Cenários de tabelas computadas e casos de uso
Há benefícios em usar tabelas computadas em um fluxo de dados. Este artigo descreve casos de uso para tabelas computadas e descreve como elas funcionam nos bastidores.
O que é uma tabela calculada?
Uma tabela representa a saída de dados de uma consulta criada em um fluxo de dados, depois que o fluxo de dados foi atualizado. Ele representa dados de uma fonte e, opcionalmente, as transformações que foram aplicadas a ela. Às vezes, você pode querer criar novas tabelas que são uma função de uma tabela ingerida anteriormente.
Embora seja possível repetir as consultas que criaram uma tabela e aplicar novas transformações a elas, essa abordagem tem desvantagens: os dados são ingeridos duas vezes e a carga na fonte de dados é dobrada.
As tabelas computadas resolvem ambos os problemas. As tabelas computadas são semelhantes a outras tabelas, pois obtêm dados de uma fonte e você pode aplicar outras transformações para criá-las. Mas seus dados se originam do fluxo de dados de armazenamento usado, e não da fonte de dados original. Ou seja, eles foram previamente criados por um fluxo de dados e depois reutilizados.
As tabelas computadas podem ser criadas fazendo referência a uma tabela no mesmo fluxo de dados ou fazendo referência a uma tabela criada em um fluxo de dados diferente.

Por que usar uma tabela calculada?
A execução de todas as etapas de transformação em uma tabela pode ser lenta. Pode haver muitos motivos para essa lentidão: a fonte de dados pode ser lenta ou as transformações que você está fazendo podem precisar ser replicadas em duas ou mais consultas. Pode ser vantajoso primeiro ingerir os dados da fonte e, em seguida, reutilizá-los em uma ou mais tabelas. Nesses casos, você pode optar por criar duas tabelas: uma que obtém dados da fonte de dados e outra — uma tabela computada — que aplica mais transformações a dados já gravados no data lake usado por um fluxo de dados. Esta alteração pode aumentar o desempenho e a reutilização dos dados, poupando tempo e recursos.
Por exemplo, se duas tabelas partilham mesmo uma parte da sua lógica de transformação, sem uma tabela calculada, a transformação tem de ser feita duas vezes.
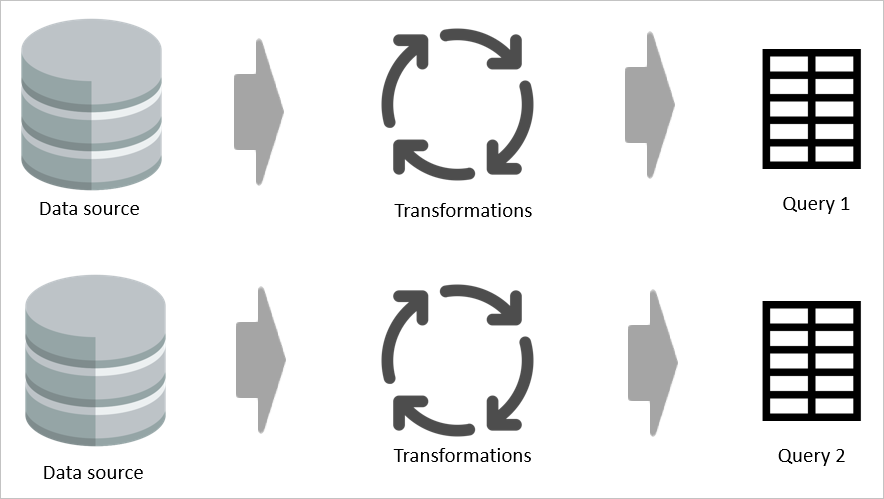
No entanto, se uma tabela computada for usada, a parte comum (compartilhada) da transformação será processada uma vez e armazenada no Armazenamento do Azure Data Lake. As transformações restantes são então processadas a partir da saída da transformação comum. No geral, esse processamento é muito mais rápido.
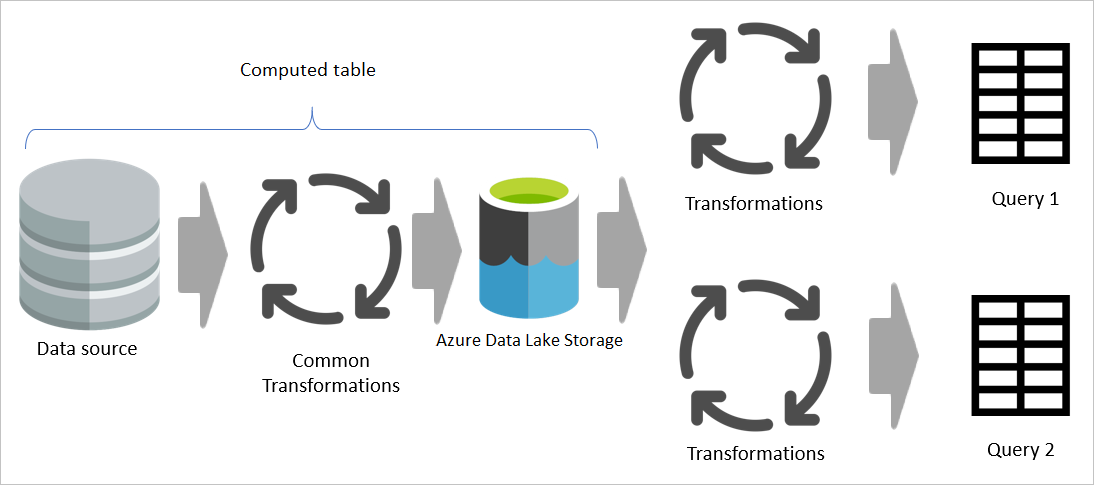
Uma tabela computada fornece um local como código-fonte para a transformação e acelera a transformação porque ela só precisa ser feita uma vez, em vez de várias vezes. A carga na fonte de dados também é reduzida.
Cenário de exemplo para usar uma tabela computada
Se você estiver criando uma tabela agregada no Power BI para acelerar o modelo de dados, poderá criar a tabela agregada fazendo referência à tabela original e aplicando mais transformações a ela. Usando essa abordagem, você não precisa replicar sua transformação da origem (a parte que é da tabela original).
Por exemplo, a figura a seguir mostra uma tabela Pedidos.

Usando uma referência desta tabela, você pode criar uma tabela calculada.
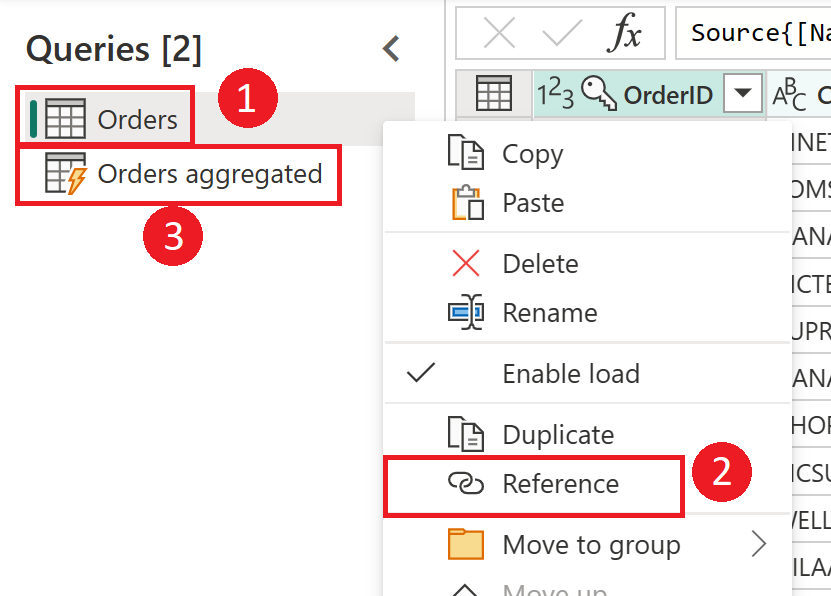
Captura de tela mostrando como criar uma tabela computada a partir da tabela Pedidos. Primeiro, clique com o botão direito do mouse na tabela Pedidos no painel Consultas, selecione a opção Referência no menu suspenso. Essa ação cria a tabela computada, que é renomeada aqui para Pedidos agregados.
A tabela computada pode ter outras transformações. Por exemplo, você pode usar Agrupar por para agregar os dados no nível do cliente.
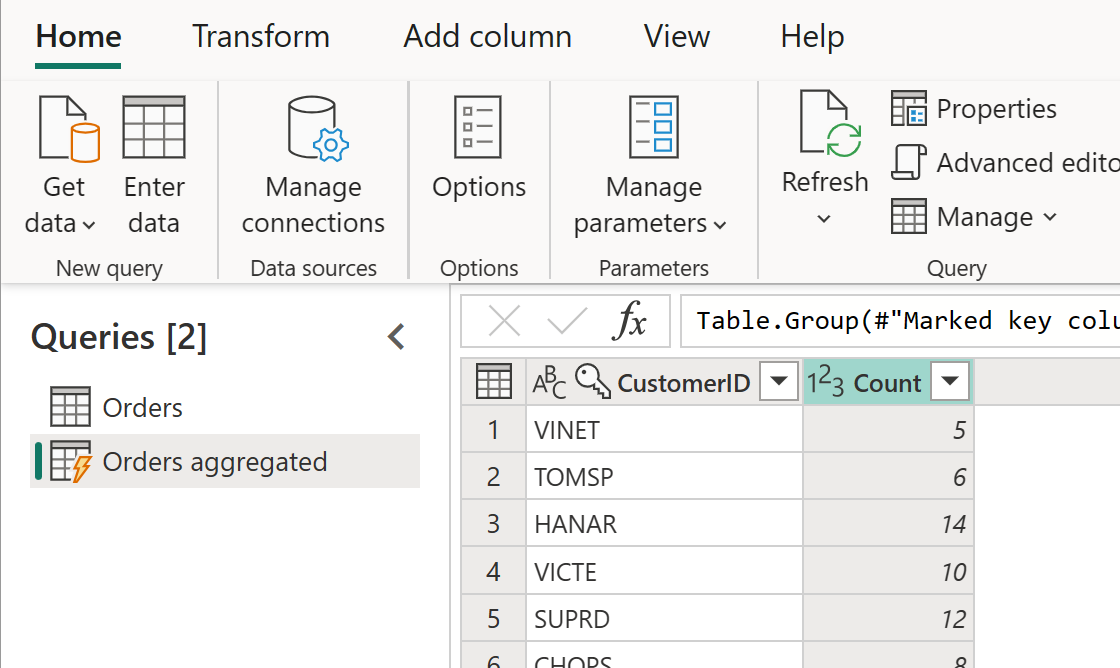
Isso significa que a tabela Pedidos agregados está recebendo dados da tabela Pedidos, e não da fonte de dados novamente. Como algumas das transformações que precisam ser feitas já foram feitas na tabela Pedidos, o desempenho é melhor e a transformação de dados é mais rápida.
Tabela computada em outros fluxos de dados
Você também pode criar uma tabela computada em outros fluxos de dados. Ele pode ser criado obtendo dados de um fluxo de dados com o conector de fluxo de dados da Microsoft Power Platform.
A imagem enfatiza o conector de fluxos de dados da Power Platform na janela de escolha da fonte de dados do Power Query. Também está incluída uma descrição que afirma que uma tabela de fluxo de dados pode ser criada sobre os dados de outra tabela de fluxo de dados, que já está persistida no armazenamento.
O conceito da tabela computada é ter uma tabela persistente no armazenamento e outras tabelas originadas dela, para que você possa reduzir o tempo de leitura da fonte de dados e compartilhar algumas das transformações comuns. Essa redução pode ser obtida obtendo dados de outros fluxos de dados através do conector de fluxo de dados ou fazendo referência a outra consulta no mesmo fluxo de dados.
Tabela computada: Com transformações ou sem?
Agora que você sabe que as tabelas computadas são ótimas para melhorar o desempenho da transformação de dados, uma boa pergunta a ser feita é se as transformações devem sempre ser adiadas para a tabela computada ou se devem ser aplicadas à tabela de origem. Ou seja, os dados devem ser sempre ingeridos em uma tabela e depois transformados em uma tabela computada? Quais são os prós e contras?
Carregue dados sem transformação para arquivos de texto/CSV
Quando uma fonte de dados não oferece suporte à dobragem de consultas (como arquivos de texto/CSV), há poucos benefícios em aplicar transformações ao obter dados da fonte, especialmente se os volumes de dados forem grandes. A tabela de origem deve apenas carregar dados do arquivo Text/CSV sem aplicar nenhuma transformação. Em seguida, as tabelas computadas podem obter dados da tabela de origem e executar a transformação sobre os dados ingeridos.
Você pode perguntar, qual é o valor de criar uma tabela de origem que apenas ingere dados? Essa tabela ainda pode ser útil, porque se os dados da fonte forem usados em mais de uma tabela, isso reduz a carga na fonte de dados. Além disso, os dados agora podem ser reutilizados por outras pessoas e fluxos de dados. As tabelas computadas são especialmente úteis em cenários em que o volume de dados é grande ou quando uma fonte de dados é acessada por meio de um gateway de dados local, porque reduzem o tráfego do gateway e a carga nas fontes de dados por trás delas.
Fazendo algumas das transformações comuns para uma tabela SQL
Se sua fonte de dados oferecer suporte à dobragem de consulta, é bom executar algumas das transformações na tabela de origem porque a consulta é dobrada para a fonte de dados e somente os dados transformados são buscados a partir dela. Estas alterações melhoram o desempenho global. O conjunto de transformações que é comum em tabelas computadas a jusante deve ser aplicado na tabela de origem, para que possam ser dobradas para a fonte. Outras transformações que se aplicam apenas a tabelas a jusante devem ser feitas em tabelas computadas.