e transformar dados facilmente com mais flexibilidade do que qualquer outra ferramenta. Os pipelines de dados permitem recursos avançados de orquestração de dados prontos para compor fluxos de trabalho de dados flexíveis que atendem às necessidades da sua empresa. Em um pipeline, você pode criar agrupamentos lógicos de atividades que executam uma tarefa, o que pode incluir chamar um fluxo de dados para limpar e preparar seus dados. Embora haja alguma sobreposição de funcionalidade entre os dois, a escolha de qual usar para um cenário específico depende se você precisa da riqueza total de pipelines ou pode usar os recursos mais simples, mas mais limitados, dos fluxos de dados. Para obter mais informações, consulte o guia de decisão do Fabric
Transforme dados com fluxos de dados
Siga estas etapas para configurar seu fluxo de dados.
Etapa 1: Criar um fluxo de dados
Escolha o seu espaço de trabalho habilitado para o Fabric e, em seguida, selecione Novo. Em seguida, selecione Dataflow Gen2.
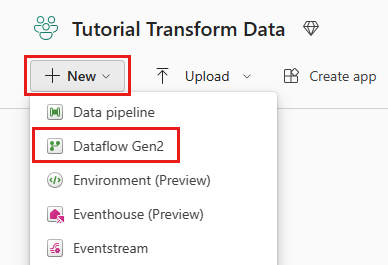
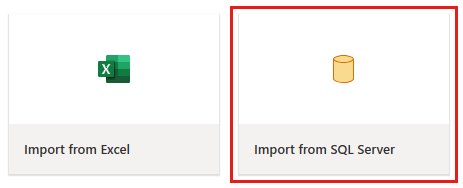
A janela do editor de fluxo de dados é exibida. Selecione o cartão Importar do SQL Server.


Etapa 2: Obter dados
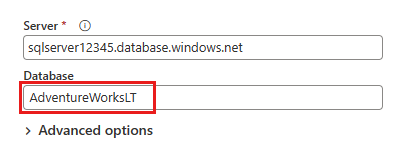
No diálogo Conectar à fonte de dados apresentado a seguir, insira os detalhes para se conectar ao seu banco de dados SQL do Azure e selecione Seguinte. Neste exemplo, utiliza-se o AdventureWorksLT banco de dados de exemplo configurado ao configurar o banco de dados SQL do Azure nos requisitos prévios.
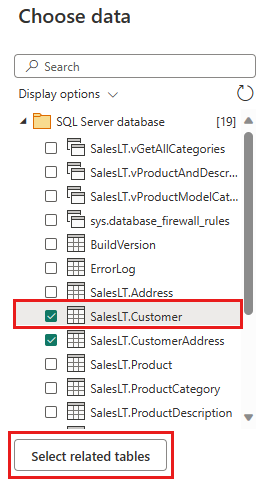
Selecione os dados que pretende transformar e, em seguida, selecione Criar. Para este início rápido, selecione SalesLT.Customer dos dados de exemplo AdventureWorksLT fornecidos para o Azure SQL DB, e então clique no botão Selecionar tabelas relacionadas para incluir automaticamente duas outras tabelas relacionadas.


Etapa 3: Transforme seus dados
Se não estiver selecionado, selecione o botão Vista de Diagrama ao longo da barra de estado na parte inferior da página ou selecione Vista de Diagrama no menu Vista na parte superior do editor do Power Query. Qualquer uma destas opções pode alternar a visualização do diagrama.
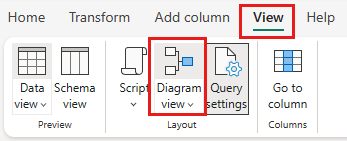
Clique com o botão direito na consulta SalesLT Customer ou selecione o ícone de três pontos à direita da consulta e, em seguida, selecione Mesclar consultas.
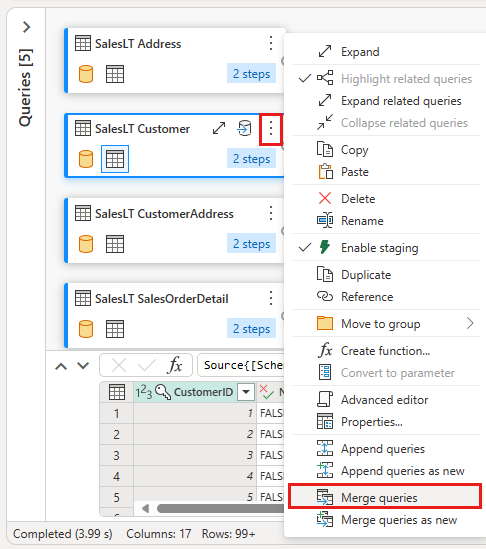
Configure a mesclagem selecionando a tabela SalesLTOrderHeader como a tabela direita para a mesclagem, a coluna CustomerID de cada tabela como a coluna de junção e Externa à Esquerda como o tipo de junção. Em seguida, selecione OK para adicionar a consulta de mesclagem.
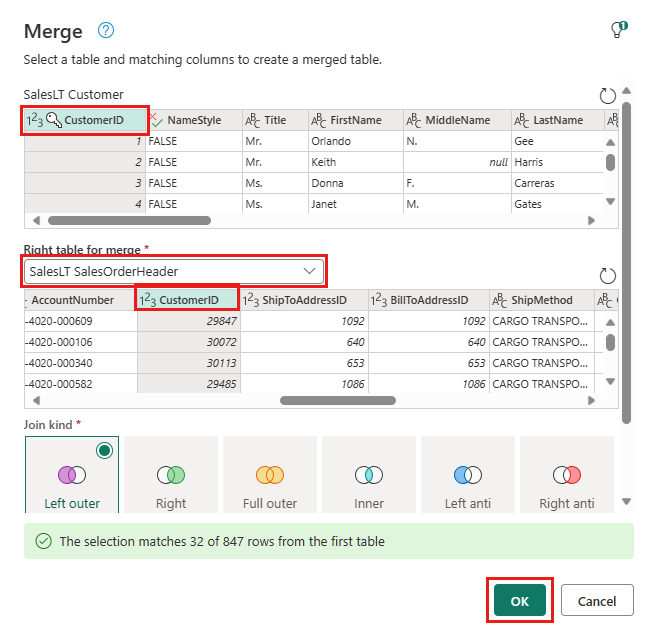
Selecione o botão Adicionar destino de dados, que se parece com um símbolo de banco de dados com uma seta acima dele, na nova consulta de mesclagem que você criou. Em seguida, selecione banco de dados SQL do Azure como o tipo de destino.
Forneça os detalhes para sua conexão de banco de dados SQL do Azure onde a consulta de mesclagem deve ser publicada. Neste exemplo, você também pode usar o banco de dados
AdventureWorksLT que usamos como fonte de dados para o destino. 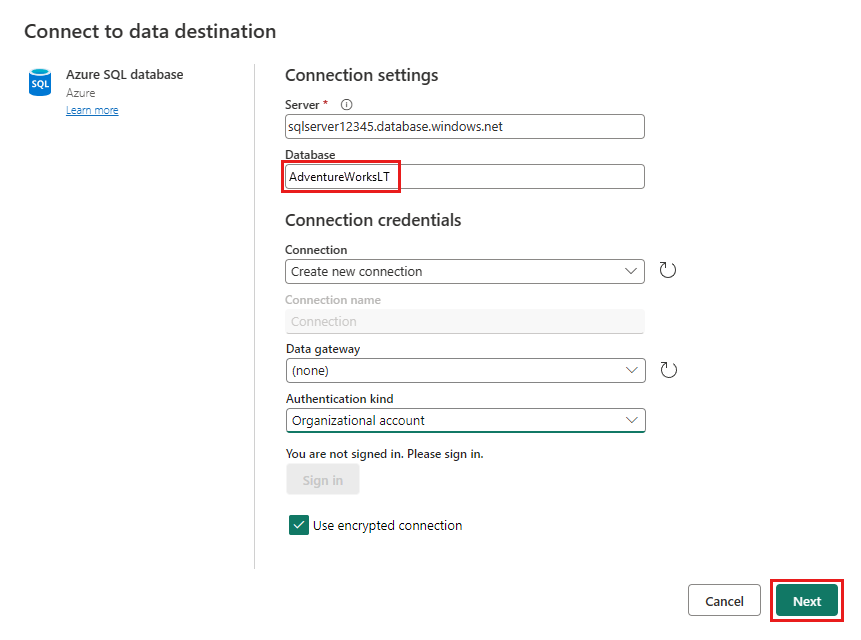
Escolha um banco de dados para armazenar os dados e forneça um nome de tabela e, em seguida, selecione Avançar.
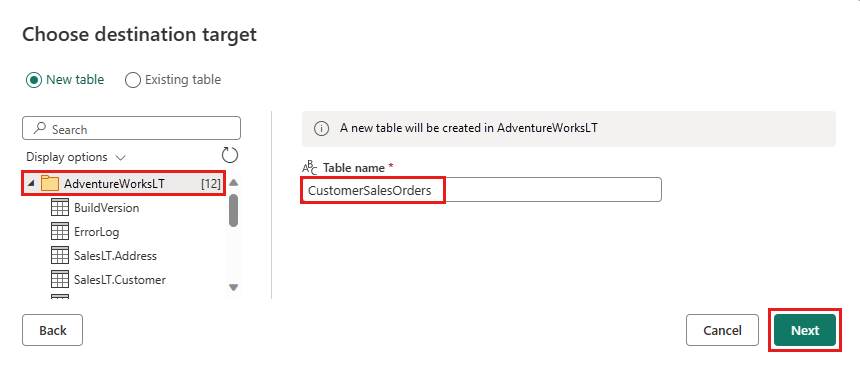
Você pode deixar as configurações padrão na caixa de diálogo
Escolher configurações de destino e apenas selecionar Salvar configurações sem fazer nenhuma alteração aqui.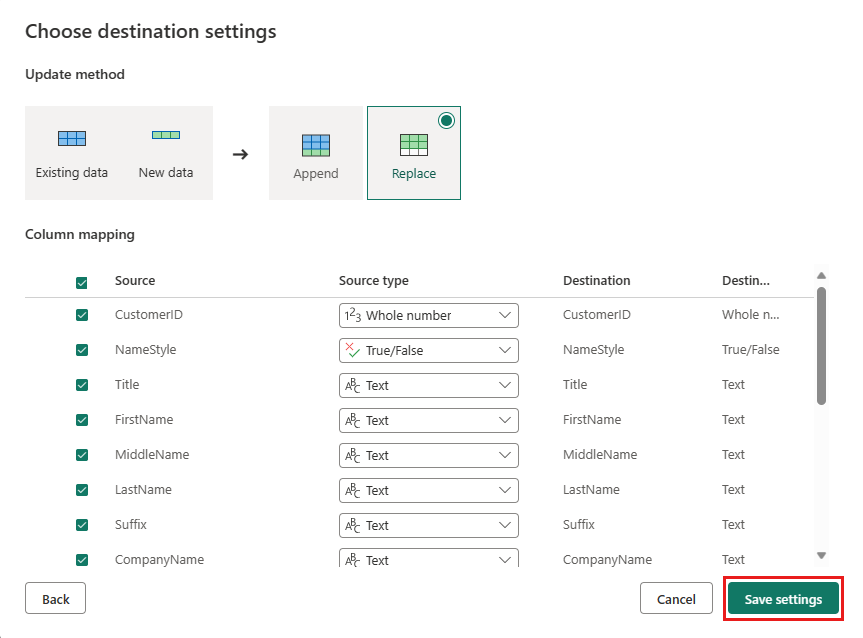
Selecione Publicar novamente na página do editor de fluxo de dados para publicar o fluxo de dados.



Mover dados com fluxos de dados
Agora que criaste um Dataflow Gen2, podes trabalhar com ele num pipeline. Neste exemplo, você copia os dados gerados do fluxo de dados para o formato de texto em uma conta de Armazenamento de Blob do Azure.
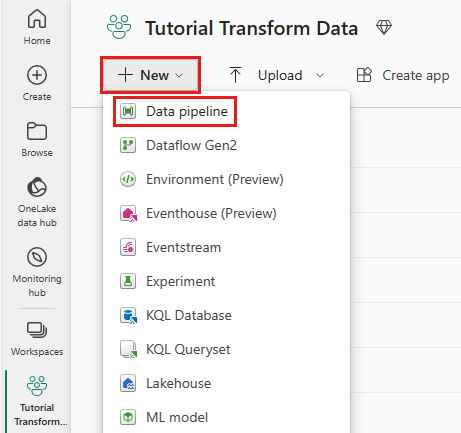
Etapa 1: Criar um novo pipeline de dados
No espaço de trabalho, selecione Novoe depois selecione pipeline de dados.
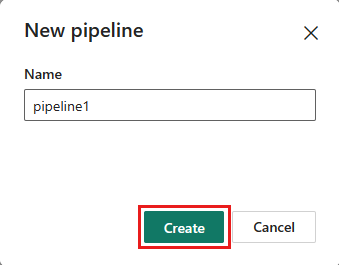
Nomeie seu pipeline e selecione Criar.
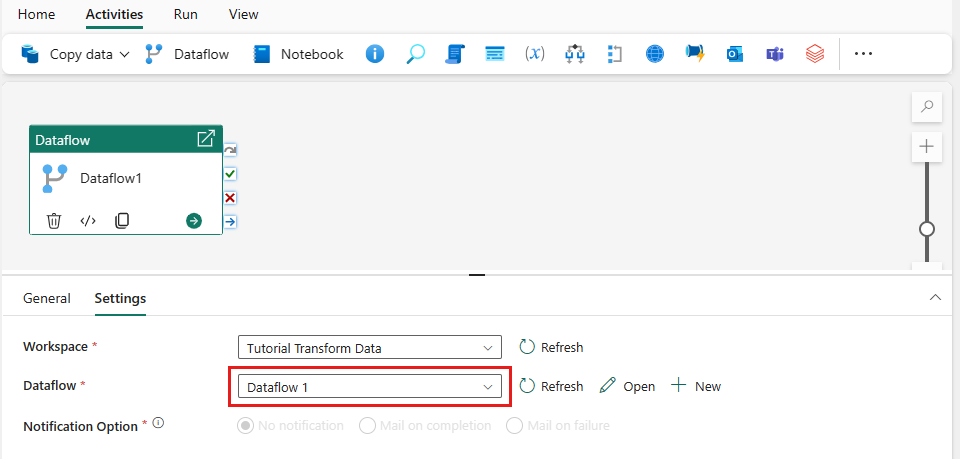
Etapa 2: Configurar o fluxo de dados
Adicione uma nova atividade de fluxo de dados ao seu pipeline de dados ao selecionar Fluxo de Dados no separador Atividades.

Selecione o fluxo de dados na tela do pipeline e, em seguida, a guia de Configurações. Escolha o fluxo de dados criado anteriormente na lista suspensa.
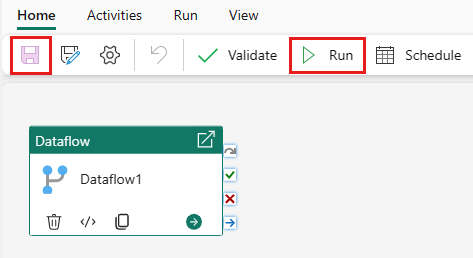
Selecione Salvare, em seguida, Executar para executar o fluxo de dados para preencher inicialmente sua tabela de consulta mesclada que você criou na etapa anterior.
Etapa 3: Usar o assistente de cópia para adicionar uma atividade de cópia
Selecione Copiar dados na tela para abrir a ferramenta Assistente de Cópia para começar. Ou selecione Usar assistente de cópia na lista suspensa Copiar dados sob a aba Atividades na faixa de opções.
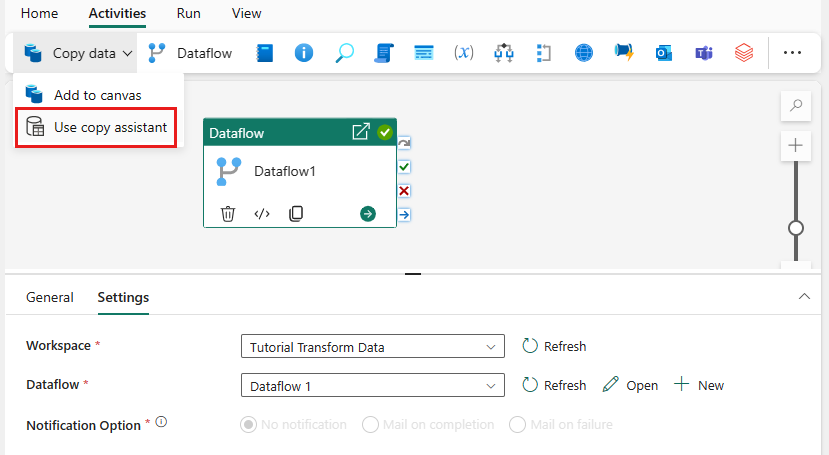
Escolha sua fonte de dados selecionando um tipo de fonte de dados. Neste tutorial, você usa o Banco de Dados SQL do Azure usado anteriormente quando criou o fluxo de dados para gerar uma nova consulta de mesclagem. Role para baixo abaixo das ofertas de dados de exemplo e selecione a guia do
Azure e, em seguida, Banco de Dados SQL do Azure . Em seguida, selecione Avançar para continuar.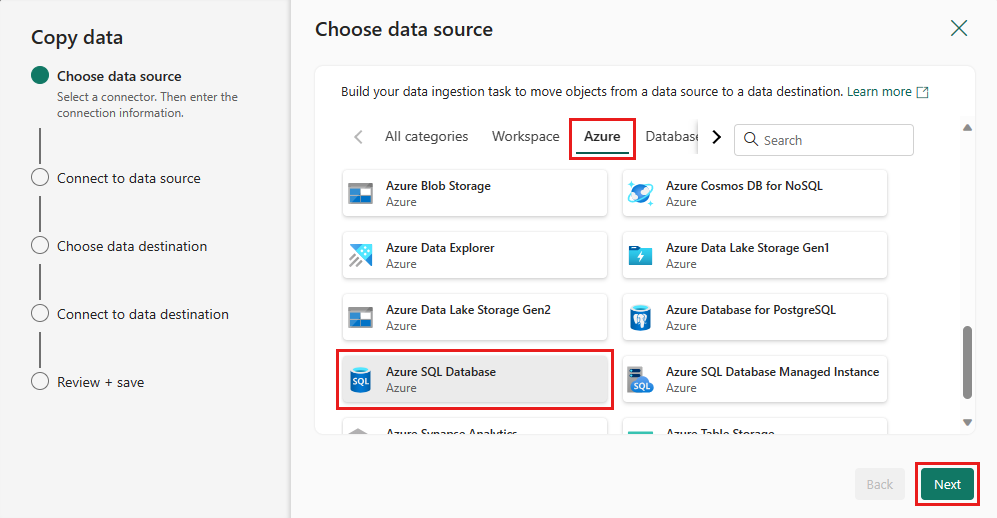
Crie uma conexão com sua fonte de dados selecionando Criar nova conexão. Preencha as informações de conexão necessárias no painel e insira o AdventureWorksLT para o banco de dados, onde geramos a consulta de mesclagem no fluxo de dados. Em seguida, selecione Avançar.
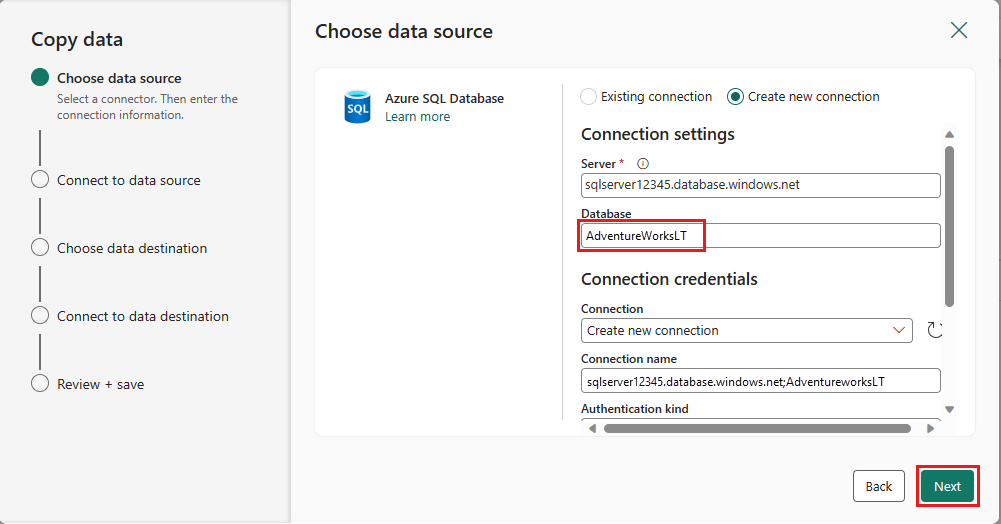
Selecione a tabela gerada na etapa de fluxo de dados anterior e, em seguida, selecione Avançar.
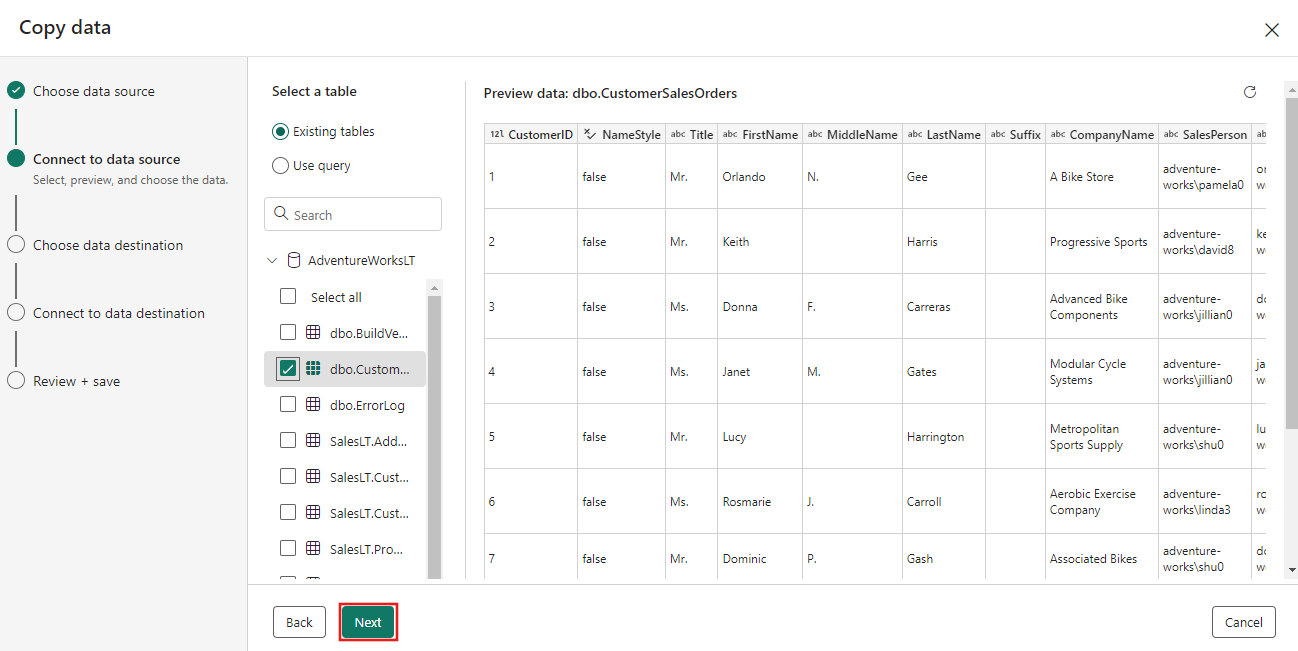
Para o seu destino, escolha Armazenamento de Blobs do Azure e selecione Avançar.
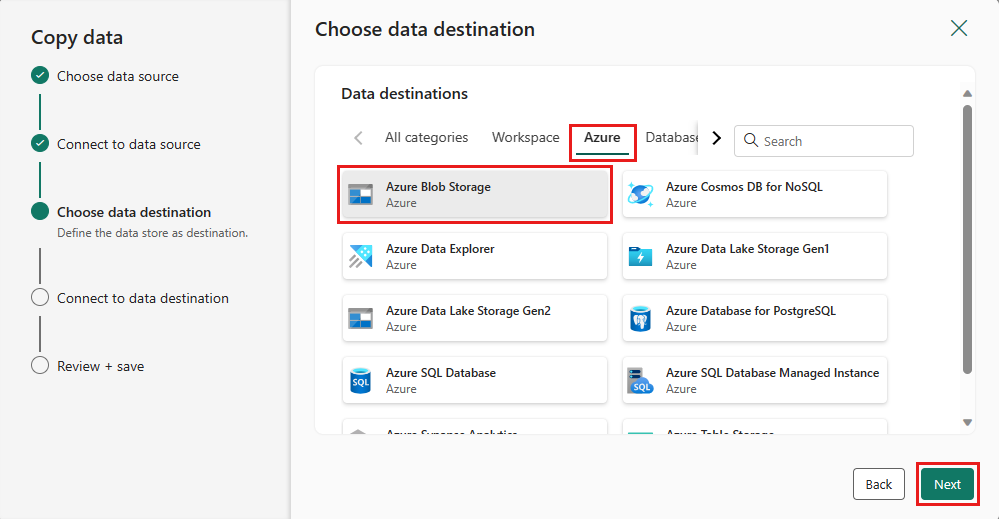
Crie uma conexão com seu destino selecionando Criar nova conexão. Forneça os detalhes da sua ligação e, em seguida, selecione Seguinte.
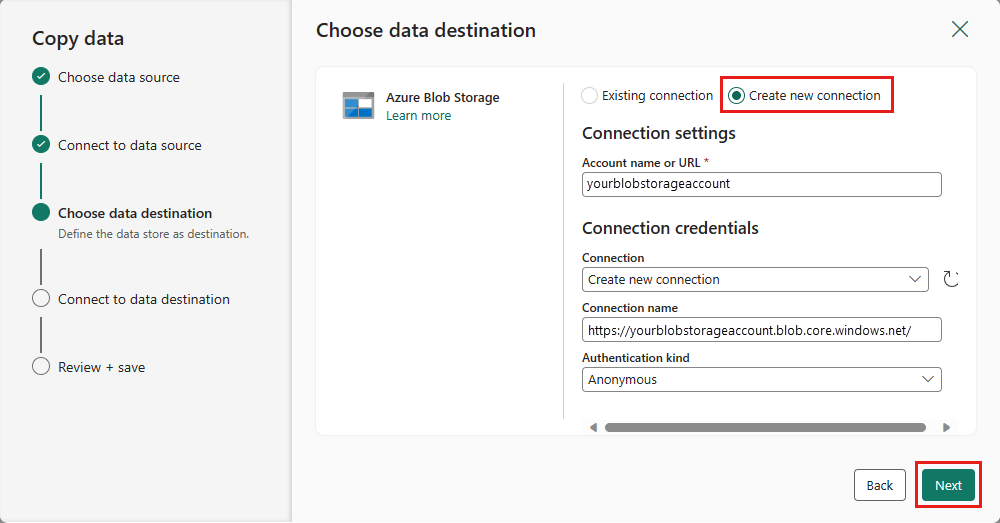
Selecione o caminho da pasta e forneça um nome de arquivo e, em seguida, selecione Avançar.
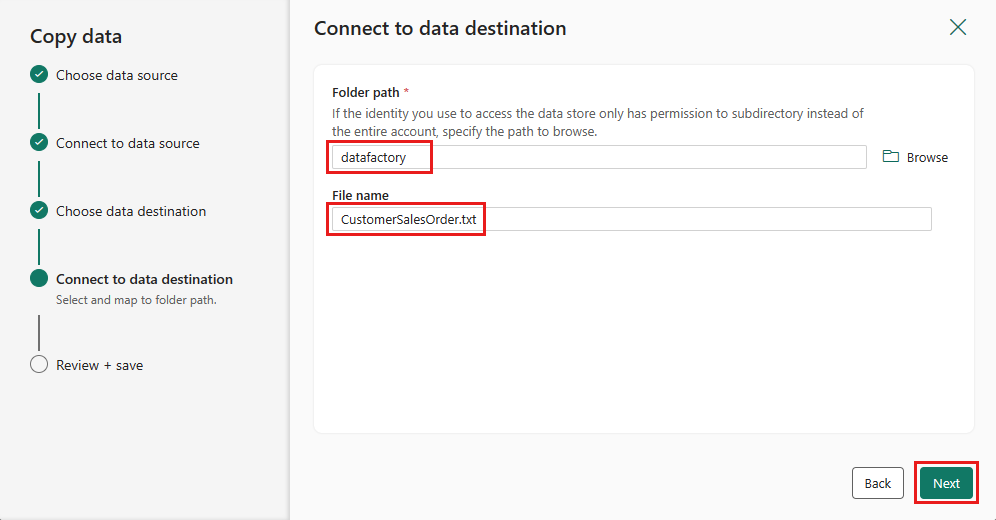
Selecione Avançar novamente para aceitar o formato de arquivo padrão, delimitador de coluna, delimitador de linha e tipo de compactação, opcionalmente incluindo um cabeçalho.
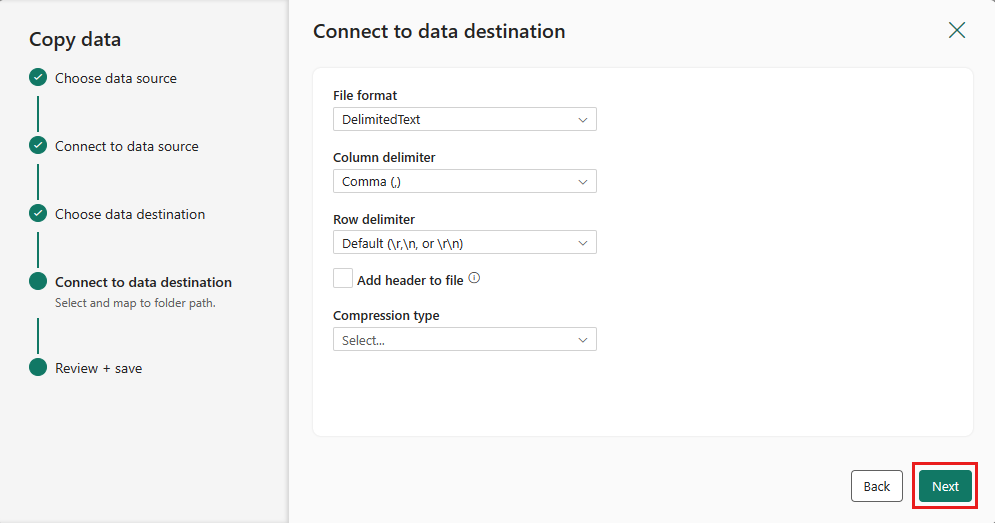
Finalize suas configurações. Em seguida, revise e selecione Salvar + Executar para concluir o processo.
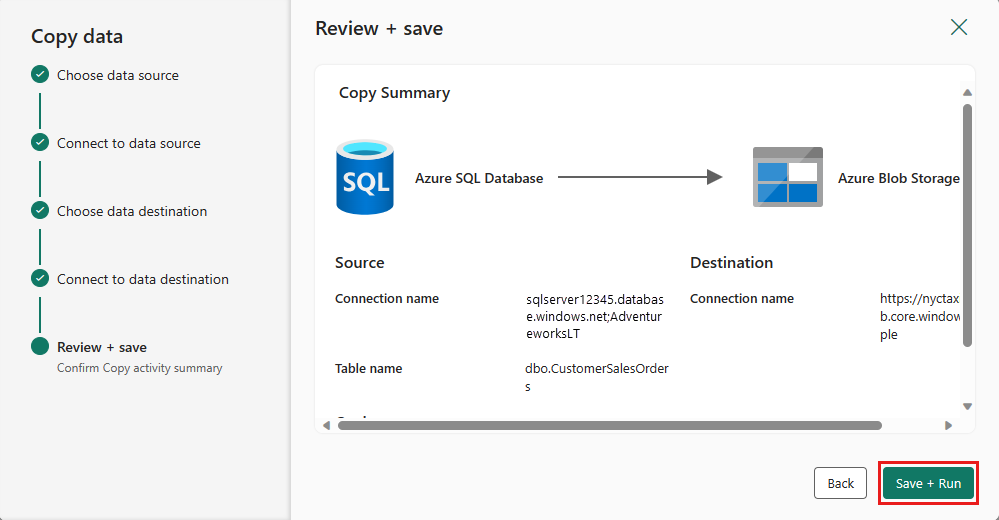
Etapa 5: Projetar seu pipeline de dados e salvar para executar e carregar dados
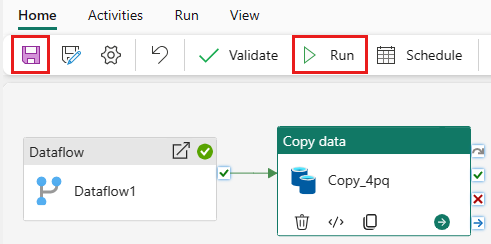
Para executar a atividade Copy
após a atividade Dataflow , arraste de Succeeded na atividade Dataflow para a atividade Copy . A atividade Copy só é executada depois que a atividade Dataflow tiver sucesso. 
Selecione Guardar para guardar o seu pipeline de dados. Em seguida, selecione Executar para executar o pipeline de dados e carregar os dados.
Programar a execução do pipeline
Depois de concluir o desenvolvimento e o teste do pipeline, você pode programá-lo para ser executado automaticamente.
Na guia Home da janela do editor de pipeline, selecione Agenda.
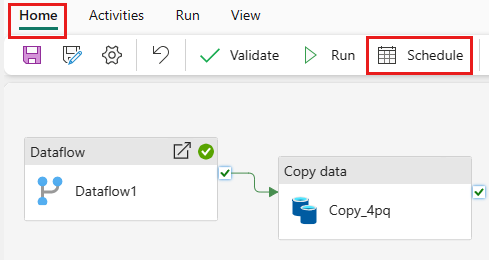
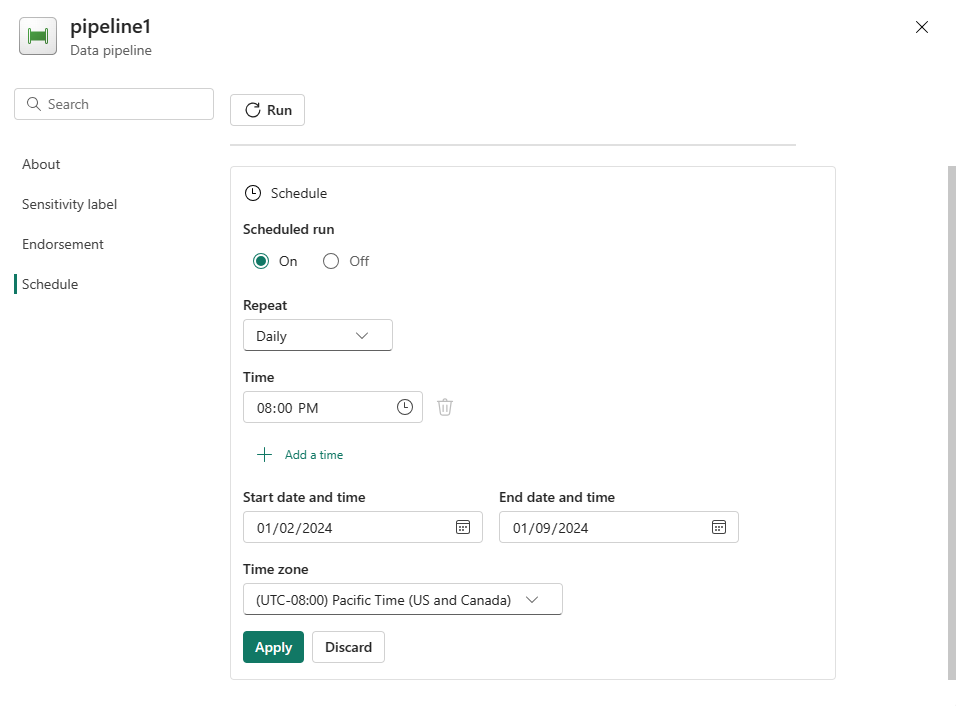
Configure a agenda conforme necessário. O exemplo aqui agenda o pipeline para ser executado diariamente às 20:00 até ao fim do ano.
Conteúdo relacionado
Este exemplo mostra como criar e configurar um Dataflow Gen2 para criar uma consulta de mesclagem e armazená-la em um banco de dados SQL do Azure e, em seguida, copiar dados do banco de dados para um arquivo de texto no Armazenamento de Blobs do Azure. Você aprendeu a:
- Crie um fluxo de dados.
- Transforme dados com o fluxo de dados.
- Crie um canal de dados usando o fluxo de dados.
- Ordenar a execução das etapas no pipeline.
- Copie dados com o Assistente de Cópia.
- Execute e agende seu pipeline de dados.
Em seguida, avance para saber mais sobre como monitorizar as suas execuções de pipelines.