Receita: Serviços de IA do Azure - Deteção de anomalias multivariadas
Esta receita mostra como você pode usar os serviços SynapseML e Azure AI no Apache Spark para deteção de anomalias multivariadas. A deteção multivariada de anomalias permite detetar anomalias entre muitas variáveis ou séries temporais, tendo em conta todas as intercorrelações e dependências entre as diferentes variáveis. Nesse cenário, usamos o SynapseML para treinar um modelo para deteção de anomalias multivariadas usando os serviços de IA do Azure e, em seguida, usamos o modelo para inferir anomalias multivariadas em um conjunto de dados contendo medições sintéticas de três sensores IoT.
Importante
A partir de 20 de setembro de 2023, você não poderá criar novos recursos do Detetor de Anomalias. O serviço de Detetor de Anomalias está a ser desativado no dia 1 de outubro de 2026.
Para saber mais sobre o Azure AI Anomaly Detetor, consulte esta página de documentação.
Pré-requisitos
- Uma assinatura do Azure - Crie uma gratuitamente
- Ligue o seu bloco de notas a uma casa no lago. No lado esquerdo, selecione Adicionar para adicionar uma casa de lago existente ou criar uma casa de lago.
Configurar
Siga as instruções para criar um Anomaly Detector recurso usando o portal do Azure ou, alternativamente, você também pode usar a CLI do Azure para criar esse recurso.
Depois de configurar um Anomaly Detector, você pode explorar métodos de manipulação de dados de vários formulários. O catálogo de serviços dentro da IA do Azure fornece várias opções: Visão, Fala, Idioma, Pesquisa na Web, Decisão, Tradução e Inteligência de Documentos.
Criar um recurso de Detetor de Anomalias
- No portal do Azure, selecione Criar no seu grupo de recursos e digite Detetor de Anomalias. Selecione o recurso Detetor de anomalias.
- Dê um nome ao recurso e, idealmente, use a mesma região que o restante do grupo de recursos. Utilize as opções predefinidas para o resto e, em seguida, selecione Rever + Criar e, em seguida , Criar.
- Uma vez criado o recurso Detetor de Anomalias, abra-o e selecione o
Keys and Endpointspainel no painel de navegação esquerdo. Copie a chave do recurso Detetor de anomalias para aANOMALY_API_KEYvariável de ambiente ou armazene-aanomalyKeyna variável.
Criar um recurso de Conta de Armazenamento
Para salvar dados intermediários, você precisa criar uma Conta de Armazenamento de Blob do Azure. Dentro dessa conta de armazenamento, crie um contêiner para armazenar os dados intermediários. Anote o nome do contêiner e copie a cadeia de conexão para esse contêiner. Você precisará dele mais tarde para preencher a containerName variável e a BLOB_CONNECTION_STRING variável de ambiente.
Introduza as suas chaves de serviço
Vamos começar configurando as variáveis de ambiente para nossas chaves de serviço. A próxima célula define as ANOMALY_API_KEY variáveis e de BLOB_CONNECTION_STRING ambiente com base nos valores armazenados em nosso Cofre de Chaves do Azure. Se você estiver executando este tutorial em seu próprio ambiente, certifique-se de definir essas variáveis de ambiente antes de continuar.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Agora, vamos ler as ANOMALY_API_KEY variáveis e BLOB_CONNECTION_STRING ambiente e definir as containerName variáveis e location .
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Primeiro, nos conectamos à nossa conta de armazenamento para que o detetor de anomalias possa salvar resultados intermediários lá:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Vamos importar todos os módulos necessários.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Agora, vamos ler nossos dados de exemplo em um DataFrame do Spark.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Agora podemos criar um estimator objeto, que é usado para treinar nosso modelo. Especificamos os horários de início e término dos dados de treinamento. Também especificamos as colunas de entrada a serem usadas e o nome da coluna que contém os carimbos de data/hora. Por fim, especificamos o número de pontos de dados a serem usados na janela deslizante de deteção de anomalias e definimos a cadeia de conexão para a Conta de Armazenamento de Blob do Azure.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Agora que criamos o estimator, vamos ajustá-lo aos dados:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Quando chamamos .show(5) a célula anterior, ela nos mostrou as cinco primeiras linhas no dataframe. Os resultados foram todos null porque não estavam dentro da janela de inferência.
Para mostrar os resultados apenas para os dados inferidos, vamos selecionar as colunas de que precisamos. Em seguida, podemos ordenar as linhas no dataframe por ordem crescente e filtrar o resultado para mostrar apenas as linhas que estão no intervalo da janela de inferência. No nosso caso inferenceEndTime é o mesmo que a última linha no dataframe, então pode ignorar isso.
Finalmente, para poder plotar melhor os resultados, vamos converter o dataframe do Spark em um dataframe Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Formate a contributors coluna que armazena a pontuação de contribuição de cada sensor para as anomalias detetadas. A próxima célula formata esses dados e divide a pontuação de contribuição de cada sensor em sua própria coluna.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Excelente! Agora temos as pontuações de contribuição dos sensores 1, 2 e 3 nas series_0colunas , series_1e series_2 respectivamente.
Execute a próxima célula para plotar os resultados. O minSeverity parâmetro especifica a gravidade mínima das anomalias a serem representadas.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
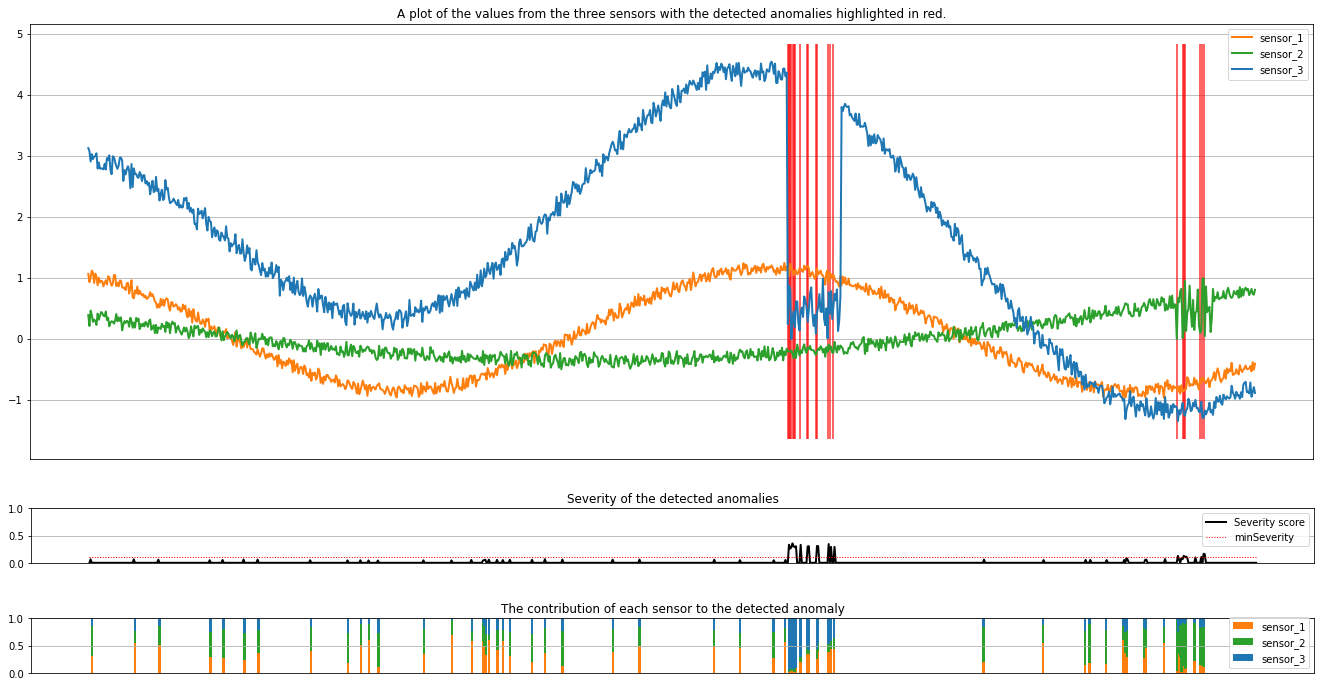
Os gráficos mostram os dados brutos dos sensores (dentro da janela de inferência) em laranja, verde e azul. As linhas verticais vermelhas na primeira figura mostram as anomalias detetadas que têm uma gravidade maior ou igual a minSeverity.
O segundo gráfico mostra a pontuação de gravidade de todas as anomalias detetadas, com o minSeverity limiar mostrado na linha vermelha pontilhada.
Finalmente, o último gráfico mostra a contribuição dos dados de cada sensor para as anomalias detetadas. Ajuda-nos a diagnosticar e compreender a causa mais provável de cada anomalia.