Real-Time Operational Analytics: Memory-Optimized Tables and Columnstore Index
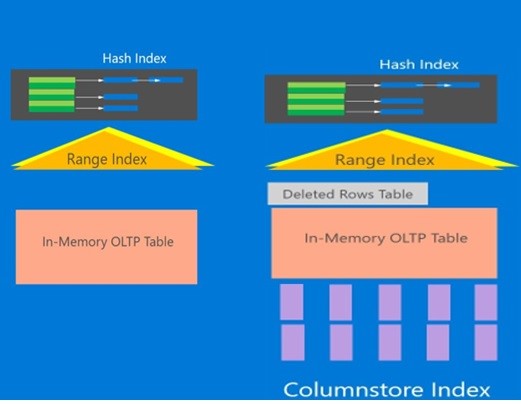
SQL Server 2016 supports real-time operational analytics both for disk-based (i.e. traditional tables) and memory-optimized tables without requiring any changes to your transactional workload. For disk-based tables, you can do it by creating a nonclustered columnstore index (NCCI). For memory-optimized tables, you can do it by creating a clustered columnstore index (CCI). You may wonder why CCI and why not NCCI? Well, there is some history behind it but for now think of this CCI as a special NCCI that includes all the columns from memory-optimized table. Here is the picture that shows a memory-optimized table before and after creating a columnstore index. The purple bars represent the columnstore index. Also note that there is an internal memory-optimized table created to track delete rows. It is similar to the delete-buffer/delete-bitmap for NCCI. Here is the command you can execute to create a columnstore index
Alter table <memory-optimized-table> add index <index-name> clustered columnstore
You can also create a columnstore index at the time the table is created. Please refer to https://msdn.microsoft.com/en-us/library/ms174979.aspx for details.
Once the columnstore index is created, you can now run transactional workload. Just like for NCCI, the new rows are only compressed once they reach the magic count of 1 million rows. There is however one difference here. There is no explicit delta rowgroup. The new rows are only inserted into the memory-optimized table. The rows that are in memory-optimized table but not in columnstore are referred to as the ‘tail’ or the ‘virtual delta rowgroup’ as shown in the picture below. In-memory OLTP tracks the rows in the ‘tail’ efficiently using dedicated memory allocator. When the number of rows in the tail exceeds 1 million rows, a background thread compresses rows in the unit of 1 million rows just like for NCCI. Since the data in the ‘tail’ has no explicit columnstore index, there is no further impact on transactional workload performance when accessing/manipulating data in the ‘tail’. Ideally, you would like to keep ‘hot’ rows (i.e. the ones that are being change frequently) in the tail till the row(s) become dormant or ‘cold’. You can control how long a row stays in the ‘tail’ using compression delay option. Like for NCCI, an analytics query will combine rows both from columnstore index and the ‘tail’ automatically without requiring any changes to the query. One limitation is that the analytic query accessing columnstore index can only be executed in InterOP mode. However, the parallel query plans are supported. 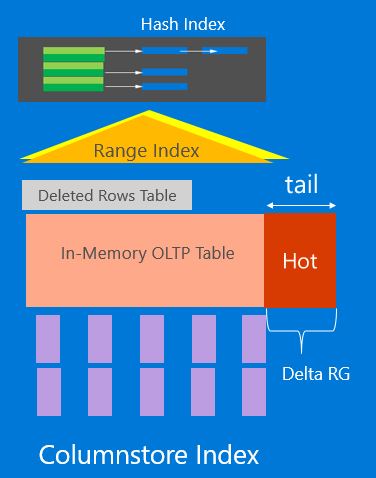
Two other key differences from NCCI are (a) You can’t create a filtered columnstore index (b) columnstore index is persisted but it is required to be fully resident in memory. Yes, it will take additional memory but it should roughly be 10% more as columnstore index typically compresses the data 10x.
SQL Server 2016 is the first commercial database vendor to combine memory-optimized table for extreme OLTP and in-memory analytics using columnstore to deliver real-time operational analytics to customers. You can achieve it with no changes to your operational workload.
I will cover this technology in detail in subsequent blogs
Thanks
Sunil
Comments
- Anonymous
November 08, 2016
Hello, thanks for nice article. MS implemented little differenlty CCI and IM as SAP HANA, but in-memory technology was developed by SAP team in Hasso Plattner Institue 8 years before. MS is not first for sure. See wiki link https://en.wikipedia.org/wiki/List_of_in-memory_databases.Andrej- Anonymous
November 17, 2016
The older in-mem DB system on the list is from 1979. Indeed, many in-mem DB systems have been built in the past. Also columnar database technology has been around for a long time. Per the following Wikipedia article the first one is from 1969: https://en.wikipedia.org/wiki/Column-oriented_DBMSWe believe the columnstore implementation in SQL Server is pretty solid, hence our results with the TPC-H benchmark: http://www.tpc.org/tpch/results/tpch_perf_results.asp?resulttype=NONCLUSTER&version=2%¤cyID=0On top of that, our In-Memory OLTP technology uses highly optimized data access and transaction processing algorithms and is completely lock-free. One customer was able to achieve 1.2 million requests per second on a single machine:https://blogs.msdn.microsoft.com/sqlcat/2016/10/26/how-bwin-is-using-sql-server-2016-in-memory-oltp-to-achieve-unprecedented-performance-and-scale/Thanks,Jos
- Anonymous