Obter dados do Amazon S3
Neste artigo, você aprenderá como obter dados do Amazon S3 em uma tabela nova ou existente. O Amazon S3 é um serviço de armazenamento de objetos criado para armazenar e recuperar dados.
Para obter mais informações sobre o Amazon S3, consulte O que é o Amazon S3?.
Pré-requisitos
- Um espaço de trabalho com uma capacidade habilitada para Microsoft Fabric
- Um banco de dados KQL com permissões de edição
- Um bucket do Amazon S3 com dados
Origem
Na faixa de opções inferior do banco de dados KQL, selecione Obter dados.
Na janela Obter dados, a guia Origem está selecionada.
Selecione a fonte de dados na lista disponível. Neste exemplo, você está ingerindo dados do Amazon S3.


Configurar
Selecione uma tabela de destino. Se pretender ingerir dados numa nova tabela, selecione +Nova tabela e introduza um nome de tabela.
Nota
Os nomes das tabelas podem ter até 1024 caracteres, incluindo espaços, alfanuméricos, hífenes e sublinhados. Não há suporte para caracteres especiais.
No campo URI, cole a cadeia de conexão de um único bucket ou de um objeto individual no formato a seguir.
Bucket:
https://BucketName.s3.RegionName.amazonaws.com;AwsCredentials=AwsAccessID,AwsSecretKeyOpcionalmente, você pode aplicar filtros de bucket para filtrar dados de acordo com uma extensão de arquivo específica.

Selecione Seguinte.

Inspecionar
A guia Inspecionar é aberta com uma visualização dos dados.
Para concluir o processo de ingestão, selecione Concluir.

Opcionalmente:
- Selecione Visualizador de comandos para visualizar e copiar os comandos automáticos gerados a partir de suas entradas.
- Use a lista suspensa Arquivo de definição de esquema para alterar o arquivo do qual o esquema é inferido.
- Altere o formato de dados inferido automaticamente selecionando o formato desejado na lista suspensa. Para obter mais informações, consulte Formatos de dados suportados pelo Real-Time Intelligence.
- Editar colunas.
- Explore as opções avançadas com base no tipo de dados.
Editar colunas
Nota
- Para formatos tabulares (CSV, TSV, PSV), não é possível mapear uma coluna duas vezes. Para mapear para uma coluna existente, primeiro exclua a nova coluna.
- Não é possível alterar um tipo de coluna existente. Se você tentar mapear para uma coluna com um formato diferente, você pode acabar com colunas vazias.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Renomear coluna, alterar tipo de dados, alterar fonte de dados, mapear transformação, adicionar coluna, excluir coluna |
| Tabela existente | Novo mapeamento | Adicionar coluna (na qual você pode alterar o tipo de dados, renomear e atualizar) |
| Tabela existente | Mapeamento existente | nenhum |

Mapeando transformações
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) suportam transformações simples em tempo de ingestão. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela Editar colunas .
As transformações de mapeamento podem ser executadas em uma coluna do tipo string ou datetime, com a fonte tendo o tipo de dados int ou long. As transformações de mapeamento suportadas são:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opções avançadas com base no tipo de dados
Tabela (CSV, TSV, PSV):
Se você estiver ingerindo formatos tabulares em uma tabela existente, poderá selecionar Esquema de tabela de manutenção avançada>. Os dados tabulares não incluem necessariamente os nomes das colunas usadas para mapear os dados de origem para as colunas existentes. Quando essa opção é marcada, o mapeamento é feito por ordem e o esquema da tabela permanece o mesmo. Se essa opção estiver desmarcada, novas colunas serão criadas para os dados de entrada, independentemente da estrutura dos dados.
Para usar a primeira linha como nomes de coluna, selecione Avançado>Primeira linha é cabeçalho de coluna.

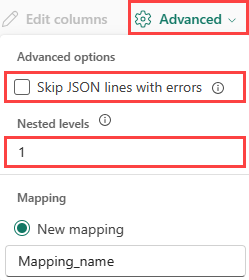
JSON:
Para determinar a divisão de colunas dos dados JSON, selecione Níveis aninhados avançados>, de 1 a 100.
Se você selecionar Ignorar linhas JSON avançadas>com erros, os dados serão ingeridos no formato JSON. Se você deixar essa caixa de seleção desmarcada, os dados serão ingeridos no formato multijson.
Resumo
Na janela Preparação de dados, todas as três etapas são marcadas com marcas de seleção verdes quando a ingestão de dados é concluída com êxito. Você pode selecionar um cartão para consultar, soltar os dados ingeridos ou ver um painel do resumo da sua ingestão.

Conteúdos relacionados
- Para gerenciar seu banco de dados, consulte Gerenciar dados
- Para criar, armazenar e exportar consultas, consulte Consultar dados em um conjunto de consultas KQL