Plotar histogramas no Python
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo descreve como plotar os dados usando o pacote pandas'.hist() do Python. Um Banco de Dados SQL é a origem usada para visualizar os intervalos de dados de histograma que têm valores consecutivos e não sobrepostos.
Pré-requisitos
SQL Server Management Studio para restaurar o banco de dados de exemplo na Instância Gerenciada de SQL do Azure.
Azure Data Studio. Para instalá-lo, confira Azure Data Studio.
Restaure o banco de dados DW de exemplo para obter os dados de exemplo usados neste artigo.
Confirmar o banco de dados restaurado
Confirme se o banco de dados restaurado existe consultando a tabela Person.CountryRegion:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Instalar pacotes do Python
Baixe e instale o Azure Data Studio.
Instale os seguintes pacotes do Python:
pyodbcpandassqlalchemymatplotlib
Para instalar esses pacotes:
- No notebook do Azure Data Studio, selecione Gerenciar Pacotes.
- No painel Gerenciar Pacotes, selecione a guia Adicionar Novo.
- Para cada pacote a seguir, insira o nome do pacote, selecione Pesquisar e Instalar.
Plotar um histograma
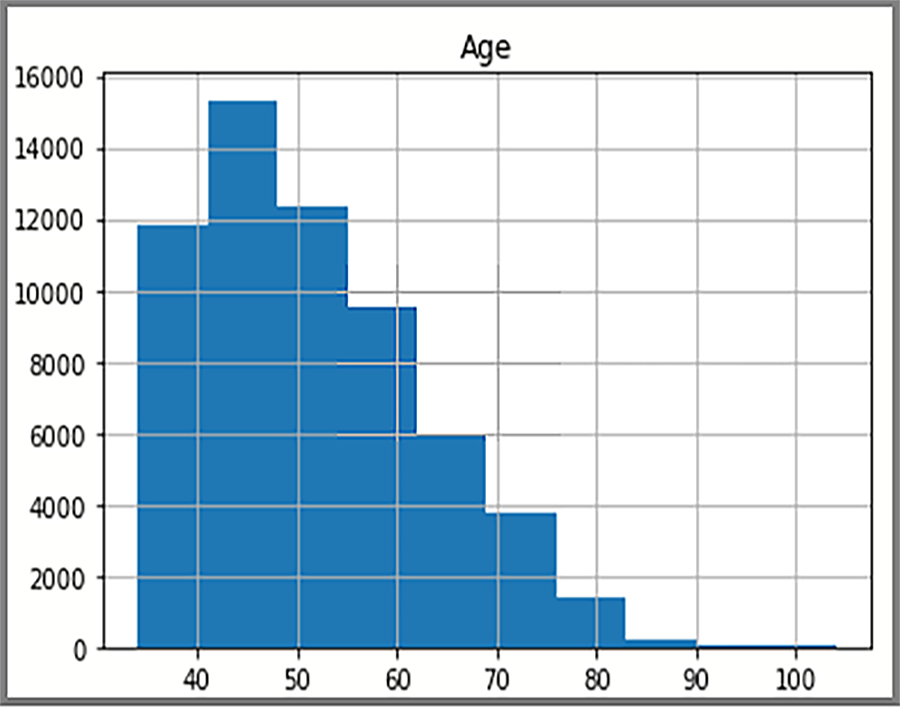
Os dados distribuídos exibidos no histograma baseiam-se em uma consulta SQL do AdventureWorksDW2022. O histograma visualiza os dados e a frequência dos valores de dados.
Edite as variáveis de cadeia de conexão 'server', 'database', 'username' e 'password' para se conectar ao Banco de Dados SQL.
Para criar um notebook:
- No Azure Data Studio, selecione Arquivo e escolha Novo Notebook.
- No notebook, selecione o kernel Python3 e escolha +code.
- Cole o código no notebook e selecione Executar Tudo.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
A exibição mostra a distribuição etária de clientes na tabela FactInternetSales.