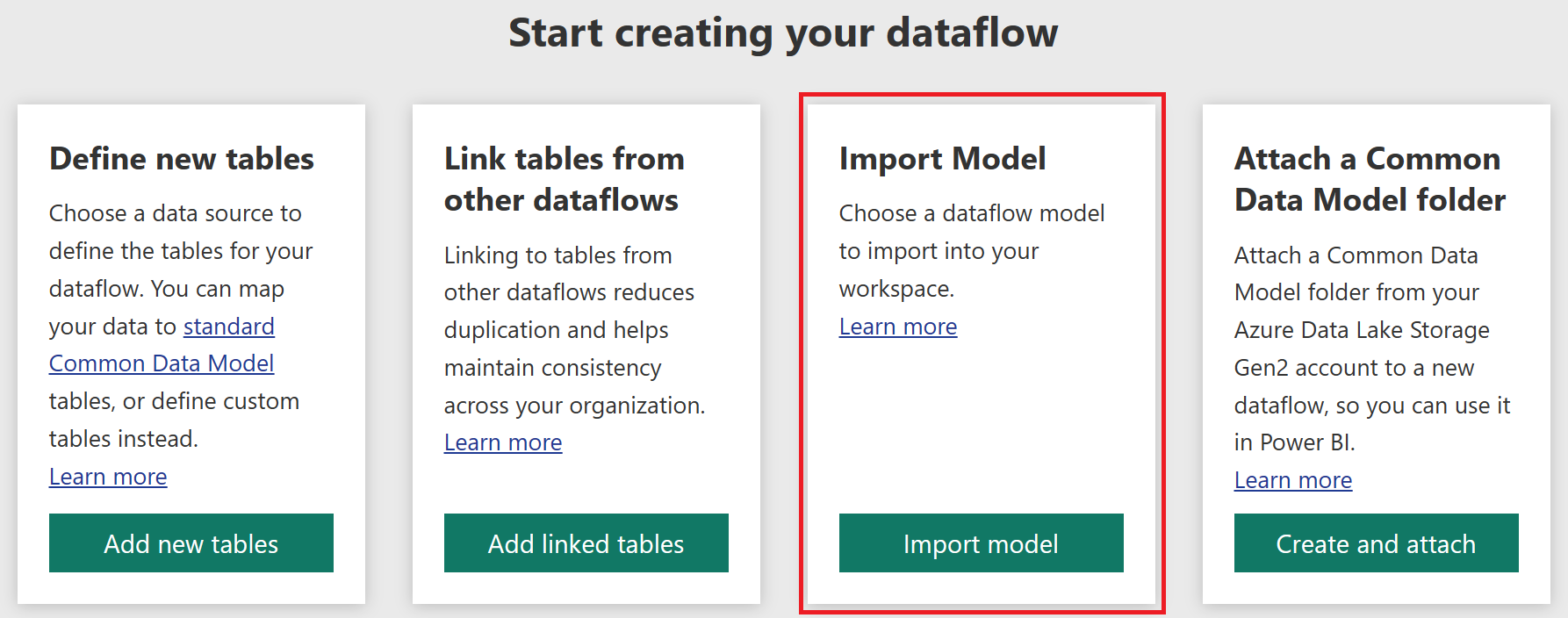
Qual é a estrutura de armazenamento para fluxos de dados analíticos?
Os fluxos de dados analíticos armazenam dados e metadados no Armazenamento Azure Data Lake. Os fluxos de dados aproveitam uma estrutura padrão para armazenar e descrever dados criados no lago, que é chamado de pastas Common Data Model. Neste artigo, você aprenderá mais sobre o padrão de armazenamento que os fluxos de dados usam nos bastidores.
O armazenamento precisa de uma estrutura para um fluxo de dados analítico
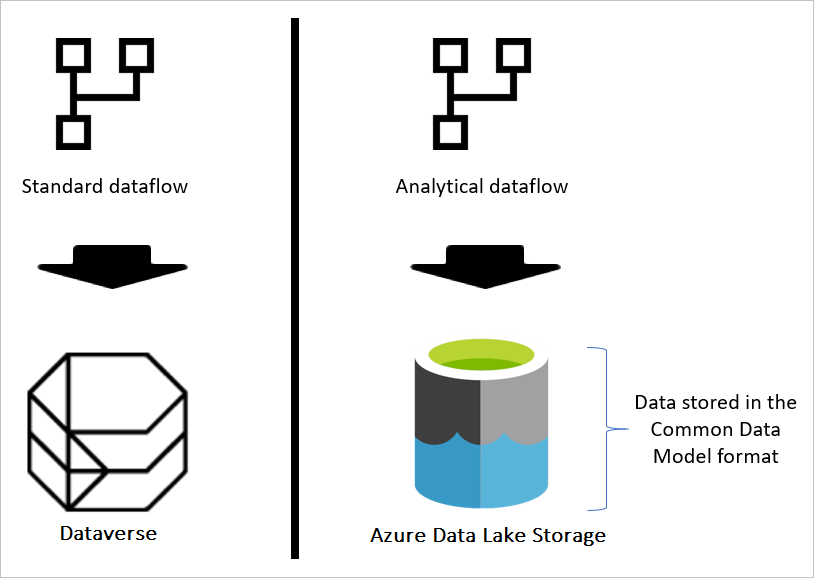
Se o fluxo de dados for padrão, os dados serão armazenados no Dataverse. Dataverse é como um sistema de banco de dados; tem o conceito de tabelas, visualizações e assim por diante. O Dataverse é uma opção de armazenamento de dados estruturados usada por fluxos de dados padrão.
No entanto, quando o fluxo de dados é analítico, os dados são armazenados no Armazenamento do Azure Data Lake. Os dados e metadados de um fluxo de dados são armazenados em uma pasta Common Data Model. Como uma conta de armazenamento pode ter vários fluxos de dados armazenados nela, uma hierarquia de pastas e subpastas foi introduzida para ajudar a organizar os dados. Dependendo do produto em que o fluxo de dados foi criado, as pastas e subpastas podem representar espaços de trabalho (ou ambientes) e, em seguida, a pasta Common Data Model do fluxo de dados. Dentro da pasta Common Data Model, o esquema e os dados das tabelas de fluxo de dados são armazenados. Essa estrutura segue os padrões definidos para o Common Data Model.
O que é a estrutura de armazenamento do Common Data Model?
O Common Data Model é uma estrutura de metadados definida para trazer conformidade e consistência para o uso de dados em várias plataformas. Common Data Model não é armazenamento de dados, é a forma como os dados são armazenados e definidos.
As pastas Common Data Model definem como o esquema de uma tabela e seus dados devem ser armazenados. No Armazenamento do Azure Data Lake, os dados são organizados em pastas. As pastas podem representar um espaço de trabalho ou ambiente. Nessas pastas, são criadas subpastas para cada fluxo de dados.
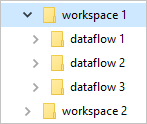
O que há em uma pasta de fluxo de dados?
Cada pasta de fluxo de dados contém uma subpasta para cada tabela e um arquivo de metadados chamado model.json.
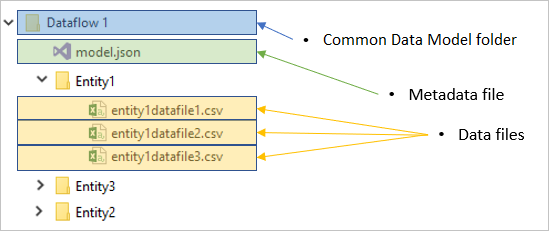
O arquivo de metadados: model.json
O model.json arquivo é a definição de metadados do fluxo de dados. Este é o único arquivo que contém todos os metadados de fluxo de dados. Ele inclui uma lista de tabelas, as colunas e seus tipos de dados em cada tabela, a relação entre tabelas e assim por diante. Você pode exportar esse arquivo de um fluxo de dados facilmente, mesmo que não tenha acesso à estrutura de pastas do Common Data Model.
Você pode usar esse arquivo JSON para migrar (ou importar) seu fluxo de dados para outro espaço de trabalho ou ambiente.
Para saber exatamente o que o arquivo de metadados model.json inclui, vá para O arquivo de metadados (model.json) para Common Data Model.
Ficheiros de dados
Além do arquivo de metadados, a pasta de fluxo de dados inclui outras subpastas. Um fluxo de dados armazena os dados de cada tabela em uma subpasta com o nome da tabela. Os dados de uma tabela podem ser divididos em várias partições de dados, armazenadas no formato CSV.
Como ver ou acessar pastas do Common Data Model
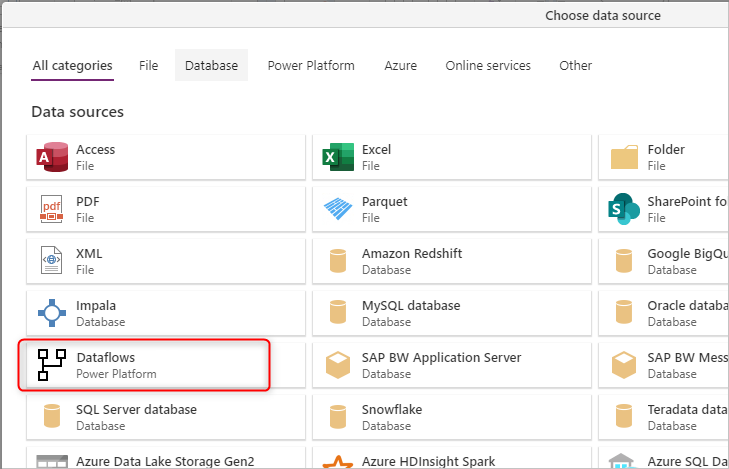
Se você estiver usando fluxos de dados que usam o armazenamento fornecido pelo produto em que foram criados, não terá acesso a essas pastas diretamente. Nesses casos, obter dados dos fluxos de dados requer o uso do conector de fluxo de dados da Microsoft Power Platform disponível em Obter experiência de dados no serviço Power BI, Power Apps e produtos Dynamics 35 Customer Insights ou no Power BI Desktop.
Para saber como funcionam os fluxos de dados e a integração interna do Armazenamento Data Lake, vá para Fluxos de Dados e Integração do Azure Data Lake (Visualização).
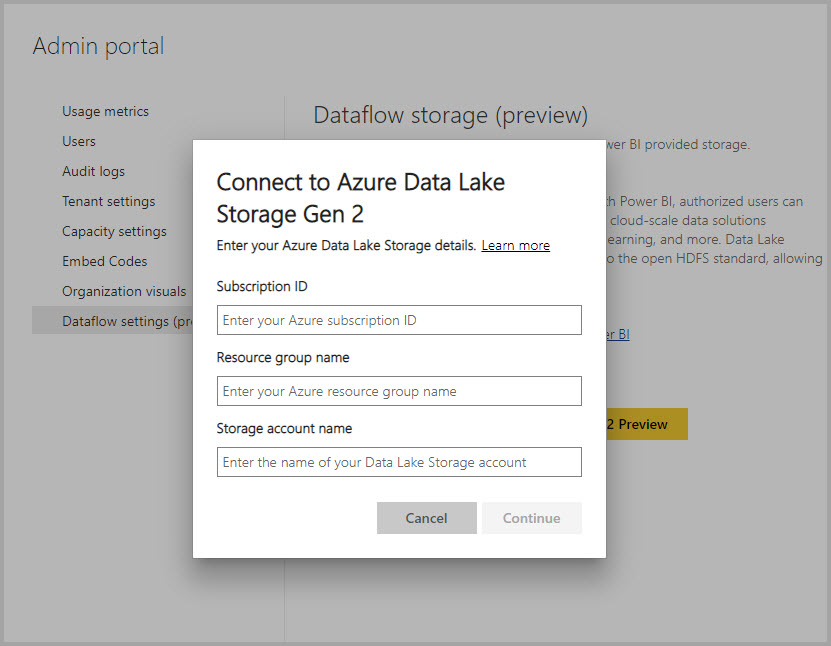
Se sua organização habilitou fluxos de dados para aproveitar sua conta de Armazenamento Data Lake e foi selecionada como um destino de carga para fluxos de dados, você ainda poderá obter dados do fluxo de dados usando o conector de fluxo de dados da Plataforma de Energia, conforme mencionado acima. Mas você também pode acessar a pasta Common Data Model do fluxo de dados diretamente através do lago, mesmo fora das ferramentas e serviços da Power Platform. O acesso ao lago é possível através do portal do Azure, do Microsoft Azure Storage Explorer ou de qualquer outro serviço ou experiência que suporte o Armazenamento do Azure Data Lake. Mais informações: Ligar o Azure Data Lake Storage Gen2 para armazenamento de fluxo de dados
Próximos passos
Usar o Modelo de Dados Comum para otimizar o Azure Data Lake Storage Gen2
O arquivo de metadados (model.json) para o Common Data Model
Adicionar uma pasta CDM ao Power BI como um fluxo de dados (Pré-visualização)
Ligar o Azure Data Lake Storage Gen2 para armazenamento de fluxo de dados
Fluxos de dados e integração do Azure Data Lake (visualização)
Configurar definições do fluxo de dados da área de trabalho (Pré-visualização)