Indexar dados JSON
Aplica-se a: ![]() SQL Server 2016 (13.x) e posteriores
SQL Server 2016 (13.x) e posteriores ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Você pode otimizar suas consultas em documentos JSON usando índices padrão. O SQL Server não tem índices JSON personalizados.
- No momento, no SQL Server, json não é um tipo de dados integrado.
- O tipo de dados JSON está atualmente em versão prévia para o Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure (configurada com a política de atualização Sempre atualizada).
Os índices funcionam da mesma maneira em dados JSON em varchar/nvarchar ou no tipo de dados json nativo.
Índices de bancos de dados melhoram o desempenho das operações de filtragem e classificação. Sem índices, o SQL Server precisa executar uma verificação de tabela completa sempre que você consultar dados.
Indexar propriedades com colunas computadas
Ao armazenar dados JSON no SQL Server, normalmente é útil filtrar ou classificar resultados de consulta pelas propriedades dos documentos JSON.
Exemplo
Neste exemplo, suponha que a tabela AdventureWorks.SalesOrderHeader tenha uma coluna Info que contém diversas informações em formato JSON sobre ordens de venda. Por exemplo, ela contém dados não estruturados sobre clientes, vendedores, endereços de entrega e de cobrança etc. Você poderá usar os valores da coluna Info para filtrar os pedidos de venda de um cliente.
Por padrão, a coluna Info usada não existe. Ela pode ser criada no banco de dados AdventureWorks com o código a seguir. Os exemplos a seguir não se aplicam à série AdventureWorksLT de bancos de dados de exemplo.
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Consulta para otimizar
Veja um exemplo do tipo de consulta que você deseja otimizar usando um índice.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
Índice de exemplo
Se você quiser acelerar seus filtros ou cláusulas ORDER BY em uma propriedade de um documento JSON, use os mesmos índices já usados em outras colunas. No entanto, não é possível fazer referências diretamente a propriedades em documentos JSON.
- Primeiro, crie uma "coluna virtual" que retorne os valores que você deseja usar para filtragem.
- Em seguida, crie um índice nessa coluna virtual.
O exemplo a seguir cria uma coluna computada que pode ser usada para indexação. Em seguida, ele cria um índice na nova coluna computada. Esse exemplo cria uma coluna que expõe o nome do cliente, que é armazenado no caminho $.Customer.Name nos dados JSON.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
Esta instrução retornará o seguinte aviso:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
A função JSON_VALUE pode retornar valores de texto de até 8000 bytes (por exemplo, como o tipo nvarchar(4000)). No entanto, os valores maiores que 1.700 bytes não podem ser indexados. Se você tentar inserir o valor na coluna computada indexada que tenha mais de 1700 bytes, a operação de DML (linguagem de manipulação de dados) falhará.
Para obter melhor desempenho, tente converter o valor exposto usando uma coluna computada no menor tipo de dados aplicável. Use os tipos int e datetime2 em vez dos tipos de cadeia de caracteres.
Para obter mais informações sobre a coluna computada
Uma coluna computada não é persistente. Uma coluna de computador é computada somente quando o índice precisa ser recriado. Ela não ocupa espaço adicional na tabela.
É importante criar a coluna computada com a mesma expressão que você planeja usar em suas consultas – neste exemplo, a expressão é JSON_VALUE(Info, '$.Customer.Name').
Não é preciso reescrever as consultas. Se você usar expressões com a função JSON_VALUE, como mostrado na consulta de exemplo anterior, o SQL Server observará que existe um equivalente da coluna computada com a mesma expressão e aplica um índice, se possível.
Plano de execução para este exemplo
Este é o plano de execução para a consulta no exemplo.
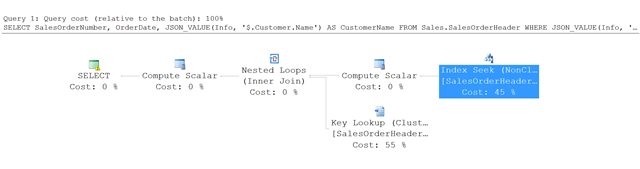
Em vez de uma verificação de tabela completa, o SQL Server usa uma busca de índice no índice não clusterizado e localiza as linhas que atendem às condições especificadas. Em seguida, ele usa uma pesquisa de chave na tabela SalesOrderHeader para buscar outras colunas referenciadas na consulta – neste exemplo, SalesOrderNumber e OrderDate.
Otimizar ainda mais o índice com colunas incluídas
Se adicionar as colunas necessárias ao índice, você poderá evitar essa pesquisa adicional na tabela. É possível adicionar essas colunas como colunas incluídas padrão, conforme mostrado no exemplo a seguir, que expande o exemplo CREATE INDEX anterior.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
Nesse caso, o SQL Server não precisa ler dados adicionais da tabela SalesOrderHeader, pois tudo de que precisa está incluído no índice JSON não clusterizado. Este tipo de índice é uma boa maneira de combinar dados JSON e de colunas em consultas e criar índices otimizados para sua carga de trabalho.
Os índices JSON são índices com reconhecimento de ordenação
Um recurso importante dos índices sobre dados JSON é que os índices têm reconhecimento de ordenação. O resultado da função JSON_VALUE usada ao criar uma coluna computada é um valor de texto que herda sua ordenação da expressão de entrada. Portanto, os valores no índice são ordenados usando as regras de ordenação definidas nas colunas de origem.
Para demonstrar que os índices têm reconhecimento de ordenação, o exemplo a seguir cria uma tabela de ordenação simples com uma chave primária e conteúdo JSON.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
O comando anterior especifica a ordenação de sérvio (cirílico) para a coluna json. O exemplo a seguir preenche a tabela e cria um índice na propriedade de nome.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
Os comandos anteriores criam um índice padrão na coluna computada vName, que representa o valor da propriedade JSON $.name. Na página de código de sérvio (cirílico), a ordem das letras é А, Б, В, Г, Д, Ђ, Е etc. A ordem dos itens no índice está em conformidade com as regras de sérvio (cirílico), pois o resultado da função JSON_VALUE herda sua ordenação da coluna de origem. O exemplo a seguir consulta esse agrupamento e classifica os resultados por nome.
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
Se você examinar o plano de execução real, verá que ele usa valores classificados do índice não clusterizado.

Embora a consulta tenha uma cláusula ORDER BY, o plano de execução não usa um operador Sort. O índice JSON já é ordenado de acordo com a regras do Sérvio Cirílico. Portanto, o SQL Server pode usar o índice não clusterizado nos quais os resultados já estão classificados.
No entanto, se alterar a ordenação da expressão ORDER BY (por exemplo, se adicionar COLLATE French_100_CI_AS_SC após a função JSON_VALUE), você obterá um plano de execução de consulta diferente.

Como a ordem dos valores no índice não segue as regras de ordenação do Francês, o SQL Server não pode usar o índice para ordenar os resultados. Portanto, ele adiciona um operador Sor que classifica os resultados usando as regras de ordenação do Francês.
Vídeos da Microsoft
Observação
Alguns dos links de vídeo nesta seção podem não funcionar no momento. A Microsoft está migrando conteúdo armazenado anteriormente no Canal 9 para uma nova plataforma. Atualizaremos os links à medida que os vídeos forem migrados para a nova plataforma.
Para obter uma introdução visual ao suporte interno para JSON no SQL Server e no Banco de Dados SQL do Azure, consulte os seguintes vídeos: