Índices columnstore – diretrizes de carregamento de dados
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Opções e recomendações para carregar dados em um índice columnstore usando o carregamento em massa de SQL padrão e métodos de inserção de fluxo. Carregar dados em um índice columnstore é uma parte essencial de qualquer processo de data warehousing porque ele move os dados para o índice em preparação para análise.
Novato em índices columnstore? Consulte Índices columnstore – visão geral e Índices columnstore – arquitetura.
O que é carregamento em massa?
Carregamento em massa refere-se ao modo em que um grande número de linhas é adicionado a um armazenamento de dados. É o modo mais eficaz de mover dados para um índice columnstore, porque funciona em lotes de linhas. O carregamento em massa preenche rowgroups até a capacidade máxima e compacta-os diretamente no columnstore. Somente as linhas ao final de uma carga que não atende ao mínimo de 102.400 linhas por rowgroup vão para o deltastore.
Para executar uma carga em massa, você pode usar o Utilitário bcp, o Integration Services ou selecionar linhas de uma tabela de preparo.
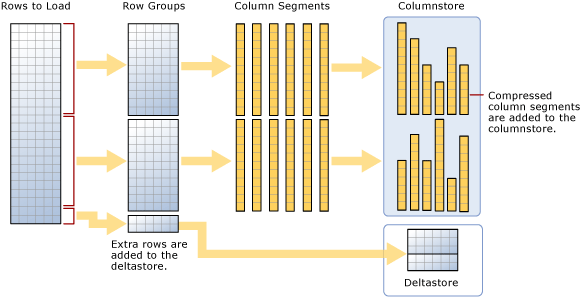
Como sugere o diagrama, um carregamento em massa:
- Não pré-classifica os dados. Os dados são inseridos em rowgroups na ordem em que são recebidos.
- Se o tamanho do lote for >= 102400, as linhas serão carregadas diretamente em rowgroups compactados. É recomendável escolher um tamanho de lote de >=102400 para uma importação em massa eficiente porque você pode evitar mover linhas de dados para um rowgroup delta antes que as linhas sejam finalmente movidas para rowgroups compactados por uma conversa em segundo plano, o TM (mover de tupla).
- Se o tamanho do lote < 102.400 ou se as linhas restantes forem < 102.400, as linhas serão carregadas em rowgroups delta.
Observação
Em uma tabela rowstore com os dados de um índice columnstore não clusterizado, o SQL Server sempre insere dados na tabela base. Os dados nunca são inseridos diretamente no índice columnstore.
O carregamento em tem estas otimizações de desempenho internas:
Cargas paralelas: é possível ter várias cargas em massa simultâneas (bcp ou inserção em massa), cada uma carregando um arquivo de dados separado. Ao contrário dos carregamentos em massa rowstore no SQL Server, não é necessário especificar
TABLOCKporque cada conversa de carregamento em massa carrega dados exclusivamente em um rowgroup separado (rowgroups compactados ou delta) com um bloqueio exclusivo.Registro em log reduzido: os dados carregados diretamente em grupos de linhas compactados geram uma redução significativa no tamanho do log. Por exemplo, se os dados tiverem sido compactados 10 vezes, o log de transações correspondente será aproximadamente 10 vezes menor sem a necessidade de um modelo de recuperação TABLOCK ou bulk-logged/simples. Todos os dados que vão para um rowgroup delta são totalmente registrados. Isso inclui qualquer tamanho de lote com menos de 102.400 linhas. A melhor prática é usar o batchsize >= 102400. Como não exige TABLOCK, você pode carregar os dados em paralelo.
Log mínimo: você poderá obter mais redução no registro em log se seguir os pré-requisitos para o registro em log mínimo. Porém, ao contrário do carregamento de dados em um rowstore, o TABLOCK gera um bloqueio X na tabela em vez de um bloqueio BU (atualização em massa) e, assim, o carregamento de dados paralelo não pode ser feito. Para obter mais informações sobre o bloqueio, confira Bloqueio e controle de versão de linha.
Otimização de bloqueio: o bloqueio X em um grupo de linhas é adquirido automaticamente ao carregar dados em um grupo de linhas compactado. Porém, durante o carregamento em massa em um rowgroup delta, um bloqueio X é adquirido em um rowgroup, mas o SQL Server ainda bloqueia PAGE/EXTENT porque o bloqueio do rowgroup X não faz parte da hierarquia de bloqueios.
Se você tiver um índice de árvore B não clusterizado em um índice columnstore, não haverá otimização de log nem de bloqueio para o índice em si, mas as otimizações no índice columnstore clusterizado, conforme descrito anteriormente, ainda serão aplicáveis.
Modificação de dados (inserir, excluir, atualizar) não é uma operação do modo em lote porque não é paralela.
Planejar tamanhos de carga em massa para minimizar os rowgroups delta
Os índices columnstore têm um desempenho melhor quando a maioria das linhas é compactada no columnstore e não permanece nos rowgroups delta. É melhor dimensionar suas cargas de tamanho para que as linhas vão diretamente para o columnstore e ignorem o deltastore o máximo possível.
Esses cenários descrevem quando as linhas carregadas vão diretamente para o columnstore ou quando elas vão para o deltastore. No exemplo, cada rowgroup pode ter de 102.400 a 1.048.576 linhas por rowgroup. Na prática, o tamanho máximo de um rowgroup poder ser inferior a 1.048.576 linhas quando há pressão de memória.
| Linhas para carregamento em massa | Linhas adicionadas ao rowgroup compactado | Linhas adicionadas ao rowgroup delta |
|---|---|---|
| 102.000 | 0 | 102.000 |
| 145.000 | 145.000 Tamanho do rowgroup: 145.000 |
0 |
| 1,048,577 | 1\.048.576 Tamanho do rowgroup: 1.048.576. |
1 |
| 2,252,152 | 2,252,152 Tamanhos do rowgroup: 1.048.576, 1.048.576, 155.000. |
0 |
O exemplo a seguir mostra os resultados do carregamento de 1.048.577 linhas em uma tabela. Os resultados mostram um rowgroup COMPRESSED no columnstore (como segmentos de coluna compactados) e 1 linha no deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Usar uma tabela de preparo para melhorar o desempenho
Se estiver carregando os dados apenas para prepará-los antes de executar mais transformações, carregar a tabela na tabela de heap é muito mais rápido que carregar os dados em uma tabela columnstore clusterizada. Além disso, carregar dados em uma [tabela temporária] [Temporária] também será muito mais rápido do que carregar uma tabela em um armazenamento permanente.
Um padrão comum do carregamento de dados é carregar os dados em uma tabela de preparo, fazer alguma transformação e carregá-la na tabela de destino usando o comando a seguir:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Esse comando carrega os dados no índice columnstore de forma semelhante ao bcp ou à inserção em massa, mas em um único lote. Se o número de linhas na tabela de preparo < 102.400, as linhas serão carregadas em um rowgroup delta, caso contrário, as linhas serão carregadas diretamente no rowgroup compactado. Uma importante limitação era que essa operação INSERT era single-threaded. Para carregar dados em paralelo, era possível criar várias tabelas de preparo ou emitir INSERT/SELECT com intervalos não sobrepostos de linhas da tabela de preparo. Essa limitação não existe no SQL Server 2016 (13.x). O comando a seguir carrega os dados da tabela de preparo em paralelo, mas você precisa especificar TABLOCK. Você pode achar isso contraditório em relação ao que foi dito anteriormente com carregamento em massa, mas a principal diferença é que o carregamento de dados paralelos da tabela de preparo é executado na mesma transação.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Estas são as otimizações disponíveis ao fazer um carregamento em um índice columnstore clusterizado da tabela de preparo:
- Otimização de log: log reduzido quando os dados são carregados em um rowgroup compactado.
- Otimização de bloqueio: ao carregar dados em um rowgroup compactado, o bloqueio X no rowgroup é adquirido. Porém, com o rowgroup delta, um bloqueio X é adquirido em rowgroup, mas o SQL Server ainda bloqueia os bloqueios PAGE/EXTENT porque o bloqueio do rowgroup X não faz parte da hierarquia de bloqueio.
Se você tiver um ou mais índices não clusterizados, não haverá otimização de log nem de bloqueio para o índice em si, mas as otimizações no índice columnstore clusterizado, conforme descrito anteriormente, permanecerão.
O que é a inserção de fluxo?
Inserção de fluxo refere-se à forma como linhas individuais são movidas para o índice columnstore. As inserções de fluxo usam a instrução INSERT INTO. Com a inserção de fluxo, todas as linhas vão para o deltastore. Isso é útil para um número pequeno de linhas, mas não é prático para grandes cargas.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Observação
Os threads simultâneos que usam INSERT INTO para inserir valores em um índice columnstore clusterizado podem inserir linhas no mesmo rowgroup deltastore.
Depois que o rowgroup contém 1.048.576 linhas, o rowgroup delta é marcado como fechado, mas ainda fica disponível para consultas e operações de atualização/exclusão. Porém, as linhas recém-inseridas vão para um rowgroup deltastore existente ou recém-criado. Há um thread em segundo plano, TM (mover de tupla) , que compacta os rowgroups delta fechados a cada 5 minutos mais ou menos. Você pode invocar explicitamente o comando a seguir para compactar o rowgroup delta fechado.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Se quiser forçar um rowgroup delta a ser fechado e compactado, você poderá executar o comando a seguir. Convém executar esse comando se você acabou de carregar as linhas e não espera linhas novas. Ao fechar e compactar explicitamente o rowgroup delta, você poderá salvar mais armazenamento e melhorar o desempenho da consulta analítica. Uma prática recomendada é invocar esse comando se você não espera que novas linhas sejam inseridas.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Como funciona o carregamento em uma tabela particionada
Para dados particionados, primeiro o SQL Server atribui cada linha a uma partição e, depois, executa operações columnstore nos dados na partição. Cada partição tem seus próprios rowgroups e pelo menos um rowgroup delta.