Agregações automáticas
As agregações automáticas usam aprendizado de máquina (ML) de última geração para otimizar continuamente os modelos semânticos do DirectQuery para obter o máximo desempenho da consulta de relatório. As agregações automáticas são criadas com base na infraestrutura de agregações definida pelo usuário existente, introduzida pela primeira vez com modelos compostos para o Power BI. Ao contrário das agregações definidas pelo usuário, as agregações automáticas não exigem habilidades extensas de modelagem de dados e otimização de consultas para configurar e manter. As agregações automáticas são autotreinadas e autootimizadas. Eles permitem que os proprietários de modelos de qualquer nível de habilidade melhorem o desempenho da consulta, fornecendo visualizações de relatório mais rápidas para modelos grandes.
Com agregações automáticas:
- As visualizações de relatório são mais rápidas - Uma porcentagem ideal de consultas de relatório é retornada por um cache de agregações na memória mantido automaticamente em vez de sistemas de fonte de dados de back-end. As consultas atípicas que não são retornadas pelo cache na memória são passadas diretamente para a fonte de dados usando o DirectQuery.
- Arquitetura balanceada - Quando comparado ao modo DirectQuery puro, a maioria dos resultados da consulta é retornada pelo mecanismo de consulta do Power BI e pelo cache de agregações na memória. A carga de processamento de consultas em sistemas de fonte de dados em horários de pico de relatórios pode ser significativamente reduzida, o que significa maior escalabilidade no back-end da fonte de dados.
- Configuração fácil - Os proprietários de modelos podem ativar o treinamento de agregações automáticas e agendar uma ou mais atualizações para o modelo. Com o primeiro treinamento e atualização, as agregações automáticas começam a criar uma estrutura de agregações e agregações ideais. O sistema ajusta-se automaticamente ao longo do tempo.
- Ajuste fino – Com uma interface de usuário simples e intuitiva nas configurações do modelo, você pode estimar os ganhos de desempenho para uma porcentagem diferente de consultas retornadas do cache de agregações na memória e fazer ajustes para ganhos ainda maiores. Um único controle de barra deslizante ajuda você a ajustar facilmente seu ambiente.
Requisitos
Planos suportados
Há suporte para agregações automáticas para modelos Power BI Premium por capacidade, Premium por usuário e Power BI Embedded .
Supported data sources (Origens de dados suportadas)
Há suporte para agregações automáticas para as seguintes fontes de dados:
- Base de Dados SQL do Azure
- Azure Synapse Pool SQL Dedicado
- SQL Server 2019 ou posterior
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Modos suportados
Há suporte para agregações automáticas para modelos de modo DirectQuery. Há suporte para modelos compostos com tabelas de importação e conexões DirectQuery. As agregações automáticas são suportadas apenas para a conexão DirectQuery.
Permissões
Para habilitar e configurar agregações automáticas, você deve ser o proprietário do modelo. Os administradores do espaço de trabalho podem assumir o cargo de proprietário para definir as configurações de agregações automáticas.
Configurando agregações automáticas
As agregações automáticas são configuradas em Configurações do modelo. A configuração é simples - habilite o treinamento de agregações automáticas e agende uma ou mais atualizações. Antes de configurar as agregações automáticas para o seu modelo, leia este artigo na íntegra. Ele fornece uma boa compreensão de como as agregações automáticas funcionam e pode ajudá-lo a decidir se as agregações automáticas são adequadas para o seu ambiente. Quando estiver pronto para obter instruções passo a passo sobre como habilitar o treinamento de agregações automáticas, configurar uma agenda de atualização e ajustar seu ambiente, consulte Configurar agregações automáticas.
Benefícios
Com o DirectQuery, cada vez que um usuário modelo abre um relatório ou interage com uma visualização de relatório, as consultas DAX (Data Analysis Expressions) são passadas para o mecanismo de consulta e, em seguida, para a fonte de dados de back-end como consultas SQL. A fonte de dados deve calcular e retornar resultados para cada consulta. Em comparação com os modelos de modo de importação armazenados na memória, as viagens de ida e volta da fonte de dados DirectQuery podem exigir muito tempo e processo, geralmente causando tempos de resposta de consulta lentos em visualizações de relatório.
Quando habilitadas para um modelo DirectQuery, as agregações automáticas podem aumentar o desempenho da consulta de relatório, evitando viagens de ida e volta de consulta da fonte de dados. Os resultados de consulta pré-agregados são retornados automaticamente por um cache de agregações na memória, em vez de serem enviados e retornados pela fonte de dados. A quantidade de dados pré-agregados no cache de agregações na memória é uma pequena fração da quantidade de dados mantidos em tabelas de fatos e detalhes na fonte de dados. O resultado não é apenas um melhor desempenho da consulta de relatório, mas também uma carga reduzida nos sistemas de fonte de dados de back-end. Com agregações automáticas, apenas uma pequena parte das consultas de relatório e ad-hoc que exigem agregações não incluídas no cache na memória são passadas para a fonte de dados de back-end, assim como no modo DirectQuery puro.
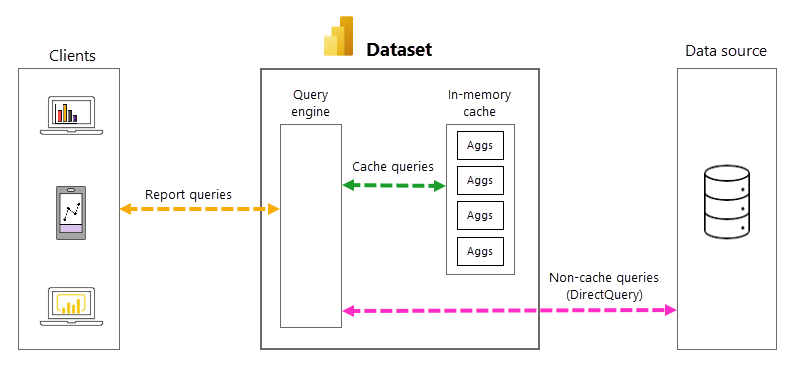
Gestão automática de consultas e agregações
Embora as agregações automáticas eliminem a necessidade de criar tabelas de agregação definidas pelo usuário e simplifiquem drasticamente a implementação de uma solução de dados pré-agregados, uma familiaridade mais profunda com os processos e dependências subjacentes é útil para entender como as agregações automáticas funcionam. O Power BI baseia-se no seguinte para criar e gerir agregações automáticas.
Registo de consultas
O Power BI rastreia consultas de relatório de modelo e usuário em um log de consulta. Para cada modelo, o Power BI mantém sete dias de dados de log de consulta. Os dados do log de consulta são rolados todos os dias. O log de consulta é seguro e não é visível para os usuários ou por meio do ponto de extremidade XMLA.
Ações de formação
Como parte da primeira operação de atualização de modelo agendada para a frequência selecionada (Dia ou Semana), o Power BI inicia primeiro uma operação de treinamento que avalia o log de consultas para garantir que as agregações no cache de agregações na memória se adaptem às mudanças nos padrões de consulta. As tabelas de agregação na memória são criadas, atualizadas ou descartadas, e consultas especiais são enviadas à fonte de dados para determinar as agregações a serem incluídas no cache. Os dados de agregações calculadas, no entanto, não são carregados no cache na memória durante o treinamento - são carregados durante a operação de atualização subsequente.
Por exemplo, se você escolher uma frequência de dia e a programação for atualizada às 4h00, 9h00, 14h00 e 19h00, somente a atualização de 4h00 a cada dia incluirá uma operação de treinamento e uma operação de atualização. As atualizações agendadas subsequentes das 9h00, 14h00 e 19h00 para esse dia são operações somente de atualização que atualizam as agregações existentes no cache.
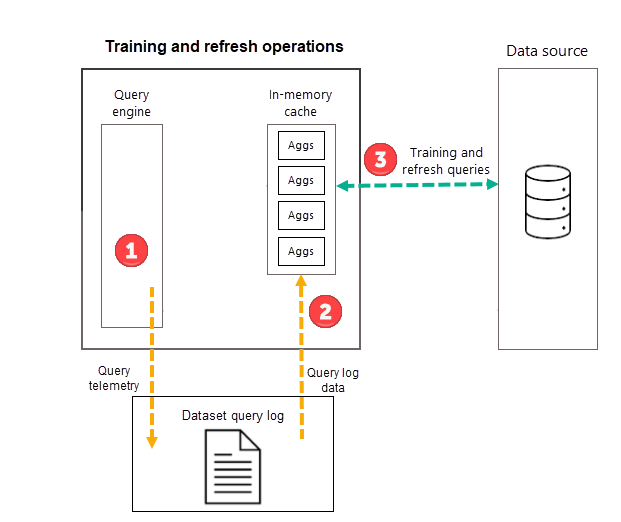
Embora as operações de treinamento avaliem consultas anteriores do log de consultas, os resultados são suficientemente precisos para garantir que consultas futuras sejam cobertas. No entanto, não há garantia de que consultas futuras serão retornadas pelo cache de agregações na memória, pois essas novas consultas podem ser diferentes daquelas derivadas do log de consultas. Essas consultas não retornadas pelo cache de agregações na memória são passadas para a fonte de dados usando DirectQuery. Dependendo da frequência e da classificação dessas novas consultas, as agregações para elas podem ser incluídas no cache de agregações na memória com a próxima operação de treinamento.
A operação de treinamento tem um limite de tempo de 60 minutos. Se o treinamento não conseguir processar todo o log de consultas dentro do limite de tempo, uma notificação será registrada no histórico de atualização do modelo e o treinamento será retomado na próxima vez que for iniciado. O ciclo de treinamento conclui e substitui as agregações automáticas existentes quando todo o log de consulta é processado.
Operações de atualização
Conforme descrito anteriormente, após a conclusão da operação de treinamento como parte da primeira atualização agendada para a frequência selecionada, o Power BI executa uma operação de atualização que consulta e carrega dados de agregações novos e atualizados no cache de agregações na memória e remove todas as agregações que não são mais classificadas como altas o suficiente (conforme determinado pelo algoritmo de treinamento). Todas as atualizações subsequentes para a frequência de Dia ou Semana escolhida são operações somente de atualização que consultam a fonte de dados para atualizar dados de agregações existentes no cache. Usando nosso exemplo anterior, as atualizações agendadas das 9h00, 14h00 e 19h00 para esse dia são operações somente de atualização.
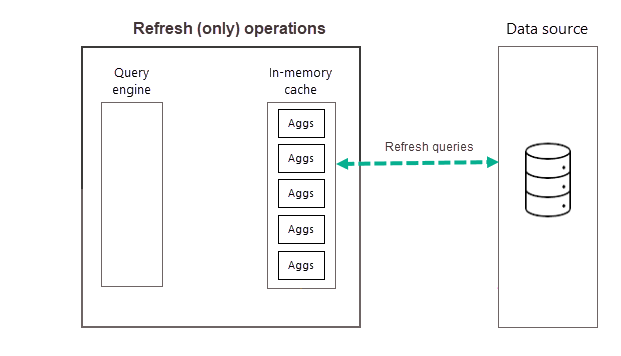
Atualizações agendadas regularmente ao longo do dia (ou da semana) garantem que os dados de agregações no cache estejam mais atualizados com os dados na fonte de dados de back-end. Por meio das Configurações do modelo, você pode agendar até 48 atualizações por dia para garantir que as consultas de relatório retornadas pelo cache de agregações obtenham resultados com base nos dados atualizados mais recentes da fonte de dados de back-end.
Atenção
As operações de treinamento e atualização consomem muitos processos e recursos para o serviço do Power BI e os sistemas de fonte de dados. Aumentar a porcentagem de consultas que usam agregações significa que mais agregações devem ser consultadas e calculadas a partir de fontes de dados durante as operações de treinamento e atualização, aumentando a probabilidade de uso excessivo de recursos do sistema e potencialmente causando tempos limites. Para saber mais, consulte Ajuste fino.
Formação a pedido
Como mencionado anteriormente, um ciclo de treinamento pode não ser concluído dentro dos limites de tempo de um único ciclo de atualização de dados. Se você não quiser esperar até o próximo ciclo de atualização agendado que inclui treinamento, você também pode acionar agregações automáticas de treinamento sob demanda selecionando Treinar e Atualizar agora em Configurações do modelo. Usando Train e Refresh Now dispara uma operação de treinamento e uma operação de atualização. Verifique o histórico de atualização do modelo para ver se a operação atual foi concluída antes de executar outra operação de treinamento e atualização sob demanda, se necessário.
Histórico de atualizações
Cada operação de atualização é registrada no histórico de atualização do modelo. Informações importantes sobre cada atualização são mostradas, incluindo o número de agregações de memória no cache que estão consumindo para a porcentagem de consulta configurada. Para visualizar o histórico de atualizações, na página Configurações do modelo, selecione Atualizar histórico. Se quiser detalhar um pouco mais, selecione Mostrar detalhes.

Ao verificar regularmente o histórico de atualizações, você pode garantir que suas operações de atualização agendadas sejam concluídas dentro de um período aceitável. Verifique se as operações de atualização foram concluídas com êxito antes que a próxima atualização agendada comece.
Falhas de treinamento e atualização
Enquanto o Power BI executa operações de treinamento e atualização como parte da primeira atualização agendada para o dia ou a frequência da semana que você escolher, essas operações são implementadas como transações separadas. Se uma operação de treinamento não puder processar totalmente o log de consulta dentro de seus limites de tempo, o Power BI continuará atualizando as agregações existentes (e tabelas regulares em um modelo composto) usando o estado de treinamento anterior. Nesse caso, o histórico de atualização indicará que a atualização foi bem-sucedida e o treinamento retomará o processamento do log de consultas na próxima vez que o treinamento for iniciado. O desempenho da consulta pode ser menos otimizado se os padrões de consulta do relatório do cliente forem alterados e as agregações ainda não forem ajustadas, mas o nível de desempenho alcançado ainda deve ser muito melhor do que um modelo DirectQuery puro sem agregações.
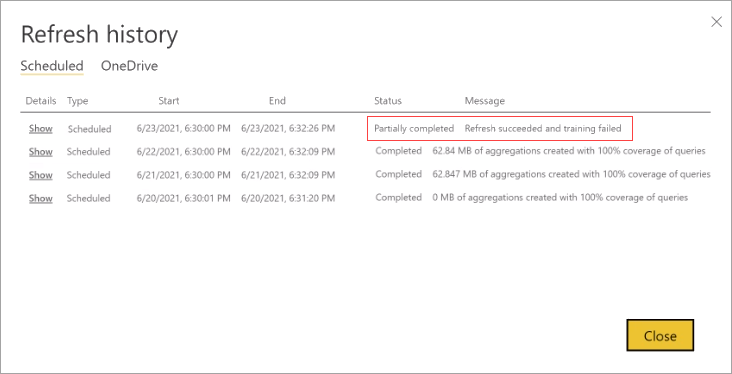
Se uma operação de treinamento exigir muitos ciclos para concluir o processamento do log de consulta, considere reduzir a porcentagem de consultas que usam o cache de agregações na memória nas Configurações do modelo. Isso reduzirá o número de agregações criadas no cache, mas permitirá mais tempo para a conclusão das operações de treinamento e atualização. Para saber mais, consulte Ajuste fino.
Se o treinamento for bem-sucedido, mas a atualização falhar, toda a atualização será marcada como Falha porque o resultado é um cache de agregações na memória indisponível.
Ao agendar a atualização, você pode especificar notificações por e-mail se houver falhas de atualização.
Agregações automáticas e definidas pelo utilizador
As agregações definidas pelo usuário no Power BI podem ser configuradas manualmente com base em tabelas agregadas ocultas no modelo. A configuração de agregações definidas pelo usuário geralmente é complexa, exigindo um nível maior de habilidades de modelagem de dados e otimização de consultas. As agregações automáticas, por outro lado, eliminam essa complexidade como parte de um sistema orientado por IA. Ao contrário das agregações definidas pelo usuário que permanecem estáticas, o Power BI mantém continuamente logs de consulta e, a partir desses logs, determina padrões de consulta com base em algoritmos de modelagem preditiva de aprendizado de máquina (ML). Os dados pré-agregados são calculados e armazenados na memória com base na análise de padrão de consulta. Com agregações automáticas, os modelos são autotreinados e autootimizados. À medida que os padrões de consulta de relatório do cliente mudam, as agregações automáticas se ajustam, priorizando e armazenando em cache as agregações usadas com mais frequência.
Como as agregações automáticas são criadas sobre a infraestrutura de agregações definida pelo usuário existente, é possível usar agregações definidas pelo usuário e agregações automáticas juntas no mesmo modelo. Modeladores de dados qualificados podem definir agregações para tabelas usando DirectQuery, Import (com ou sem atualização incremental) ou modos de armazenamento duplos, ao mesmo tempo em que têm os benefícios de agregações mais automáticas para consultas em conexões DirectQuery que não atingem as tabelas de agregação definidas pelo usuário. Essa flexibilidade permite arquiteturas equilibradas que podem reduzir as cargas de consulta e evitar gargalos.
As agregações criadas no cache na memória pelo algoritmo de treinamento de agregações automáticas são identificadas como System agregações. O algoritmo de treinamento cria e exclui apenas essas agregações à medida que System as consultas de relatório são analisadas e ajustes são feitos para manter as agregações ideais para o modelo. As agregações automáticas e definidas pelo usuário são atualizadas com a atualização. Apenas as agregações criadas por agregações automáticas e marcadas como agregações geradas pelo sistema são incluídas no processamento automático de agregações.
Cache de consultas e agregações automáticas
O Power BI Premium também oferece suporte ao cache de consultas no Power BI Premium/Embedded para manter os resultados da consulta. O cache de consultas é um recurso diferente das agregações automáticas. Com o cache de consulta, o Power BI Premium usa seu serviço de cache local para implementar o cache, enquanto as agregações automáticas são implementadas no nível do modelo. Com o cache de consultas, o serviço armazena em cache apenas consultas para o carregamento inicial da página de relatório, portanto, o desempenho da consulta não é melhorado quando os usuários interagem com um relatório. Por outro lado, as agregações automáticas otimizam a maioria das consultas de relatório pré-armazenando em cache os resultados de consultas agregadas, incluindo as consultas geradas quando os usuários interagem com relatórios. O cache de consultas e as agregações automáticas podem ser habilitados para um modelo, mas provavelmente não são necessários.
Monitorar com o Azure Log Analytics
O Azure Log Analytics (LA) é um serviço dentro do Azure Monitor que o Power BI pode usar para salvar logs de atividades. Com o pacote Azure Monitor, você pode coletar, analisar e agir em dados de telemetria de seus ambientes do Azure e locais. Ele oferece armazenamento de longo prazo, uma interface de consulta ad-hoc e acesso à API para permitir a exportação de dados e a integração com outros sistemas. Para saber mais, consulte Usando o Azure Log Analytics no Power BI.
Se o Power BI estiver configurado com uma conta do Azure LA, conforme descrito em Configurando o Azure Log Analytics para Power BI, você poderá analisar a taxa de sucesso de suas agregações automáticas. Entre outras coisas, você pode determinar se as consultas de relatório são respondidas a partir do cache na memória.
Para usar essa capacidade, baixe o modelo PBIT e conecte-o à sua conta de análise de log, conforme descrito nesta postagem do blog do Power BI. No relatório, você pode exibir dados em três níveis diferentes: modo de exibição de resumo, modo de exibição de nível de consulta DAX e modo de exibição de nível de consulta SQL.
A imagem a seguir mostra a página de resumo de todas as consultas. Como você pode ver, o gráfico marcado mostra a porcentagem do total de consultas que foram satisfeitas por agregações versus aquelas que tiveram que utilizar a fonte de dados.
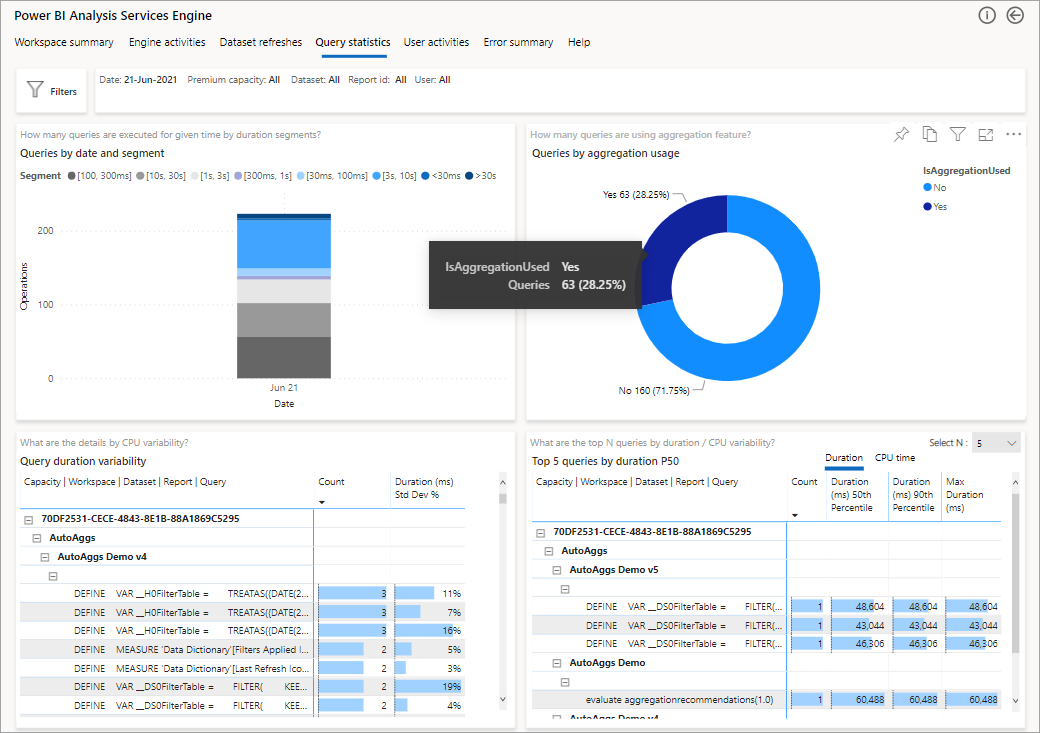
A próxima etapa para aprofundar é examinar o uso de agregações em um nível de consulta DAX. Clique com o botão direito do mouse em uma consulta DAX na lista (canto inferior esquerdo) >Detalhar o>histórico de consultas.
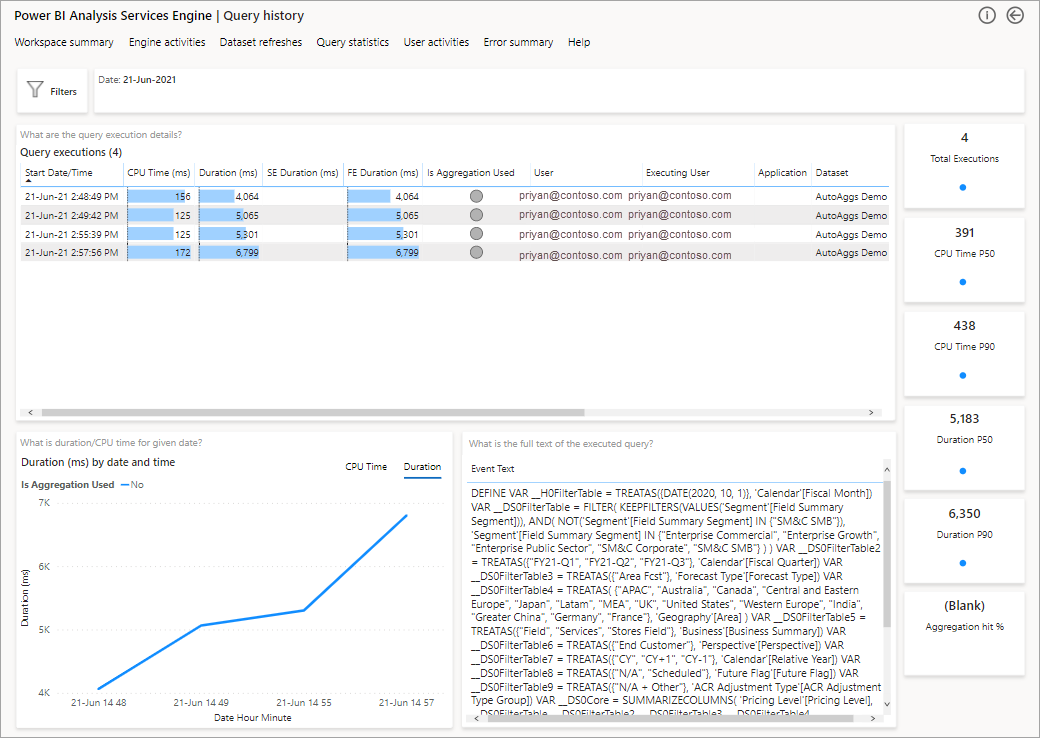
Isto irá fornecer-lhe uma lista de todas as questões pertinentes. Analise detalhadamente até o próximo nível para mostrar mais detalhes de agregação.
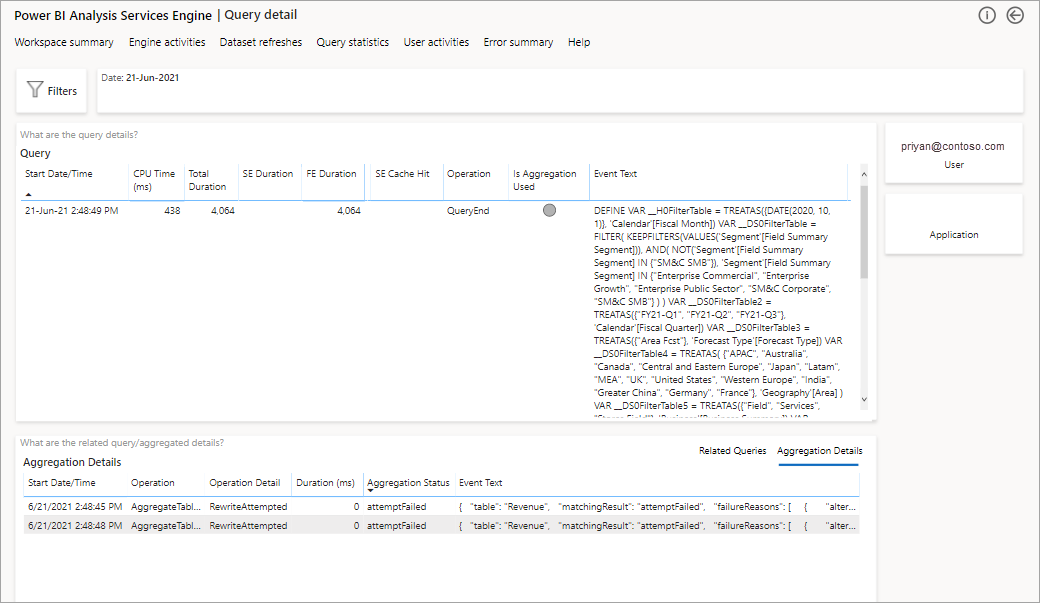
Gestão do Ciclo de Vida das Aplicações
Do desenvolvimento ao teste e do teste à produção, os modelos com agregações automáticas habilitadas têm requisitos especiais para soluções ALM.
Pipelines de implementação
Com os pipelines de implantação, o Power BI pode copiar os modelos com sua configuração de modelo do estágio atual para o estágio de destino. No entanto, as agregações automáticas devem ser redefinidas no estágio de destino, pois as configurações não são transferidas do estágio atual para o estágio de destino. Você também pode implantar conteúdo programaticamente, usando as APIs REST dos pipelines de implantação. Para saber mais sobre esse processo, consulte Automatizar seu pipeline de implantação usando APIs e DevOps.
Soluções de ALM personalizadas
Se você usar uma solução ALM personalizada baseada em pontos de extremidade XMLA, lembre-se de que sua solução pode copiar tabelas de agregações geradas pelo sistema e criadas pelo usuário como parte dos metadados do modelo. No entanto, você deve habilitar agregações automáticas após cada etapa de implantação no estágio de destino manualmente. O Power BI manterá a configuração se você substituir um modelo existente.
Nota
Se você carregar ou publicar novamente um modelo como parte de um arquivo do Power BI Desktop (.pbix), as tabelas de agregação criadas pelo sistema serão perdidas à medida que o Power BI substitui o modelo existente por todos os seus metadados e dados no espaço de trabalho de destino.
Alterar um modelo
Depois de alterar um modelo com agregações automáticas habilitadas por meio de pontos de extremidade XMLA, como adicionar ou remover tabelas, o Power BI preserva todas as agregações existentes que podem ser e remove aquelas que não são mais necessárias ou relevantes. O desempenho da consulta pode ser afetado até que a próxima fase de treinamento seja acionada.
Elementos de metadados
Os modelos com agregações automáticas ativadas contêm tabelas de agregações geradas pelo sistema exclusivas. As tabelas de agregação não são visíveis para os usuários nas ferramentas de relatório. Eles são visíveis por meio do ponto de extremidade XMLA usando ferramentas com bibliotecas de cliente do Analysis Services versão 19.22.5 e superior. Ao trabalhar com modelos com agregações automáticas habilitadas, certifique-se de atualizar suas ferramentas de modelagem e administração de dados para a versão mais recente das bibliotecas cliente. Para o SQL Server Management Studio (SSMS), atualize para o SSMS versão 18.9.2 ou superior. As versões anteriores do SSMS não são capazes de enumerar tabelas ou criar scripts desses modelos.
As tabelas de agregações automáticas são identificadas por uma SystemManaged propriedade table, que é nova no TOM (Tabular Object Model) nas bibliotecas de cliente do Analysis Services versão 19.22.5 e superior. O trecho de código a seguir mostra a propriedade definida como true para tabelas de SystemManaged agregações automáticas e false para tabelas regulares.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
A execução desse trecho gera tabelas de agregações automáticas atualmente incluídas no modelo em um console.
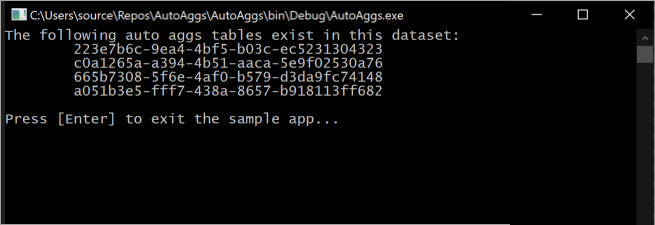
Lembre-se de que as tabelas de agregações estão mudando constantemente à medida que as operações de treinamento determinam as agregações ideais a serem incluídas no cache de agregações na memória.
Importante
O Power BI gerencia totalmente agregações automáticas de objetos de tabela gerados pelo sistema. Não exclua ou modifique essas tabelas por conta própria. Isso pode causar um desempenho degradado.
O Power BI mantém a configuração do modelo fora do modelo. A presença de uma tabela de agregações gerenciada pelo sistema em um modelo não significa necessariamente que o modelo esteja de fato habilitado para treinamento de agregações automáticas. Em outras palavras, se você criar um script para uma definição de modelo completa para um modelo com agregações automáticas habilitadas e criar uma nova cópia do modelo (com um nome/espaço de trabalho/capacidade diferente), o novo modelo resultante não será habilitado para treinamento de agregações automáticas. Você ainda precisa habilitar o treinamento de agregações automáticas para o novo modelo em Configurações do modelo.
Considerações e limitações
Ao usar agregações automáticas, tenha em mente o seguinte:
- As agregações não suportam parâmetros de consulta M dinâmicos.
- As consultas SQL geradas durante a fase de treinamento inicial podem gerar uma carga significativa para o data warehouse. Se o treinamento continuar terminando incompleto e você puder verificar no lado do data warehouse se as consultas estão encontrando um tempo limite, considere expandir temporariamente seu data warehouse para atender à demanda de treinamento.
- As agregações armazenadas no cache de agregações na memória podem não ser calculadas nos dados mais recentes na fonte de dados. Ao contrário do DirectQuery puro, e mais como tabelas de importação regulares, há uma latência entre as atualizações na fonte de dados e os dados de agregações armazenados no cache de agregações na memória. Embora sempre haja algum grau de latência, ela pode ser atenuada por meio de um cronograma de atualização eficaz.
- Para otimizar ainda mais o desempenho, defina todas as tabelas de dimensão para o modo Dual e deixe as tabelas de fatos no modo DirectQuery.
- As agregações automáticas não estão disponíveis com o Power BI Pro, Azure Analysis Services ou SQL Server Analysis Services.
- O Power BI não suporta a transferência de modelos com agregações automáticas ativadas. Se você carregou ou publicou um arquivo do Power BI Desktop (.pbix) no Power BI e, em seguida, habilitou as agregações automáticas, não poderá mais baixar o arquivo PBIX. Certifique-se de manter uma cópia do arquivo PBIX localmente.
- Não há suporte para agregações automáticas com tabelas externas no Azure Synapse Analytics. Você pode enumerar tabelas externas no Synapse usando a seguinte consulta SQL:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - As agregações automáticas só estão disponíveis para modelos que utilizam metadados melhorados. Se você quiser habilitar agregações automáticas para um modelo mais antigo, atualize o modelo para metadados aprimorados primeiro. Para saber mais, consulte Usando metadados de modelo avançados.
- Não habilite agregações automáticas se a fonte de dados DirectQuery estiver configurada para logon único e usar exibições de dados dinâmicas ou controles de segurança para limitar os dados que um usuário tem permissão para acessar. As agregações automáticas não estão cientes desses controles no nível da fonte de dados, o que torna impossível garantir que os dados corretos sejam fornecidos por usuário. O treinamento registrará um aviso no histórico de atualizações informando que detetou uma fonte de dados configurada para logon único e ignorou as tabelas que usam essa fonte de dados. Se possível, desabilite o SSO para essas fontes de dados para aproveitar ao máximo o desempenho otimizado da consulta que as agregações automáticas podem fornecer.
- Não habilite agregações automáticas se o modelo contiver apenas tabelas híbridas para evitar sobrecarga de processamento desnecessária. Uma tabela híbrida usa partições de importação e uma partição DirectQuery. Um cenário comum é a atualização incremental com dados em tempo real na qual uma partição DirectQuery busca transações da fonte de dados que ocorreram após a última atualização de dados. No entanto, o Power BI importa agregações durante a atualização. As agregações automáticas não podem incluir transações que ocorreram após a última atualização de dados. O treinamento registrará um aviso no histórico de atualizações que detetou e ignorou tabelas híbridas.
- As colunas calculadas não são consideradas para agregações automáticas. Se você usar uma coluna calculada no modo DirectQuery, como usando a
COMBINEVALUESfunção DAX para criar uma relação com base em várias colunas de duas tabelas DirectQuery, as consultas de relatório correspondentes não atingirão o cache de agregações na memória. - As agregações automáticas só estão disponíveis no serviço do Power BI. O Power BI Desktop não cria tabelas de agregações geradas pelo sistema.
- Se você modificar os metadados de um modelo com agregações automáticas habilitadas, o desempenho da consulta poderá diminuir até que o próximo processo de treinamento seja acionado. Como prática recomendada, você deve descartar as agregações automáticas, fazer as alterações e, em seguida, treinar novamente.
- Não modifique ou exclua tabelas de agregações geradas pelo sistema, a menos que você tenha as agregações automáticas desabilitadas e esteja limpando o modelo. O sistema assume a responsabilidade pelo gerenciamento desses objetos.
Comunidade
O Power BI tem uma comunidade vibrante onde MVPs, profissionais de BI e colegas compartilham conhecimentos em grupos de discussão, vídeos, blogs e muito mais. Ao aprender sobre agregações automáticas, não deixe de conferir estes outros recursos: