Сведения об агрегировании и отображении метрик Azure Monitor
В этой статье объясняется агрегирование метрик в базе данных временных рядов, которая поддерживает метрики платформы Azure Monitor и пользовательские метрики. Эта статья также относится к стандартным метрикам Application Insights.
Эта информация в этой статье сложна и предоставляется для тех, кто хочет глубже разобраться в системе метрик. Вам не нужно понимать, как эффективно использовать метрики Azure Monitor.
Общие сведения и термины
При добавлении метрики в диаграмму обозреватель метрик автоматически предварительно выбирает агрегирование по умолчанию. Значение по умолчанию имеет смысл в основных сценариях, однако также можно использовать различные агрегаты, чтобы получить больше аналитических сведений о метрике. Для просмотра различных агрегатов на диаграмме необходимо понять, как их обрабатывает обозреватель метрик.
Для начала следует дать четкое определение нескольким терминам:
- Значение метрики — единственное значение измерения, полученное для определенного ресурса.
- База данных временных рядов — база данных, оптимизированная для хранения и извлечения точек данных, каждая из которых содержит значение и соответствующую метку времени.
- Период времени — общий промежуток времени.
- Интервал времени — период времени между получением двух значений метрики.
- Диапазон времени — период времени, отображаемый на диаграмме. Стандартное значение по умолчанию — 24 часа. Доступны только определенные диапазоны.
- Степень детализации времени или интервал времени — период времени, используемый для агрегирования значений вместе, чтобы разрешить их отображение на диаграмме. Доступны только определенные диапазоны. Текущий минимум — 1 минута. Степень детализации времени должна быть меньше, чем выбранный диапазон времени, чтобы ее можно было использовать, иначе будет отображаться только одно значение для всей диаграммы.
- Тип агрегирования — тип статистики, рассчитанный на основе нескольких значений метрики.
- Агрегирование — процесс принятия нескольких входных значений и их последующего использования для получения одного выходного значения с помощью правил, определенных типом агрегирования. Например, получение среднего значения для нескольких значений.
Краткое описание процесса
Метрики представляют собой ряд значений, хранящихся с меткой времени. В Azure большинство метрик хранятся в базе данных временных рядов Метрик Azure. При построении диаграммы значения выбранных метрик извлекаются из базы данных, а затем отдельно агрегируются на основе выбранной степени детализации времени (также известной как интервал времени). Вы выбираете размер детализации времени с помощью средства выбора времени обозревателя метрик. Если вы не сделаете явный выбор, степень детализации времени будет автоматически выбрана на основе выбранного в данный момент диапазона времени. После выбора значения метрик, отсканированных на протяжении каждого интервала степени детализации времени, агрегируются и помещаются на диаграмму — по одной точке данных на каждый интервал.
Типы агрегата
В обозревателе метрик доступны пять основных типов агрегирования. Обозреватель метрик скрывает агрегаты, которые не имеют значения и не могут использоваться для данной метрики.
- Sum — сумма всех значений, отсканированных на протяжении интервала агрегирования. Иногда этот тип также называется общим агрегированием.
- Count — количество измерений, отсканированных на протяжении интервала агрегирования. Этот тип не учитывает значение измерения, а только число записей.
- Average — среднее значение метрик, отсканированных на протяжении интервала агрегирования. Для большинства метрик это значение является суммой или количеством.
- Min — наименьшее значение, отсканированное на протяжении интервала агрегирования.
- Max — наибольшее значение, отсканированное на протяжении интервала агрегирования.
Например, предположим, что на диаграмме отображается метрика суммарного исходящего трафика для виртуальной машины с использованием агрегата SUM в течение последнего 24-часового интервала времени. Диапазон времени и степень детализации можно изменить в правом верхнем углу диаграммы, как показано на следующем снимке экрана.

Для степени детализации времени задано значение 30 минут, а для диапазона времени — 24 часа:
- Диаграмма составлена из 48 точек данных. То есть 24 часа x 2 точки данных в час (60/30 мин), агрегированные 1-минутные точки данных.
- График соединяет 48 точек в области построения диаграммы.
- Каждая точка данных представляет собой сумму всех исходящих сетевых байтов, отправленных в течение каждого из соответствующих 30-минутных периодов времени.

Щелкайте изображения в этом разделе, чтобы просматривать их увеличенные версии.
Если задать степень детализации времени в 15 минут, диаграмма будет содержать 96 агрегированных точек данных. То есть 60/15 мин = 4 точки данных в час x 24 часа.

При степени детализации времени в 5 минут диаграмма будет содержать 24 x (60/5) = 288 точек.
При степени детализации времени, равной 1 минуте (наименьшее возможное значение на диаграмме), диаграмма будет содержать 24 x 60/1 = 1440 точек.

Как показано на предыдущих снимках экрана, диаграммы выглядят по-разному для всех этих суммирований. Обратите внимание, что эта виртуальная машина имеет многочисленные выходные данные за небольшой период времени относительно остальной части периода времени.
Степень детализации времени позволяет настроить на диаграмме соотношение "сигнал — шум". Более высокие агрегаты удаляют шум и сглаживают пики. Обратите внимание на варьирования в нижней части 1-минутной диаграммы и на то, как они сглаживаются при переходе к более высоким значениям степени детализации.
Такое сглаживание важно при отправке этих данных в другие системы, например оповещений. Как правило, вы обычно не хотите быть оповещены короткими пиками времени ЦП более 90 %. Однако, если в течение пяти минут нагрузка процессора остается на уровне 90 %, это, скорее всего, важно. Если вы настроили правило генерации оповещений для ЦП (или любой метрики), увеличение степени детализации времени может уменьшить количество получаемых ложных предупреждений.
Важно установить", что "нормально" для рабочей нагрузки, чтобы узнать, какой интервал времени лучше всего подходит. Это одно из преимуществ динамических оповещений, что является отдельной темой, не рассматриваемой в этой статье.
Как система получает метрики
Сбор данных зависит от определенной метрики.
Примечание.
Приведенные ниже примеры упрощаются для иллюстрации, а фактические данные метрик, включенные в каждую агрегатную обработку, влияют на данные, доступные при выполнении оценки.
Частота сбора измерений
Существует два типа периодов сборов:
Регулярный — метрика собирается в согласованный интервал времени, который не зависит.
На основе действий — метрика собирается в зависимости от того, когда происходит транзакция определенного типа. Каждая транзакция имеет запись метрики и отметку времени. Они не собираются с регулярными интервалами, поэтому за заданный период времени существует разное количество записей.
Степень детализации
Наименьший интервал времени составляет 1 минуту, однако базовая система может сканировать данные быстрее в зависимости от метрики. Например, процент загрузки ЦП для виртуальной машины Azure сканируется с интервалами в 15 секунд. Поскольку сбои HTTP отслеживаются как транзакции, их количество может легко стать больше одного в минуту. Другие метрики, такие как служба хранилища SQL, фиксируются каждые 20 минут. Этот выбор зависит от конкретного поставщика и типа ресурса. Большинство старается обеспечить как можно меньший интервал.
Измерения, разделение и фильтрация
Метрики сканируются для каждого отдельного ресурса. Однако уровень, на котором метрики собираются, хранятся и могут быть отображены на диаграмме, может быть разным. Этот уровень представлен другими метриками, доступными в измерениях метрик. Каждый отдельный поставщик ресурсов сам определяет, насколько подробными будут собираемые им данные. Azure Monitor всего лишь определяет, как такие данные должны быть представлены и сохранены.
При построении диаграммы метрики в обозревателе метрик можно "разделить" ее по измерению. Разделение диаграммы означает, что вы просматриваете базовые данные для получения дополнительных сведений и видите, что данные диаграммы или отфильтрованы в обозревателе метрик.
Например, Microsoft.ApiManagement/service использует для многих метрик в качестве измерения Расположение.
Одна из таких метрик — емкость. Наличие измерения Расположение означает, что базовая система хранит запись метрики для емкости каждого расположения, а не только одну запись метрики для агрегированной суммы. Затем эти сведения можно получить или разделить на диаграмме метрик.
При просмотре Общей длительности запросов шлюза можно заметить 2 измерения, Расположение и Имя узла, что опять же позволяет узнать расположение длительности, а также имя хоста, из которого она поступила.
Одна из более гибких метрик, Запросы, имеет 7 различных измерений.
Дополнительные сведения о каждой из метрик и доступных измерениях см. в статье о поддерживаемых метриках Azure Monitor. Кроме того, в документации по каждому поставщику и типу ресурсов могут содержаться дополнительные сведения об измерениях и о том, что они измеряют.
Разделение и фильтрацию можно использовать совместно, чтобы подробно изучить проблему. Ниже приведен пример графика, отображающего среднее количество байтов записи на Диске для группы виртуальных машин в группе ресурсов. У нас есть свертка всех виртуальных машин с этой метрикой, но нам может потребоваться разобраться, какие показатели отвечают за пики около 6AM. Исходят ли они с одного и того же компьютера? Сколько компьютеров в этом задействовано?

Щелкайте изображения в этом разделе, чтобы просматривать их увеличенные версии.
При применении разделения можно увидеть базовые данные, однако они немного запутанные. Оказывается, на приведенной выше диаграмме агрегировано 20 виртуальных машин. В данном случае мы использовали мышь, чтобы навести курсор на большую пиковую нагрузку, что произошла в 6 утра. В результате мы узнали, что ее причиной является CH-DCVM11. Но невозможно увидеть остальные данные, связанные с этой виртуальной машиной, из-за других виртуальных машин, загромождающих диаграмму.

С помощью фильтрации можно очистить диаграмму, чтобы увидеть, что происходит на самом деле. Можно установить или снять отметки для виртуальных машин, которые требуется просмотреть. Обратите внимание на точечные линии. Они упоминаются в следующем разделе.

Дополнительные сведения о том, как отобразить данные с разделенными измерениями на диаграмме обозревателя метрик, см. в разделе Фильтры и разделение в статье "Расширенные возможности обозревателя метрик".
NULL и нулевые значения
Если система ожидает данные метрики от ресурса, но не получает их, она записывает значение NULL. Значение NULL отличается от нулевого значения. Это особенно важно при вычислении агрегатов и построении диаграмм. Значения NULL не считаются допустимыми измерениями.
На различных диаграммах они отображаются по-разному. Точечные графики не отображают точку на диаграмме. На линейчатых диаграммах не отображается линия. На графиках значение NULL может отображаться в виде пунктирных или точечных линий, как показано на снимке экрана в предыдущем разделе. При вычислении средних значений, включая значения NULL, требуется меньшее количество точек данных, из которых следует взять среднее значение. Это поведение иногда может привести к неожиданному падению значений на диаграмме, хотя меньше, чем если значение было преобразовано в ноль и использовалось в качестве допустимой точки данных.
В пользовательских метриках всегда используются значения NULL, если не удалось получить данные. Что касается метрик платформы, то каждый поставщик ресурсов принимает решение, следует ли использовать нулевые значения или значения NULL, в зависимости от того, что имеет наибольшее значение для заданной метрики.
В оповещениях Azure Monitor используются значения, которые поставщик ресурсов записывает в базу данных метрик, поэтому важно знать, как поставщик ресурсов обрабатывает значения NULL, предварительно просмотрев данные.
Как работает агрегирование
На диаграммах метрик в предыдущей системе показаны различные типы агрегированных данных. Система предварительно удаляет данные, чтобы запрошенные диаграммы могли отображаться быстрее без нескольких повторяющихся вычислений.
В этом примере:
- Мы собираем фиктивную метрику транзакций, называемую сбоями HTTP
- Сервер — это измерение для метрики Сбои HTTP.
- У нас есть 3 сервера — сервер A, B и C.
Чтобы упростить объяснение, мы начнем только с типа агрегирования СУММ.
Агрегирование за менее чем 1 минуту
Первые необработанные данные метрики собираются и хранятся в базе данных метрик Azure Monitor. В таком случае на каждом сервере хранятся записи транзакций с меткой времени, поскольку Сервер является измерением. Учитывая, что наименьший период времени, который можно просмотреть в роли клиента, составляет 1 минуту, эти временные метки прежде всего агрегируются в 1-минутные значения метрики для каждого отдельного сервера. Процесс агрегирования для сервера B показан на графике ниже. Серверы A и C выполняются одинаково, но имеют различные данные.
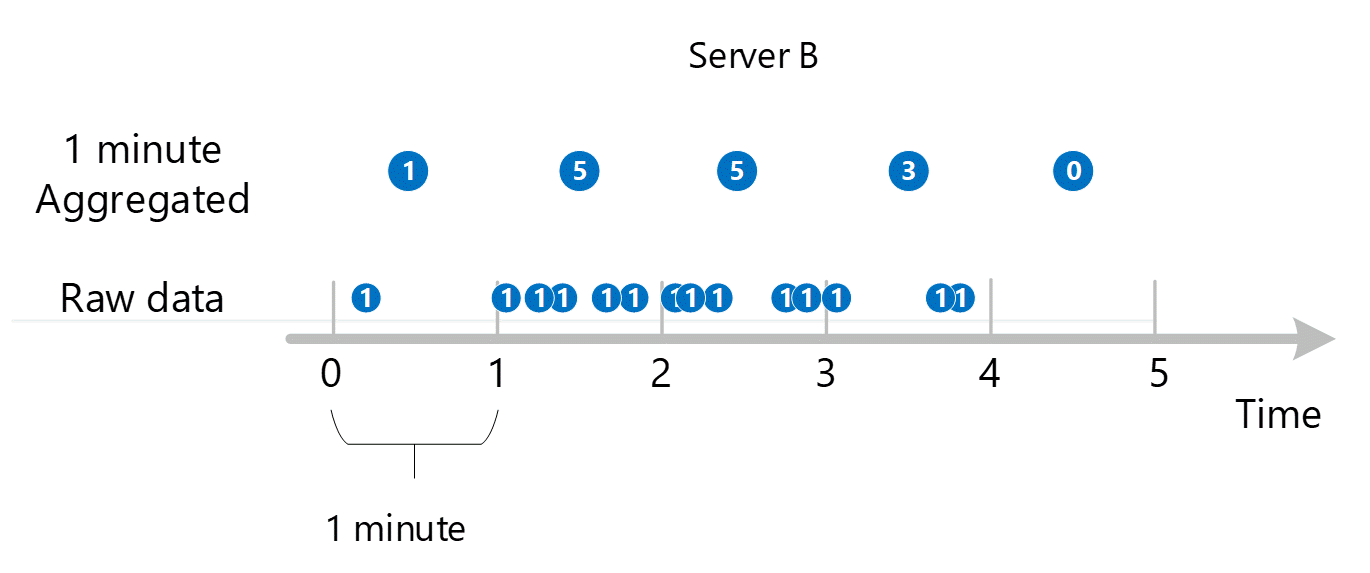
Полученные 1-минутные агрегированные значения сохраняются как новые записи в базе данных метрик, чтобы их можно было собрать для последующих вычислений.
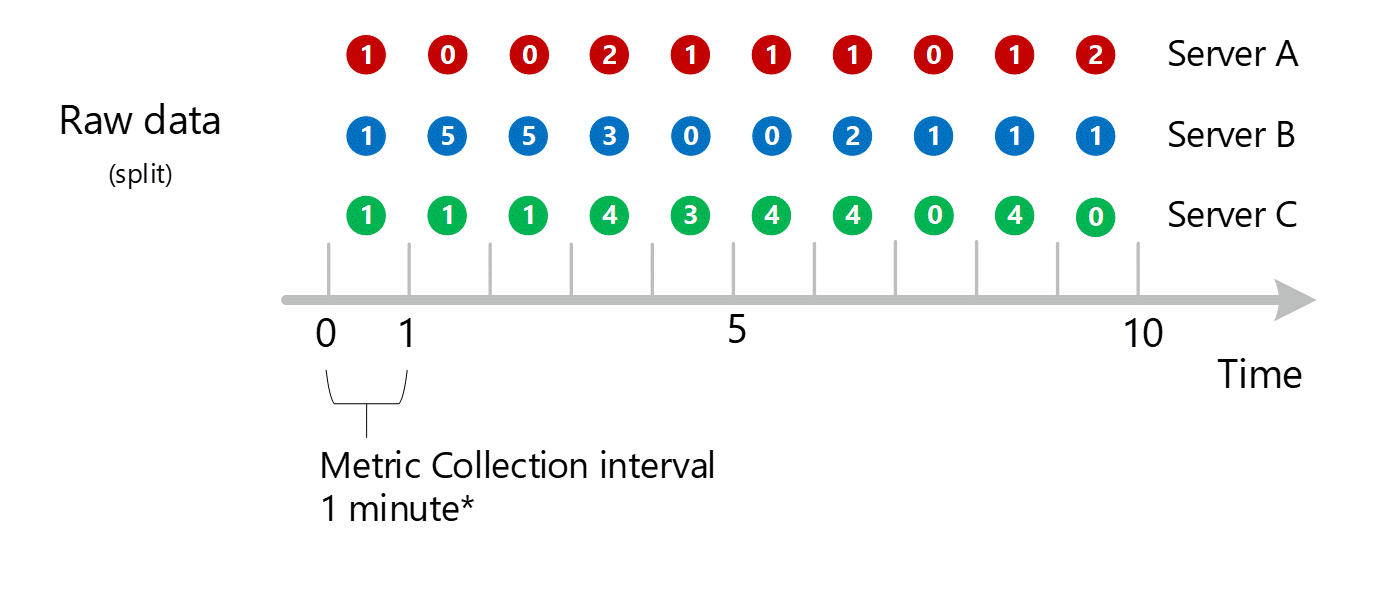
Агрегирование измерений
Затем 1-минутные вычисления сворачиваются по измерениям и снова сохраняются в виде отдельных записей. В этом случае все данные со всех отдельных серверов агрегируются в виде метрики с 1-минутным интервалом и сохраняются в базе данных метрик для использования в последующих агрегатах.

Для наглядности в следующей таблице показан метод агрегирования.
| Период | Сервер A | Сервер B | Сервер В | Sum (A+B+C) |
|---|---|---|---|---|
| Минута 1 | 1 | 1 | 1 | 3 |
| Минута 2 | 0 | 5 | 1 | 6 |
| Минута 3 | 0 | 5 | 1 | 6 |
| Минута 4 | 2 | 3 | 4 | 9 |
| Минута 5 | 1 | 0 | 3 | 4 |
| Минута 6 | 1 | 0 | 4 | 5 |
| Минута 7 | 1 | 2 | 4 | 7 |
| Минута 8 | 0 | 1 | 0 | 1 |
| Минута 9 | 1 | 1 | 4 | 6 |
| Минута 10 | 2 | 1 | 0 | 3 |
Выше показано только одно измерение, однако тот же процесс агрегирования и хранения происходит для всех измерений, поддерживаемых метрикой.
- Собирайте значения в 1-минутные агрегированные наборы по этому измерению. Сохраните эти значения.
- Сверните измерение в виде 1-минутного агрегированного значения суммы (SUM) Сохраните эти значения.
Рассмотрим еще одно измерение сбоев HTTP, именуемое NetworkAdapter. Допустим, у нас есть разное количество адаптеров на каждый сервер.
- Сервер A имеет один адаптер
- Сервер B имеет два адаптера
- Сервер С имеет три адаптера
Мы соберем данные для следующих транзакций отдельно. Они будут помечены:
- Временем
- Значение типа .
- Сервером, из которого поступила транзакция
- Адаптером, из которого поступила транзакция
Затем каждый из этих субминутных потоков будет агрегирован в виде 1-минутного значения временного ряда и сохранен в базе данных метрик Azure Monitor:
- Сервер A, адаптер 1
- Сервер B, адаптер 1
- Сервер B, адаптер 2
- Сервер C, адаптер 1
- Сервер C, адаптер 2
- Сервер C, адаптер 3
Кроме того, будут сохранены следующие свернутые агрегаты:
- Сервер A, адаптер 1 (так как нет ничего для сворачивания, он будет сохранен снова)
- Сервер B, адаптер 1+2
- Сервер C, адаптер 1+2+3
- Все серверы, все адаптеры
Это показывает, что метрики с большим количеством измерений имеют большее число агрегатов. Здесь не так важно знать все перестановки, главное — уловить суть. Для системы важно, чтобы как отдельные, так и агрегированные данные хранились для получения быстрого доступа к любой диаграмме. Система выбирает либо наиболее подходящий сохраненный агрегат, либо базовые необработанные данные в зависимости от того, что именно вы выбрали для отображения.
Агрегирование без измерений
Поскольку эта метрика имеет измерение Сервер, можно получить доступ к базовым данным для серверов A, B и C, указанных выше, с помощью разделения и фильтрации, как объяснялось ранее в этой статье. Если в метрике отсутствует измерение Сервер, вы как клиент можете получить доступ только к 1-минутным агрегированным значениям суммы, которые отображены черным на диаграмме. То есть значения 3, 6, 6, 9 и т. д. Система также не будет выполнять базовую работу для агрегирования разбиения значений, которые никогда не будут использоваться в обозревателе метрик или отправлять их через REST API метрик.
Просмотр степени детализации времени в более 1 минуты
Если вы запрашиваете метрики с большей степенью детализации, система использует агрегированные значения суммы за 1 минуту для вычисления значений суммы с большей степенью детализации времени. Ниже точечными линиями показан метод суммирования для 2-минутной и 5-минутной степени детализации времени. Опять же, мы показываем только тип агрегирования СУММ для простоты.
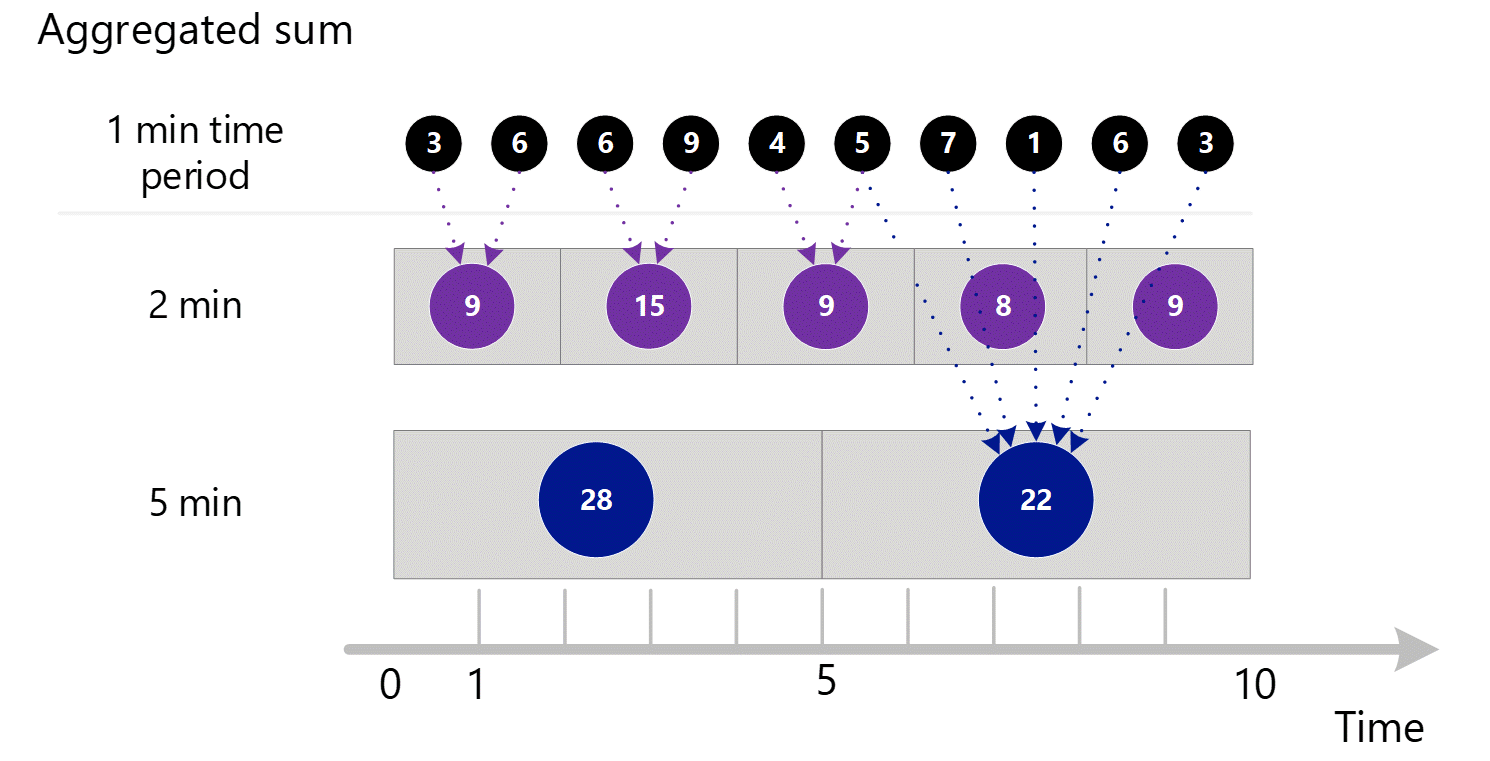
Для 2-минутной степени детализации времени.
| Период | Суммы |
|---|---|
| Минута 1 и 2 | (3 + 6) = 9 |
| Минута 3 и 4 | (6 + 9) = 15 |
| Минута 4 и 5 | (4 + 5) = 9 |
| Минута 6 и 7 | (7 + 1) = 8 |
| Минута 8 и 9 | (6 + 3) = 9 |
Для 5-минутной степени детализации времени.
| Период | Суммы |
|---|---|
| Минуты (с 1 по 5) | 3 + 6 + 6 + 9 + 4 = 28 |
| Минуты (с 6 по 10) | 5 + 7 + 1 + 6 + 3 = 22 |
Система использует сохраненные агрегированные данные, что обеспечивает лучшую производительность.
Ниже приведена большая диаграмма для вышеуказанного 1-минутного процесса агрегирования, на которой некоторые стрелки для улучшения читаемости были пропущены.
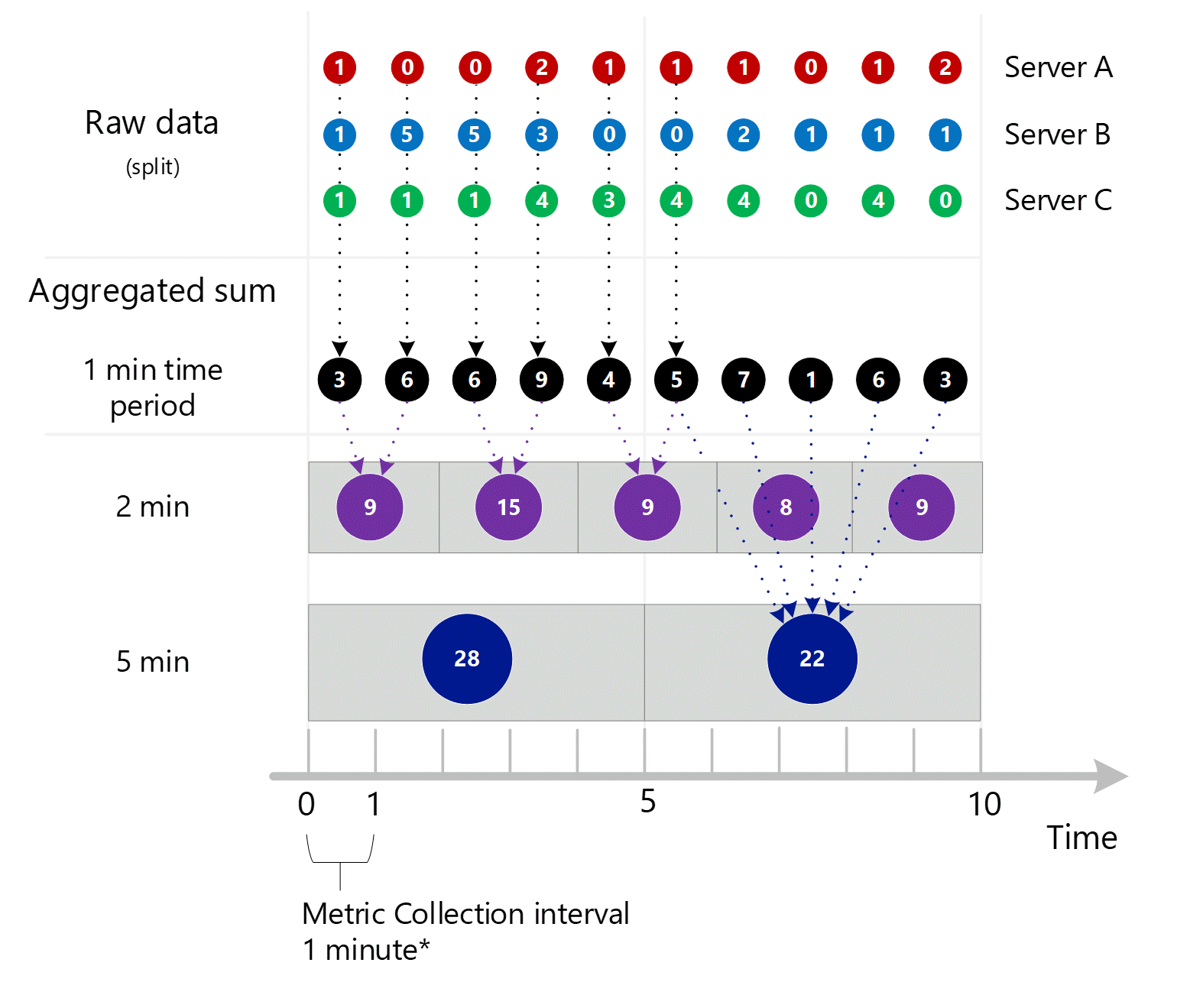
Более сложный пример
Ниже приведен более крупный пример, в котором используются значения фиктивной метрики, называемой временем ответа HTTP в миллисекундах. Здесь мы представляем другие уровни сложности.
- На примере показаны агрегаты для суммы, количества, наибольшего и наименьшего значения, а также для вычисления среднего значения.
- Отображены также значения NULL и их влияние на вычисления.
Рассмотрим следующий пример. Поля и стрелки показывают примеры агрегирования и расчета значений.
Тот же 1-минутный процесс предварительного агрегирования, который описан в предыдущем разделе, выполняется для суммы, количества, наибольшего и наименьшего значения. Тем не менее среднее значение не является предварительно подготовленным. Он пересчитывается с помощью агрегированных данных, чтобы избежать ошибок вычисления.

Рассмотрим минуту 6 для 1-минутного агрегирования, которая выделена на примере выше. В эту минуту сервер B перешел в автономный режим и перестал передавать данные, скорее всего, из-за перезагрузки.
Для минуты 6 из приведенного выше примера вычисленные типы 1-минутного агрегирования такие:
| Тип агрегирования | Значение | Примечания. |
|---|---|---|
| Sum | 53+20=73 | |
| Count | 2 | Отображается результат действия значений NULL. Значение могло бы быть равно 3, если бы сервер был в сети. |
| Минимум | 20 | |
| Максимум | 53 | |
| По средней | 73 / 2 | Сумма всегда делится на количество. Это значение никогда не сохраняется и всегда пересчитывается для каждой степени детализации времени с использованием агрегированных чисел для этой степени детализации. Обратите внимание на пересчет для 5-минутной и 10-минутной степеней детализации времени, который выделен в примере выше. |
Красным цветом текста отмечены значения, которые можно считать выходящими за пределы нормы, а также показано, как они распространяются (или не распространяются) по мере увеличения степени детализации времени. Обратите внимание, что значения Min и Max указывают на наличие базовых аномалий, а Average и Sums теряют эту информацию по мере увеличения степени детализации времени.
Можно также увидеть, что значения NULL обеспечивают лучшее вычисление среднего значения, чем нулевые значения.
Примечание.
Значение Count бывает равно значению Sum в случаях, если метрика всегда сканируется со значением 1 (хотя в данном примере эти значения не равны). Это часто происходит, когда метрика отслеживает возникновение транзакционного события (например, количество сбоев HTTP, упомянутых в предыдущем примере этой статьи).