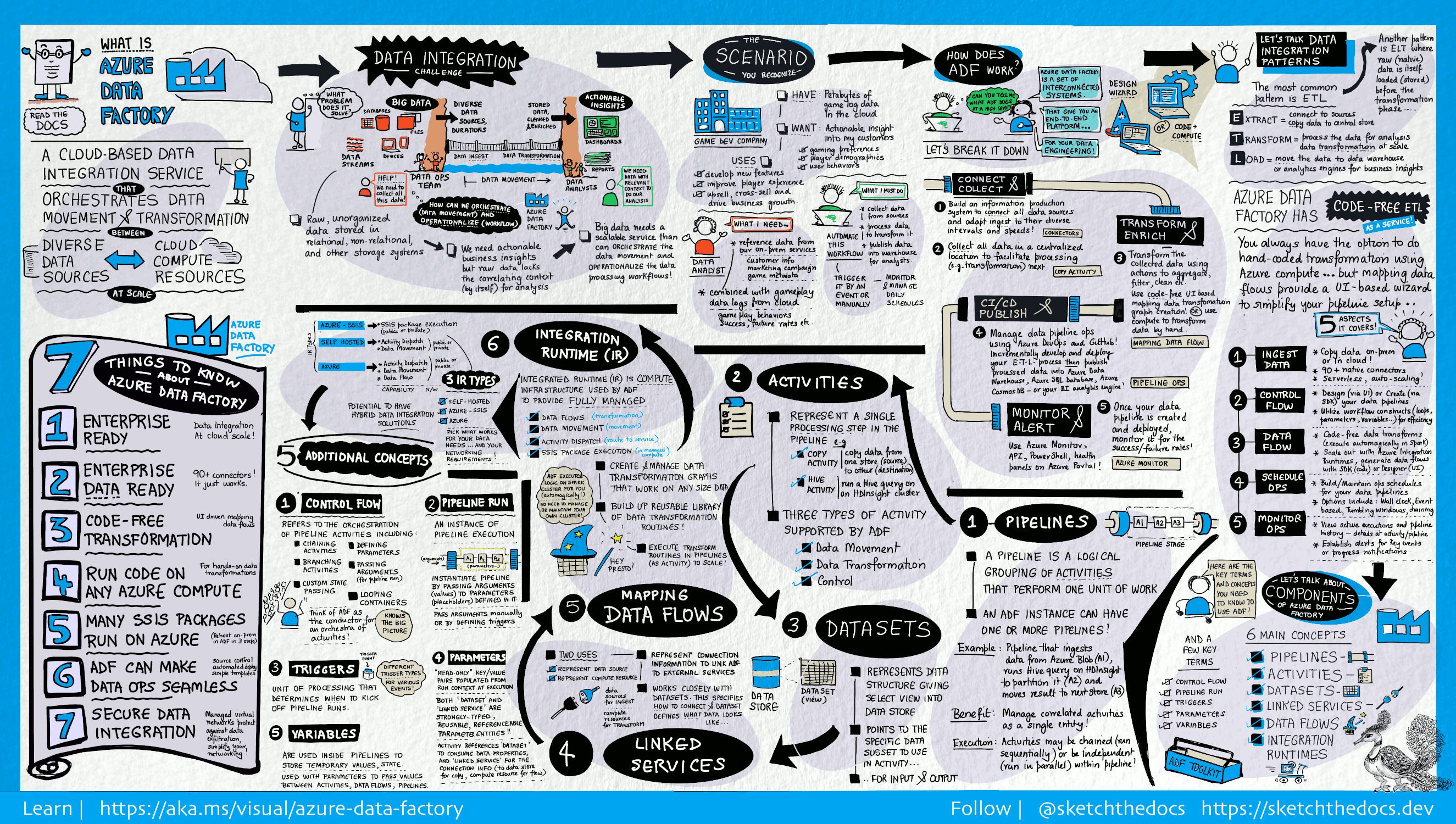
O que é o Azure Data Factory?
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
No mundo dos macrodados, muitas vezes, são armazenados dados desorganizados e não processados em sistemas relacionais, não relacionais, entre outros. No entanto, por si só, os dados não processados não têm o contexto ou o significado adequado para disponibilizar informações significativas para analistas, cientistas de dados ou decisores empresariais.
O Big Data requer um serviço que possa orquestrar e operacionalizar processos para refinar esses enormes armazenamentos de dados brutos em insights de negócios acionáveis. O Azure Data Factory é um serviço na cloud gerido criado para estes projetos complexos e híbridos de extract-transform-load (ETL), extract-load-transform (ELT) e integração de dados.
Recursos do Azure Data Factory
Compressão de dados: Durante a atividade de cópia de dados, é possível compactar os dados e gravar os dados compactados na fonte de dados de destino. Esse recurso ajuda a otimizar o uso da largura de banda na cópia de dados.
Suporte extensivo de conectividade para diferentes fontes de dados: o Azure Data Factory fornece amplo suporte de conectividade para conexão com diferentes fontes de dados. Isso é útil quando você deseja extrair ou gravar dados de diferentes fontes de dados.
Gatilhos de eventos personalizados: o Azure Data Factory permite automatizar o processamento de dados usando gatilhos de eventos personalizados. Este recurso permite que você execute automaticamente uma determinada ação quando um determinado evento ocorre.
Pré-visualização e validação de dados: durante a atividade de cópia de dados, são fornecidas ferramentas para pré-visualizar e validar dados. Esse recurso ajuda a garantir que os dados sejam copiados corretamente e gravados corretamente na fonte de dados de destino.
Fluxos de dados personalizáveis: o Azure Data Factory permite criar fluxos de dados personalizáveis. Esse recurso permite que você adicione ações ou etapas personalizadas para o processamento de dados.
Segurança integrada: o Azure Data Factory oferece recursos de segurança integrados, como integração do Entra ID e controle de acesso baseado em função para controlar o acesso aos fluxos de dados. Esta funcionalidade aumenta a segurança no processamento de dados e protege os seus dados.
Cenários de utilização
Por exemplo, imagine uma empresa de jogos que recolhe petabytes de registos de jogos que são produzidos por jogos na cloud. A empresa pretende analisar esses registos para obter informações sobre as preferências do cliente, os dados demográficos e o comportamento de utilização. Quer também identificar as oportunidades de vendas superiores e vendas cruzadas, desenvolver funcionalidades novas e apelativas, impulsionar o crescimento do negócio e proporcionar uma melhor experiência aos clientes.
Para analisar estes registos, a empresa tem de utilizar dados de referência, como informações do cliente, informações do jogo, informações de campanhas de marketing, que se encontram num arquivo de dados no local. A empresa quer utilizar estes dados a partir do arquivo de dados no local e combiná-los com os dados de registos adicionais que tem num arquivo de dados na cloud.
Para extrair insights, espera processar os dados associados usando um cluster do Spark na nuvem (Azure HDInsight) e publicar os dados transformados em um armazém de dados na nuvem, como o Azure Synapse Analytics, para criar facilmente um relatório sobre ele. Pretende automatizar este fluxo de trabalho e monitorizá-lo e geri-lo diariamente. Pretende também executá-lo quando os ficheiros estiverem num contentor de arquivo de blobs.
O Azure Data Factory é a plataforma que resolve estes cenários de dados. É o ETL baseado em nuvem e serviço de integração de dados que permite criar fluxos de trabalho orientados por dados para orquestrar a movimentação de dados e transformar dados em escala. Ao utilizar o Azure Data Factory, pode criar e agendar fluxos de trabalho condicionados por dados (denominados pipelines) que podem ingerir dados a partir de arquivos de dados diferentes. Você pode criar processos ETL complexos que transformam dados visualmente com fluxos de dados ou usando serviços de computação como o Azure HDInsight Hadoop, Azure Databricks e Banco de Dados SQL do Azure.
Além disso, você pode publicar seus dados transformados em armazenamentos de dados, como o Azure Synapse Analytics para aplicativos de business intelligence (BI) consumirem. Em última análise, através do Azure Data Factory, os dados não processados podem ser organizados em arquivos de dados relevantes e em data lakes para uma melhor tomada de decisões empresariais.
Como é que isto funciona?
O Data Factory contém uma série de sistemas interligados que fornecem uma plataforma ponto a ponto completa para engenheiros de dados.

Este guia visual fornece uma visão geral detalhada da arquitetura completa do Data Factory:

Para ver mais detalhes, selecione a imagem anterior para ampliar ou navegue até a imagem de alta resolução.
{kind=link}
Ligar e recolher
As empresas têm dados dos mais diversos tipos localizados em diferentes origens, seja no local, na cloud, estruturadas, não estruturadas e semi-estruturadas, que são recebidos em intervalos e velocidades distintos.
O primeiro passo na criação de um sistema de produção de informação é ligar a todas as origens de dados e processamento necessários, como serviços de software como serviços de software como serviço (SaaS), bases de dados, partilhas de ficheiros e serviços Web de FTP. O passo seguinte é mover os dados conforme necessário para uma localização centralizada, para processamento subsequente.
Sem o Data Factory, as empresas têm de criar componentes de movimento de dados personalizados ou escrever serviços personalizados para integrar essas origens de dados e esse processamento. Integrar e manter estes sistemas é dispendioso e difícil. Além disso, muitas vezes, não têm monitorização, alertas e controlos de nível empresarial que um serviço totalmente gerido pode oferecer.
Com o Data Factory, pode utilizar a Atividade de Cópia num pipeline de dados para mover dados de arquivos de dados no local e na cloud para um arquivo centralizado na cloud, para análises adicionais. Por exemplo, você pode coletar dados no Armazenamento do Azure Data Lake e transformá-los posteriormente usando um serviço de computação do Azure Data Lake Analytics. Também pode recolher dados no armazenamento de blobs do Azure e transformá-los mais tarde com um cluster do Azure HDInsight Hadoop.
Transformar e enriquecer
Depois que os dados estiverem presentes em um armazenamento de dados centralizado na nuvem, processe ou transforme os dados coletados usando fluxos de dados de mapeamento do ADF. Os fluxos de dados permitem que os engenheiros de dados criem e mantenham gráficos de transformação de dados que são executados no Spark sem a necessidade de entender os clusters do Spark ou a programação do Spark.
Se você preferir codificar transformações manualmente, o ADF oferece suporte a atividades externas para executar suas transformações em serviços de computação, como HDInsight Hadoop, Spark, Data Lake Analytics e Machine Learning.
CI/CD e publicar
O Data Factory oferece suporte completo para CI/CD de seus pipelines de dados usando o Azure DevOps e o GitHub. Isso permite que você desenvolva e entregue incrementalmente seus processos de ETL antes de publicar o produto acabado. Depois que os dados brutos tiverem sido refinados em um formulário consumível pronto para os negócios, carregue os dados no Azure Data Warehouse, no Banco de Dados SQL do Azure, no Azure Cosmos DB ou em qualquer mecanismo de análise para o qual seus usuários corporativos possam apontar a partir de suas ferramentas de business intelligence.
Monitor
Depois de criar e implementar com êxito o seu pipeline de integração de dados, proporcionando valor comercial a partir dos dados refinados, monitorize as atividades e os pipelines agendados relativamente às taxas de êxito e falha. O Azure Data Factory tem suporte interno para monitoramento de pipeline por meio do Azure Monitor, API, PowerShell, logs do Azure Monitor e painéis de integridade no portal do Azure.
Principais conceitos
As subscrições do Azure podem ter uma ou várias instâncias do Azure Data Factory (ou fábricas de dados). O Azure Data Factory é composto pelos seguintes componentes principais:
- Pipelines
- Atividades
- Conjuntos de Dados
- Serviços ligados
- Fluxos de Dados
- Integration Runtimes
Estes componentes funcionam em conjunto para fornecer a plataforma na qual pode compor fluxos de trabalho orientados por dados com passos para mover e transformar dados.
Pipeline
Uma fábrica de dados pode ter um ou mais pipelines. Um pipeline é um agrupamento lógico de atividades que executa uma unidade de trabalho. Em conjunto, as atividades num pipeline executam uma tarefa. Por exemplo, um pipeline pode conter um grupo de atividades que ingere dados de um blob do Azure e, em seguida, executa uma consulta de Hive num cluster do HDInsight para particionar os dados.
A vantagem neste caso é que o pipeline lhe permite gerir as atividades como um conjunto, em vez de individualmente. As atividades num pipeline podem ser encadeadas para funcionar sequencialmente ou podem funcionar de forma independente em paralelo
Fluxos de dados de mapeamento
Crie e gerencie gráficos da lógica de transformação de dados que você pode usar para transformar dados de qualquer tamanho. Você pode criar uma biblioteca reutilizável de rotinas de transformação de dados e executar esses processos de forma escalonada a partir de seus pipelines do ADF. O Data Factory executará sua lógica em um cluster do Spark que gira para cima e para baixo quando você precisar. Você nunca precisará gerenciar ou manter clusters.
Atividade
As atividades representam uma fase de processamento num pipeline. Por exemplo, pode utilizar uma atividade de cópia para copiar dados de um arquivo de dados para outro. Da mesma forma, pode utilizar uma atividade do Hive, que executa uma consulta do Hive num cluster do Azure HDInsight, para transformar ou analisar os seus dados. O Data Factory suporta três tipos de atividades: atividades de movimento de dados, atividades de transformação de dados e atividades de controlo.
Conjuntos de Dados
Os conjuntos de dados representam estruturas de dados nos arquivos de dados, que simplesmente apontam ou referenciam os dados que pretende utilizar nas suas atividades como entrada ou saída.
Serviços ligados
Os serviços ligados são muito semelhantes às cadeias de ligação, que definem as informações de ligação necessárias para que o Data Factory se possa ligar a recursos externos. Encare da seguinte forma: um serviço ligado define a ligação à origem de dados e um conjunto de dados representa a estrutura dos dados. Por exemplo, um serviço ligado do Armazenamento do Azure especifica a cadeia de ligação para ligar à conta do Armazenamento do Azure. Além disso, um conjunto de dados de blobs do Azure especifica o contentor de blobs e a pasta que contém os dados.
Os serviços ligados são utilizados para duas finalidades no Data Factory:
Para representar um armazenamento de dados que inclui, mas não está limitado a, um banco de dados SQL Server, banco de dados Oracle, compartilhamento de arquivos ou conta de armazenamento de blob do Azure. Para obter uma lista dos arquivos de dados suportados, veja o artigo copy activity (Atividade de Cópia).
Para representar um recurso de computação que pode alojar a execução de uma atividade. Por exemplo, a Atividade HDInsightHive é executada num cluster do HDInsight Hadoop. Para obter uma lista das atividades de transformação e os ambientes de computação suportados, veja o artigo Transform data (Transformar dados).
Runtime de Integração
No Data Factory, as atividades definem as ações que vão ser realizadas. Os serviços ligados definem um arquivo de dados ou um serviço de computação de destino. Os runtimes de integração estabelecem a ponte entre a atividade e os serviços ligados. Ele é referenciado pelo serviço ou atividade vinculado e fornece o ambiente de computação no qual a atividade é executada ou despachada. Desta forma, a atividade pode ser realizada na região mais perto possível do arquivo de dados ou do serviço de computação de destino com o melhor desempenho possível, satisfazendo as necessidades de segurança e conformidade.
Acionadores
Os acionadores representam a unidade de processamento que determina quando é que uma execução de pipeline tem de arrancar. Existem diferentes tipos de acionadores para diferentes tipos de eventos.
Execuções de pipeline
As instâncias de pipeline são instâncias da execução dos pipelines. Normalmente, as execuções de pipeline são instanciadas pela transmissão de argumentos aos parâmetros definidos nos pipelines. Os argumentos podem ser transmitidos manualmente ou na definição do acionador.
Parâmetros
Os parâmetros são pares chave-valor de configuração só de leitura. Os parâmetros são definidos no pipeline. Os argumentos para os parâmetros definidos são transmitidos durante a execução a partir do contexto da instância criado por um acionador ou por um pipeline executado manualmente. As atividades dentro do pipeline consomem os valores dos parâmetros.
Os conjuntos de dados são parâmetros inflexíveis e uma entidade reutilizável/referenciável. As atividades podem referenciar conjuntos de dados e podem consumir as propriedades definidas na definição do conjunto de dados
Os serviços ligados também são um parâmetro inflexível que contém as informações de ligação a um arquivo de dados ou a um ambiente de computação. Também é uma entidade reutilizável/referenciável.
Fluxo de controlo
O fluxo de controlo é uma orquestração das atividades dos pipelines que incluem o encadeamento de atividades numa sequência, a ramificação, a definição de parâmetros ao nível do pipeline e a transmissão de argumentos quando é invocado o pipeline a pedido ou a partir de um acionador. Também inclui a transmissão de estado personalizado e os contentores de ciclo, ou seja, iteradores For-each.
Variáveis
As variáveis podem ser usadas dentro de pipelines para armazenar valores temporários e também podem ser usadas em conjunto com parâmetros para permitir a passagem de valores entre pipelines, fluxos de dados e outras atividades.
Conteúdos relacionados
Aqui estão os documentos importantes da próxima etapa a serem explorados:
- Dataset and linked services (Conjuntos de dados e serviços ligados)
- Pipelines e atividades
- Integration runtime (Runtime de integração)
- Mapeamento de Fluxos de Dados
- IU do Data Factory no portal do Azure
- Ferramenta de Copiar Dados no portal do Azure
- PowerShell
- .NET
- Python
- REST
- Modelo Azure Resource Manager