Настраиваемое преобразование речи в текстовые контейнеры с помощью Docker
Пользовательская речь в текстовом контейнере транскрибирует речь в режиме реального времени или пакетную звукозапись с промежуточными результатами. Вы можете использовать пользовательскую модель, созданную на пользовательском портале речи. В этой статье вы узнаете, как скачать, установить и запустить настраиваемую речь в текстовом контейнере.
Дополнительные сведения о предварительных требованиях, проверке запуска контейнера, выполнении нескольких контейнеров на одном узле и выполнении отключенных контейнеров см. в разделе "Установка и запуск контейнеров службы "Речь" с помощью Docker.
Образы контейнеров
Пользовательский образ преобразования речи в текстовый контейнер для всех поддерживаемых версий и языковых стандартов можно найти в синдикате Реестра контейнеров Майкрософт (MCR). Он находится в репозитории azure-cognitive-services/speechservices/ и называется custom-speech-to-text.

Полное имя образа контейнера — mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Добавьте определенную версию или добавьте :latest ее, чтобы получить последнюю версию.
| Версия | Путь |
|---|---|
| Latest | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
Все теги, кроме latest, имеют следующий формат и учитывают регистр:
<major>.<minor>.<patch>-<platform>-<prerelease>
Примечание.
voice Пользовательские locale контейнеры речи в текстовые контейнеры определяются пользовательскими моделями, принятыми контейнером.
Теги также доступны в формате JSON для удобства. Текст содержит путь к контейнеру и список тегов. Теги не отсортированы по версии, но "latest" всегда включаются в конец списка, как показано в этом фрагменте кода:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
Получение образа контейнера с помощью команды docker pull
Необходимые компоненты , включая необходимое оборудование. Также см. рекомендуемое выделение ресурсов для каждого контейнера службы "Речь".
Воспользуйтесь командой docker pull, чтобы скачать образ контейнера из реестра контейнеров Microsoft:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Примечание.
Элементы locale и voice для пользовательских речевых контейнеров определяются настраиваемой моделью, принятой контейнером.
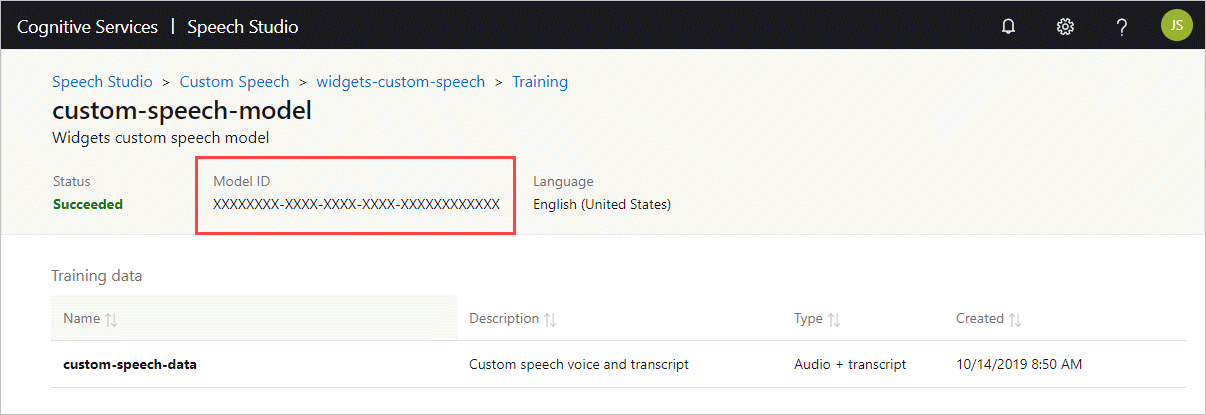
Получение идентификатора модели
Прежде чем запустить контейнер, необходимо знать идентификатор модели пользовательской модели или идентификатор базовой модели. При запуске контейнера необходимо указать один из идентификаторов модели для скачивания и использования.
Пользовательская модель должна быть обучена с помощью Speech Studio. Сведения о том, как получить идентификатор модели, см. в разделе жизненного цикла пользовательской модели речи.
Получите идентификатор модели, который будет использоваться в качестве аргумента для параметра ModelId команды docker run.
Скачивание модели отображения
Перед запуском контейнера можно получить сведения о доступных моделях отображения и скачать эти модели в текстовый контейнер, чтобы получить улучшенные окончательные выходные данные отображения. Скачивание модели отображения доступно с помощью пользовательского контейнера преобразования речи в текст версии 3.1.0 и более поздних версий.
Примечание.
Хотя вы используете docker run команду, контейнер не запускается для службы.
Вы можете запросить или скачать любые из этих типов моделей: переоценка ( Rescore ), пунктуация ( Punct ), пересегментирование ( Resegment ) и wfstitn (Wfstitn). В противном случае можно использовать параметр FullDisplay (с другими типами или без него) для запроса или скачивания всех типов моделей отображения.
Задайте для параметра BaseModelLocale значение, чтобы запросить последнюю доступную модель отображения для целевого языкового стандарта. Если вы включаете несколько типов моделей отображения, команда возвращает последние доступные модели отображения для каждого типа. Например:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Задайте для параметра DisplayLocale значение, чтобы скачать последнюю доступную модель отображения для целевого языкового стандарта. При установке DisplayLocale необходимо также указать FullDisplay или подмножество моделей отображения, разделенных пробелами. Команда скачивает последнюю доступную модель отображения для каждого указанного типа. Например:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Задайте один параметр идентификатора модели, чтобы скачать определенную модель отображения: переоценка ( RescoreId ), пунктуация ( PunctId ), пересегментирование ( ResegmentId ) или wfstitn (WfstitnId). Это похоже на то, как вы скачиваете базовую модель с помощью параметра ModelId. Например, чтобы загрузить модель с отображением переоценки, можно использовать следующую команду с параметром RescoreId:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Примечание.
При задании нескольких параметров запроса или загрузки команда будет определять приоритет в следующем порядке: BaseModelLocale, идентификатор модели, а затем DisplayLocale (применимо только для моделей отображения).
Запуск контейнера с помощью запуска Docker
Используйте команду запуска Docker для запуска контейнера для службы.
В следующей таблице представлены различные параметры docker run и соответствующие им описания.
| Параметр | Описание |
|---|---|
{VOLUME_MOUNT} |
Узел подключения тома главного компьютера, который Docker использует для сохранения настраиваемой модели. Примером является c:\CustomSpeech расположение c:\ диска на хост-компьютере. |
{MODEL_ID} |
Пользовательский идентификатор речи или базовой модели. Дополнительные сведения см. в разделе "Получение идентификатора модели". |
{ENDPOINT_URI} |
Для оценки и выставления счетов требуется конечная точка. Дополнительные сведения см . в разделе аргументов выставления счетов. |
{API_KEY} |
Ключ API не требуется. Дополнительные сведения см . в разделе аргументов выставления счетов. |
При запуске пользовательской речи в текстовый контейнер настройте порт, память и ЦП в соответствии с пользовательскими требованиями к текстовому контейнеру и рекомендациями.
Ниже приведен пример docker run команды со значениями заполнителей. Необходимо указать VOLUME_MOUNTзначения , MODEL_IDENDPOINT_URIи API_KEY значения:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Команда:
- Выполняет настраиваемую речь в текстовом контейнере из образа контейнера.
- Выделяет 4 ядра ЦП и 8 ГБ памяти.
- Загружает пользовательскую речь в текстовую модель из подключения входных данных тома, например C:\CustomSpeech.
- предоставляет TCP-порт 5000 и выделяет псевдотелетайп для контейнера;
- загружает заданную модель
ModelId(если она не найдена в подключении тома). - Если пользовательская модель была скачана ранее, параметр
ModelIdигнорируется. - автоматически удаляет контейнер после завершения его работы. Образ контейнера остается доступным на главном компьютере.
Дополнительные сведения о контейнерах службы "Речь" см. в docker run разделе "Установка и запуск контейнеров службы "Речь" с помощью Docker.
Использование контейнера
Контейнеры службы "Речь" предоставляют API конечных точек запросов на основе websocket, к которым обращается пакет SDK службы "Речь" и CLI службы "Речь". По умолчанию пакет SDK службы "Речь" и cli службы "Речь" используют общедоступную службу "Речь". Чтобы использовать контейнер, вам необходимо изменить метод инициализации.
Внимание
При использовании службы "Речь" с контейнерами обязательно используйте проверку подлинности узла. Если вы настроите ключ и регион, запросы будут отправляться в общедоступную службу "Речь". Результаты службы "Речь" могут не быть ожидаемыми. Запросы от отключенных контейнеров завершаются ошибкой.
Вместо использования этой конфигурации инициализации в облаке Azure:
var config = SpeechConfig.FromSubscription(...);
Используйте эту конфигурацию с узлом контейнера:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Вместо использования этой конфигурации инициализации в облаке Azure:
auto speechConfig = SpeechConfig::FromSubscription(...);
Используйте эту конфигурацию с узлом контейнера:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Вместо использования этой конфигурации инициализации в облаке Azure:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Используйте эту конфигурацию с узлом контейнера:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Вместо использования этой конфигурации инициализации в облаке Azure:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Используйте эту конфигурацию с узлом контейнера:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Вместо использования этой конфигурации инициализации в облаке Azure:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Используйте эту конфигурацию с узлом контейнера:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Вместо использования этой конфигурации инициализации в облаке Azure:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Используйте эту конфигурацию с узлом контейнера:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Вместо использования этой конфигурации инициализации в облаке Azure:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Используйте эту конфигурацию с узлом контейнера:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Вместо использования этой конфигурации инициализации в облаке Azure:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Используйте эту конфигурацию с конечной точкой контейнера:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
При использовании интерфейса командной строки службы "Речь" в контейнере включите --host ws://localhost:5000/ этот параметр. Необходимо также указать --key none , чтобы интерфейс командной строки не использовал ключ службы "Речь" для проверки подлинности. Сведения о настройке интерфейса командной строки службы "Речь" см. в статье "Начало работы с azure AI Speech CLI".
Попробуйте выполнить речь в текстовом кратком руководстве , используя проверку подлинности узла вместо ключа и региона.
Следующие шаги
- Общие сведения о контейнерах службы "Речь"
- Ознакомьтесь со статьей о конфигурации контейнеров.
- Использование дополнительных контейнеров ИИ Azure