A máquina virtual Linux do Azure falha ao inicializar após a aplicação de alterações no kernel
Aplica-se a: ✔️ VMs do Linux
Observação
O CentOS mencionado neste artigo é uma distribuição Linux e chegará ao fim da vida útil (EOL). Considere seu uso e planeje adequadamente. Para obter mais informações, consulte Diretrizes de fim da vida útil do CentOS.
Este artigo fornece soluções para um problema em que uma VM (máquina virtual) Linux não pode inicializar após aplicar alterações de kernel.
Pré-requisitos
Verifique se o console serial está habilitado e funcional na VM do Linux.
Como identificar o problema de inicialização relacionado ao kernel
Para identificar um problema de inicialização relacionado ao kernel, verifique a cadeia de caracteres de pânico do kernel específica. Para fazer isso, use a CLI do Azure ou o portal do Azure para exibir a saída do log do console serial da VM no painel de diagnóstico de inicialização ou no painel do console serial.
Um kernel panic se parece com a seguinte saída e aparecerá no final do log do console serial:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
Resolução de problemas online
Dica
Se você tiver um backup recente da VM, restaure a VM do backup para corrigir o problema de inicialização.
O console serial é o método mais rápido para resolver o problema de inicialização. Ele permite que você corrija o problema diretamente sem precisar apresentar o disco do sistema a uma VM de recuperação. Certifique-se de atender aos pré-requisitos necessários para sua distribuição. Para obter mais informações, consulte Console serial da máquina virtual para Linux.
Identifique o problema de inicialização específico relacionado ao kernel.
Use o console serial do Azure para interromper sua VM no menu GRUB e selecione qualquer kernel anterior para inicializá-la. Para obter mais informações, consulte Inicializar o sistema em uma versão mais antiga do kernel.
Vá para a seção correspondente para resolver o problema de inicialização específico relacionado ao kernel:
Depois que o problema de inicialização relacionado ao kernel for resolvido, reinicie a VM para que ela possa inicializar sobre a versão mais recente do kernel.
Solução de problemas offline
Dica
Se você tiver um backup recente da VM, restaure a VM do backup para corrigir o problema de inicialização.
Se o console serial do Azure não funcionar na VM específica ou não for uma opção em sua assinatura, solucione o problema de inicialização usando uma VM de resgate/reparo. Para fazer isso, siga estas etapas:
Use vm repair comandos para criar uma VM de reparo que tenha uma cópia do disco do sistema operacional da VM afetada anexada. Monte a cópia dos sistemas de arquivos do sistema operacional na VM de reparo usando chroot.
Observação
Como alternativa, você pode criar uma VM de resgate manualmente usando o portal do Azure. Para obter mais informações, confira Solucionar problemas de uma VM do Linux anexando o disco do sistema operacional a uma VM de recuperação usando o portal do Azure.
Identifique o problema de inicialização específico relacionado ao kernel.
Vá para a seção correspondente para resolver o problema de inicialização específico relacionado ao kernel:
Depois que o problema de inicialização relacionado ao kernel for resolvido, execute as seguintes ações:
- Saia do chroot.
- Desmonte a cópia dos sistemas de arquivos da VM de resgate/reparo.
- Execute o
az vm repair restorecomando para trocar o disco do sistema operacional reparado pelo disco do sistema operacional original da VM. Para obter mais informações, consulte Etapa 5 em Reparar uma VM do Linux usando os comandos de reparo da Máquina Virtual do Azure. - Valide se a VM é capaz de inicializar dando uma olhada no console serial do Azure ou tentando se conectar à VM.
Se houver conteúdo importante relacionado ao kernel, toda a
/bootpartição ou outros conteúdos importantes estiverem ausentes e não puderem ser recuperados, recomendamos restaurar a VM de um backup. Para obter mais informações, consulte Como restaurar dados de VM do Azure no portal do Azure.
Sistema de inicialização na versão mais antiga do kernel
Usar o console serial do Azure
Reinicie a VM usando o console serial do Azure.
- Selecione o botão de desligamento na parte superior da janela do console serial.
- Selecione a opção Reiniciar VM (Difícil).
Assim que a conexão do console serial for retomada, você verá um contador de contagem regressiva no canto superior esquerdo da janela do console serial. Pressione a tecla ESCAPE para interromper sua VM no menu GRUB.
Pressione a tecla de seta para baixo para selecionar qualquer versão anterior do kernel.

Altere a variável no arquivo /etc/default/grub conforme instruído
GRUB_DEFAULTem Alterar a versão padrão do kernel manualmente. Esta é uma mudança persistente.

Observação
Se houver apenas uma versão do kernel listada no menu GRUB, siga a abordagem de solução de problemas offline para solucionar esse problema de uma VM de reparo.
Usar VM de reparo (scripts ALAR)
Execute o seguinte comando bash no Azure Cloud Shell para criar uma VM de reparo. Para obter mais informações, consulte Usar o ALAR (Reparo Automático do Linux no Azure) para corrigir uma opção de kernel da VM do Linux.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyExecute o seguinte comando para substituir o kernel quebrado pela versão instalada anteriormente:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
Observação
Se houver apenas uma versão do kernel instalada no sistema, siga a abordagem de solução de problemas offline para solucionar esse problema de uma VM de reparo.
Alterar a versão padrão do kernel manualmente
Para modificar a versão padrão do kernel de uma VM de reparo (dentro do chroot) ou em uma VM em execução, siga estas etapas:
Observação
Se uma reversão de downgrade do kernel for feita, selecione a versão mais recente do kernel em vez da mais antiga.
RHEL 7, Oracle Linux 7 e CentOS 7
Valide a lista de kernels disponíveis no arquivo de configuração do GRUB executando um dos seguintes comandos:
VMs Gen1:
cat /boot/grub2/grub.cfg | grep menuentryVMs Gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Defina o novo kernel padrão e especifique o título do kernel correspondente executando o seguinte comando:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'Observação
Substitua
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64pelo título da entrada de menu correspondente.Valide se o novo kernel padrão é o desejado executando o seguinte comando:
grub2-editenv listCertifique-se de que o
GRUB_DEFAULTvalor da variável no arquivo /etc/default/grub esteja definido comosaved. Para modificá-lo, certifique-se de gerar novamente o arquivo de configuração do GRUB para aplicar as alterações.
RHEL 8/9 e CentOS 8
Liste os kernels disponíveis executando o seguinte comando:
ls -l /boot/vmlinuz-*Defina o novo kernel padrão executando o seguinte comando:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64Observação
Substitua
4.18.0-372.19.1.el8_6.x86_64pela versão do kernel correspondente.Valide se o novo kernel padrão é o desejado executando o seguinte comando:
grubby --default-kernel
SLES 12/15, Ubuntu 18.04/20.04
Liste os kernels disponíveis no arquivo de configuração do GRUB executando o seguinte comando:
VMs Gen1:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
VMs Gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Defina o novo kernel padrão modificando o
GRUB_DEFAULTvalor da variável no arquivo /etc/default/grub . Para a versão mais recente do kernel instalada no sistema, o valor padrão é 0. O próximo kernel disponível é definido como "1>2".vi /etc/default/grub GRUB_DEFAULT="1>2"Observação
Para obter mais informações sobre como configurar a
GRUB_DEFAULTvariável, consulte SUSE Boot Loader GRUB2 e Ubuntu Grub2/Setup. Como referência: o valor de entrada de menu de nível superior é 0, o valor do submenu de primeiro nível superior é 1 e cada valor de entrada de menu aninhado começa com 0. Por exemplo, "1>2" é a terceira entrada de menu do primeiro submenu.Gere novamente o arquivo de configuração do GRUB para aplicar as alterações. Siga as instruções em Reinstalar o GRUB e regenerar o arquivo de configuração do GRUB para a distribuição do Linux e a geração de VM correspondentes.
Pânico do kernel - não sincronizando: VFS: Não é possível montar o fs raiz no bloco desconhecido (0,0)
Esse erro ocorre devido a uma atualização recente do sistema (kernel). É mais comumente visto em distribuições baseadas em RHEL. Você pode identificar esse problema no console serial do Azure. Você verá qualquer uma das seguintes mensagens de erro:
"Pânico do kernel - não sincronizando: VFS: Não é possível montar o fs raiz no bloco desconhecido (0,0)"
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)"Erro: Arquivo '/initramfs-*.img' não encontrado"
Erro: Arquivo '/initramfs-3.10.0-1160.36.2.el7.x86_64.img' não encontrado.
Esse tipo de erro indica que o arquivo initramfs não foi gerado, o arquivo de configuração do GRUB tem a entrada initrd ausente após um processo de aplicação de patch ou uma configuração incorreta manual do GRUB.
Antes de reinicializar um servidor, recomendamos validar a configuração e /boot o conteúdo do GRUB se houver uma atualização do kernel executando um dos comandos a seguir. É importante garantir que a atualização seja concluída e que não haja arquivos initramfs ausentes.
Baseado em BIOS - Sistemas Gen1
# ls -l /boot # cat /boot/grub2/grub.cfgBaseado em UEFI - Sistemas Gen2
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
Regenerar initramfs ausentes usando scripts ALAR de VM de Reparo do Azure
Crie uma VM de reparo executando a seguinte linha de comando do Bash com o Azure Cloud Shell. Para obter mais informações, consulte Usar o ALAR (Reparo Automático do Linux no Azure) para corrigir uma VM do Linux – opção initrd.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyGere novamente a imagem initrd/initramfs e gere novamente o arquivo de configuração do GRUB se ele tiver a entrada initrd ausente. Para fazer isso, execute o seguinte comando:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAMEDepois que o comando de restauração for executado, reinicie a VM original e valide se ela pode ser inicializada.
Regenerar initramfs ausentes manualmente
Importante
- Se você conseguir inicializar a VM usando uma versão anterior do kernel ou dentro do chroot da VM de reparo/resgate, gere novamente o initramfs ausente manualmente.
- Para regenerar o initramfs ausente manualmente a partir de uma VM de reparo, certifique-se de que a etapa 1 na solução de problemas offline já tenha sido seguida e que esses comandos sejam executados dentro do chroot.
Identifique a versão específica do kernel que tem problemas com a inicialização. Você pode extrair as informações de versão do erro de pânico do kernel correspondente.
Consulte a captura de tela a seguir como exemplo. O erro de pânico do kernel mostra que a versão do kernel é "3.10.0-1160.59.1.el7.x86_64":
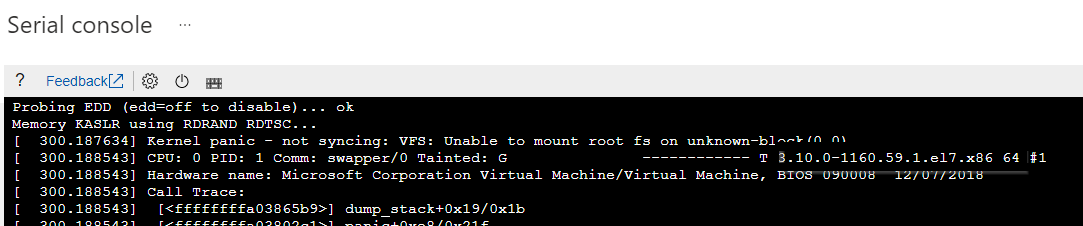
Gere novamente o arquivo initramfs ausente executando um dos seguintes comandos:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64Importante
Substitua
3.10.0-1160.59.1.el7.x86_64pela versão do kernel correspondente.SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azureImportante
Substitua
5.3.18-150300.38.53-azurepela versão do kernel correspondente.Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azureImportante
Substitua
5.4.0-1077-azurepela versão do kernel correspondente.
Gere novamente o arquivo de configuração do GRUB. Siga as instruções em Reinstalar o GRUB e regenerar o arquivo de configuração do GRUB para a distribuição Linux e a geração de VM correspondentes
Se as etapas acima forem executadas em uma VM de reparo, siga a etapa 3 em Solução de problemas offline. Se as etapas acima forem executadas no console serial do Azure, siga o método de solução de problemas online.
Reinicialize sua VM sobre a versão mais recente do kernel.
Kernel panic - não sincronizando: tentativa de encerrar a inicialização
Identifique esse problema no console serial do Azure. Você verá uma saída como a seguinte:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
Esse tipo de kernel panic ocorre devido às seguintes causas possíveis:
Arquivos e diretórios importantes ausentes.
Faltam bibliotecas e pacotes importantes do núcleo do sistema
Consulte as seções a seguir para obter detalhes e soluções de causa. Certifique-se de que os comandos sejam executados a partir de uma VM de reparo/resgate dentro de um ambiente chroot, conforme instruído em Solução de problemas offline.
Arquivos e diretórios importantes ausentes
Arquivos e diretórios importantes do Linux estão faltando devido a um erro humano. Por exemplo, os arquivos são excluídos acidentalmente ou o sistema de arquivos é corrompido.
Valide o conteúdo do disco do sistema operacional depois de anexar a cópia do disco do sistema operacional a uma VM de reparo e montar os sistemas de arquivos correspondentes usando chroot. Você pode comparar as saídas com as de uma VM em funcionamento que executa a mesma versão do sistema operacional.
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | moreRestaure os arquivos ausentes de um backup. Para obter mais informações, consulte Recuperar arquivos do backup da máquina virtual do Azure. Dependendo do número de arquivos ausentes, talvez seja melhor fazer uma restauração completa da VM. Para obter mais informações, consulte Como restaurar dados de VM do Azure no portal do Azure.
Faltam bibliotecas e pacotes importantes do núcleo do sistema
Bibliotecas, arquivos ou pacotes importantes do núcleo do sistema são excluídos do sistema ou corrompidos. Para resolver esse problema, reinstale as bibliotecas, arquivos ou pacotes afetados. Essa solução funciona em distribuições baseadas em RPM, como VMs Red Hat/CentOS/SUSE. Para outras distribuições do Linux, recomendamos restaurar a VM do backup.
Para realizar a reinstalação, siga estas etapas:
Crie uma VM de resgate usando uma imagem bruta com a mesma versão e geração do sistema operacional que a VM afetada.
Acesse o ambiente chroot na VM de resgate para solucionar o problema.
sudo chroot /rescueA saída do comando indicará qual biblioteca está ausente ou corrompida, conforme mostrado abaixo:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directoryVerifique todos os pacotes do sistema e seu status correspondente na VM de resgate. Compare a saída com uma VM íntegra que executa a mesma versão do sistema operacional.
sudo rpm --verify --all --root=/rescueAqui está um exemplo da saída do comando:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.confA linha
missing /lib64/libc-2.28.sode saída está relacionada ao erro anterior na etapa 2 e indica que o pacote libc-2.28.so está ausente. No entanto, o pacote libc-2.28.so pode ser modificado. Nesse caso, a saída será exibida.M.....em vez demissing. O pacote libc-2.28.so é referenciado como um exemplo nas etapas a seguir.Na VM de recuperação, verifique qual pacote contém a biblioteca /lib64/libc-2.28.so.
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64Observação
A saída mostrará o pacote que precisa ser reinstalado, incluindo o nome e a versão do pacote. A versão do pacote pode ser diferente daquela instalada na VM afetada.
Na VM afetada, verifique qual versão do pacote glibc está instalada.
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64Baixe o pacote glibc-2.28-211.0.1.el8.x86_64. Você pode baixá-lo do site oficial do fornecedor do sistema operacional ou da VM de resgate usando uma ferramenta de gerenciamento de pacotes como
yumdownloaderouzypper install --download-only <packagename>dependendo do sistema operacional que você está executando.Aqui está um exemplo de uso da
yumdownloaderferramenta:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00Reinstale o pacote afetado na VM de recuperação.
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]Acesse o ambiente chroot na VM de resgate para validar a reinstalação.
sudo chroot /rescueDesligue a VM de resgate e troque o disco do sistema operacional pela VM afetada.
Permissões de arquivo incorretas
Permissões de arquivo incorretas em todo o sistema são modificadas devido a um erro humano (por exemplo, alguém executa chmod 777 em / um ou em outros sistemas de arquivos importantes do sistema operacional). Para resolver esse problema, restaure as permissões do arquivo. Essa solução funciona em distribuições baseadas em RPM, como VMs Red Hat/CentOS/SUSE. Para outras distribuições do Linux, recomendamos restaurar a VM do backup.
Para restaurar as permissões de arquivo, execute o seguinte comando depois de anexar a cópia do disco do sistema operacional a uma VM de reparo e montar os sistemas de arquivos correspondentes usando chroot:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
Observação
Não execute esse comando em sistemas de produção em execução.
Se o problema persistir após a recuperação manual das permissões de arquivo correspondentes, execute uma restauração do backup.
Partições ausentes
Nos casos em /usrque os sistemas , /opt, /var, /home, /tmpe / de arquivos estão espalhados por partições diferentes, os dados podem ficar inacessíveis devido a problemas no nível das partições, que podem ser causados por erros durante as operações de redimensionamento de partição ou outros.
Nesse cenário, se você documentar o layout da tabela de partição original, com os setores inicial e final exatos para cada uma das partições originais, e nenhuma modificação adicional for feita no sistema, como a criação de novos sistemas de arquivos, recrie as partições usando o mesmo layout original com ferramentas como fdisk (para tabelas de partição MBR) ou gdisk (para tabelas de partição GPT) para obter acesso ao sistema de arquivos ausente.
Se essa abordagem não funcionar, execute uma restauração do backup.
Problemas com o SELinux
Permissões erradas do SELinux podem impedir que o sistema acesse arquivos importantes. Para resolver esse problema, siga estas etapas:
Para verificar se o sistema tem problemas devido a permissões erradas do SELinux, inicie o sistema com o SELinux desabilitado adicionando a opção de kernel selinux=0 à linha GRUB linux16.
Se o sistema for capaz de inicializar, execute o seguinte comando para acionar um novo rótulo do SELinux no momento da inicialização e reinicializar o sistema:
touch /.autorelabelSe a VM ainda não puder inicializar, faça uma restauração completa da VM do backup. Para obter mais informações, consulte Como restaurar dados de VM do Azure no portal do Azure.
Outros problemas de inicialização relacionados ao kernel
Este artigo aborda os pânicos de kernel do Linux mais comuns identificados no Azure. Para obter mais informações sobre cenários comuns de pânico do kernel, consulte Pânico do kernel em VMs Linux do Azure – Eventos comuns de pânico do kernel.
Há alguns outros possíveis pânicos de kernel importantes que podem causar cenários de não inicialização ou SSH (shell seguro).
Certifique-se de executar todos os comandos de uma VM de reparo dentro de um ambiente chroot, conforme instruído na solução de problemas offline. Se o sistema já tiver sido inicializado sobre uma versão anterior do kernel, esses comandos também poderão ser executados a partir da VM original usando privilégios de root ou sudo, conforme instruído na solução de problemas online.
Atualização recente do kernel
Se o kernel panics começar após uma atualização recente do kernel, inicialize a VM sobre a versão anterior do kernel. Para obter mais informações, consulte Inicializar o sistema em uma versão mais antiga do kernel.
Você também pode verificar se já existe uma versão mais recente do kernel lançada pelo fornecedor da distribuição Linux e instalá-la. Para obter mais informações sobre como instalar a versão mais recente do kernel, consulte Processo de atualização do kernel.
Downgrade recente do kernel
Se o kernel panics começar após um downgrade recente do kernel, retorne ao kernel instalado mais recente. Você também pode verificar se já existe uma versão mais recente do kernel lançada pelo fornecedor da distribuição Linux e instalá-la. Para obter mais informações sobre como instalar a versão mais recente do kernel, consulte Processo de atualização do kernel.
Para inicializar o sistema sobre a versão mais recente do kernel, siga as instruções em Alterar a versão padrão do kernel manualmente, mas selecione o primeiro kernel listado no menu GRUB. Em uma modificação manual, você pode definir o GRUB_DEFAULT valor como 0 e gerar novamente o arquivo de configuração do GRUB correspondente.
Alterações no módulo do kernel
Você pode experimentar um kernel panic relacionado a um novo módulo do kernel ou a um módulo do kernel ausente. Para obter detalhes sobre o módulo de kernel específico que causa problemas (se houver), verifique o rastreamento de pânico do kernel correspondente.
Para validar os módulos do kernel carregados e os desabilitados nos arquivos /etc/modprobe.d/*.conf , execute um dos seguintes comandos:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.confImportante
Substitua
3.10.0-1160.59.1.el7.x86_64pela versão do kernel correspondente.SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.confImportante
Substitua
5.3.18-150300.38.53-azurepela versão do kernel correspondente.Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.confImportante
Substitua
5.4.0-1077-azurepela versão do kernel correspondente.
Para remover qualquer módulo específico do kernel, execute o seguinte comando e gere novamente o initramfs , se necessário.
rmmod <kernel_module_name>
Se um serviço do sistema usar o módulo de kernel específico, desative-o executando o systemctl disable <serviceName> comando or systemctl stop <serviceName> .
Alterações recentes de configuração do sistema operacional
Identifique quaisquer alterações recentes na configuração do kernel que possam causar problemas. Para resolver os problemas, ajuste essas configurações ou reverta as alterações de configuração.
Execute o seguinte comando para localizar parâmetros de kernel persistentes configurados em qualquer um dos seguintes arquivos:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
Execute o seguinte comando para analisar os parâmetros atuais do kernel e seus valores atuais:
sysctl -a
Observação
Execute este comando em um sistema em execução e não em um ambiente chroot.
Possíveis arquivos ausentes
Para obter mais informações sobre esse tipo de problema, consulte Arquivos e diretórios importantes ausentes.
Permissões erradas em arquivos
Para obter mais informações sobre esse tipo de problema, consulte Permissões de arquivo incorretas.
Partições ausentes
Para obter mais informações sobre esse tipo de problema, consulte Partições ausentes.
Bugs do kernel
Identifique esse problema no console serial do Azure. Esse tipo de problema será semelhante à seguinte saída:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
Esse tipo de kernel panic está associado a bugs do kernel ou bugs do kernel de terceiros.
Para corrigir bugs do kernel, pesquise na Base de Dados de Conhecimento do fornecedor usando a string BUG do kernel e procure problemas conhecidos na versão do kernel correspondente que seu sistema está executando. Aqui estão alguns recursos importantes do fornecedor:
-
Essa ferramenta foi criar para ajudar você a diagnosticar falhas no kernel. Quando você insere um texto, vmcore-dmesg.txt ou um arquivo incluindo uma ou mais mensagens oops do kernel, ele o orientará no diagnóstico do problema de travamento do kernel.
Base de dados de conhecimento do Red Hat
Para ter acesso aos recursos do Red Hat, vincule suas contas do Microsoft Azure e do Red Hat. Para obter mais informações, consulte Como os clientes do Microsoft Azure podem acessar o Portal do Cliente do Red Hat.
Recomendamos manter todos os seus sistemas atualizados para descartar possíveis bugs já corrigidos nas versões mais recentes do kernel. Para saber mais, confira Processo de atualização do kernel.
Se for necessária uma análise adicional do fornecedor, configure e habilite kdump para gerar um despejo do núcleo:
- Configuração de kdump em VMs baseadas no Red Hat.
- Configuração do despejo de memória do kernel em VMs Ubuntu.
- Configuração de despejo do núcleo do kernel em VMs SLES
Processo de atualização do kernel
Para instalar a versão mais recente disponível do kernel, execute um dos seguintes comandos:
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
Para reinstalar uma versão específica do kernel, execute um dos comandos a seguir. Certifique-se de que você não inicializou sobre a mesma versão do kernel que está tentando reinstalar. Para obter mais informações, consulte Inicializar o sistema em uma versão mais antiga do kernel.
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64Importante
Substitua
3.10.0-1160.59.1.el7.x86_64pela versão do kernel correspondente.SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64Importante
Substitua
kernel-azure-5.3.18-150300.38.75.1.x86_64pela versão do kernel correspondente.Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68Importante
Substitua
5.4.0.1091.68pela versão do kernel correspondente.
Para atualizar o sistema e aplicar as alterações mais recentes disponíveis, execute um dos seguintes comandos:
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
Os pânicos do kernel podem estar relacionados a qualquer um dos itens a seguir. Para obter mais informações, consulte Kernel panics em tempo de execução.
- Alterações na carga de trabalho do aplicativo.
- Desenvolvimento de aplicativos ou bugs de aplicativos.
- Problemas relacionados ao desempenho e assim por diante.
Próximas etapas
Se o erro de inicialização específico não for um problema de inicialização relacionado ao kernel, consulte Solucionar problemas de erros de inicialização de Máquinas Virtuais Linux do Azure para obter mais opções de solução de problemas.
Entre em contato conosco para obter ajuda
Se você tiver dúvidas ou precisar de ajuda, crie uma solicitação de suporte ou peça ajuda à comunidade de suporte do Azure. Você também pode enviar comentários sobre o produto para a comunidade de comentários do Azure.