Рекомендации по обеспечению надежности развертывания и кластера для Служба Azure Kubernetes (AKS)
В этой статье приведены рекомендации по надежности кластера, реализованной как на уровне развертывания, так и на уровне кластера для рабочих нагрузок Служба Azure Kubernetes (AKS). Эта статья предназначена для операторов кластера и разработчиков, ответственных за развертывание приложений и управление ими в AKS.
Рекомендации, описанные в этой статье, организованы по следующим категориям:
Рекомендации по уровню развертывания
Следующие рекомендации по уровню развертывания помогают обеспечить высокий уровень доступности и надежность рабочих нагрузок AKS. Эти рекомендации — это локальные конфигурации, которые можно реализовать в файлах YAML для модулей pod и развертываний.
Примечание.
Обязательно реализуйте эти рекомендации при каждом развертывании обновления в приложении. В противном случае могут возникнуть проблемы с доступностью и надежностью приложения, например простоем непреднамеренного приложения.
Бюджеты нарушений pod (PDB)
Рекомендации по рекомендациям
Используйте бюджеты нарушений pod (PDB), чтобы обеспечить доступность минимального количества модулей pod во время добровольных сбоев, таких как операции обновления или случайное удаление модулей pod.
Бюджеты прерываний pod (PDBS) позволяют определить способ реагирования на развертывание или наборы реплик во время добровольных сбоев, таких как операции обновления или случайное удаление модулей pod. С помощью PDF-файлов можно определить минимальное или максимальное число недоступных ресурсов. ППР влияют только на API вытеснения для добровольных нарушений.
Например, предположим, что необходимо выполнить обновление кластера и уже определить PDB. Перед обновлением кластера планировщик Kubernetes гарантирует, что доступно минимальное количество модулей pod, определенных в PDB. Если обновление приведет к снижению количества доступных модулей pod ниже минимального значения, определенного в PDBS, планировщик планирует дополнительные модули pod на других узлах, прежде чем разрешить обновление продолжить. Если вы не устанавливаете PDB, планировщик не имеет ограничений на количество модулей pod, которые могут быть недоступны во время обновления, что может привести к нехватке ресурсов и потенциальных сбоев кластера.
В следующем примере файла minAvailable определения PDB поле задает минимальное количество модулей pod, которые должны оставаться доступными во время добровольных сбоев. Это значение может быть абсолютным числом (например, 3) или процентом требуемого количества модулей pod (например, 10%).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
Дополнительные сведения см. в разделе "Планирование доступности с помощью PDF-файлов " и "Указание бюджета нарушения" для приложения.
Ограничения ЦП и памяти pod
Рекомендации по рекомендациям
Установите ограничения ЦП и памяти pod для всех модулей pod, чтобы убедиться, что модули pod не используют все ресурсы на узле и обеспечивают защиту во время угроз службы, таких как атаки DDoS.
Ограничения ЦП и памяти pod определяют максимальный объем ЦП и памяти, которую может использовать модуль pod. Если модуль pod превышает определенные ограничения, он помечается для удаления. Дополнительные сведения см. в разделе "Единицы ресурсов ЦП" в Kubernetes и единицах ресурсов памяти в Kubernetes.
Настройка ограничений ЦП и памяти помогает поддерживать работоспособности узлов и свести к минимуму влияние на другие модули pod на узле. Не настраивайте ограничения pod на больший объем ресурсов ЦП и памяти, чем могут обеспечить узлы. Каждый узел AKS резервирует определенный объем ресурсов ЦП и памяти для основных компонентов Kubernetes. Если установить ограничение pod выше, чем узел может поддерживать, приложение может попытаться использовать слишком много ресурсов и негативно повлиять на другие модули pod на узле. Администраторам кластера необходимо задать квоты ресурсов в пространстве имен, требующее установки запросов ресурсов и ограничений. Дополнительные сведения см. в разделе "Принудительное применение квот ресурсов" в AKS.
В следующем примере файла определения pod раздел resources задает ограничения ЦП и памяти для pod:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
Совет
Вы можете использовать kubectl describe node команду для просмотра емкости ЦП и памяти узлов, как показано в следующем примере:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
Дополнительные сведения см. в статье "Назначение ресурсов ЦП контейнерам и модулям pod " и назначение ресурсов памяти контейнерам и модулям pod.
Предварительные перехватчики
Рекомендации по рекомендациям
При необходимости используйте перехватчики перед остановкой, чтобы обеспечить корректное завершение контейнера.
PreStop Перехватчик вызывается непосредственно перед завершением контейнера из-за запроса API или события управления, например прерывания, несоответствия ресурсов или сбоя пробы запуска. Вызов PreStop перехватчика завершается ошибкой, если контейнер уже находится в завершенном или завершенном состоянии, и перехватчик должен завершиться до отправки сигнала TERM, чтобы остановить контейнер. Льготный период завершения модуля pod начинается до PreStop выполнения перехвата, поэтому контейнер в конечном итоге завершается в течение льготного периода завершения.
В следующем примере файла определения pod показано, как использовать PreStop перехватчик для обеспечения корректного завершения контейнера:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
Дополнительные сведения см. в разделе "Перехватчики жизненного цикла контейнеров" и "Завершение модулей pod".
maxUnavailable
Рекомендации по рекомендациям
Определите максимальное количество модулей pod, которые могут быть недоступны во время последовательного обновления с помощью
maxUnavailableполя в развертывании, чтобы обеспечить доступность минимального количества модулей pod во время обновления.
Поле maxUnavailable указывает максимальное количество модулей pod, которые могут быть недоступны во время процесса обновления. Это значение может быть абсолютным числом (например, 3) или процентом требуемого количества модулей pod (например, 10%). maxUnavailable относится к API удаления, который используется во время последовательного обновления.
В следующем примере манифеста развертывания используется maxAvailable поле для задания максимального количества модулей pod, которые могут быть недоступны во время процесса обновления:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
Дополнительные сведения см. в разделе Max Unavailable.
Ограничения распространения топологии Pod
Рекомендации по рекомендациям
Используйте ограничения распространения топологии pod, чтобы обеспечить распределение модулей pod по разным узлам или зонам для повышения доступности и надежности.
Ограничения распространения топологии pod можно использовать для управления распределением модулей pod по всему кластеру на основе топологии узлов и распределения модулей pod по разным узлам или зонам для повышения доступности и надежности.
В следующем примере файла определения pod показано, как использовать topologySpreadConstraints поле для распространения модулей pod по разным узлам:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
Дополнительные сведения см. в разделе "Ограничения распространения топологии pod".
Готовность, живость и запуск пробы
Рекомендации по рекомендациям
Настройте проверку готовности, активности и запуска при применении для повышения устойчивости при высокой нагрузке и более низких перезапусках контейнеров.
Пробы готовности
В Kubernetes kubelet использует пробы готовности, чтобы узнать, когда контейнер готов к принятию трафика. Модуль pod считается готовым , когда все его контейнеры готовы. Если модуль pod не готов, он удаляется из подсистем балансировки нагрузки службы. Дополнительные сведения см. в разделе "Пробы готовности" в Kubernetes.
В следующем примере файла определения pod показана конфигурация пробы готовности:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Дополнительные сведения см. в разделе "Настройка проб готовности".
Пробы liveness
В Kubernetes kubelet использует пробы активности, чтобы узнать, когда перезапустить контейнер. Если контейнер завершается ошибкой пробы активности, контейнер перезапускается. Дополнительные сведения см. в статье "Пробы Liveness" в Kubernetes.
В следующем примере файла определения pod показана конфигурация пробы активности:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
Другой вид пробы активности использует HTTP-запрос GET. В следующем примере файла определения pod показана конфигурация пробы динамической пробы HTTP-запроса GET:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Дополнительные сведения см. в разделе "Настройка проб активности " и определение HTTP-запроса в реальном времени.
Пробы запуска
В Kubernetes kubelet использует пробы запуска, чтобы узнать, когда запущено приложение контейнера. Когда вы настраиваете пробу запуска, проверка готовности и активности не запускаются до успешного запуска пробы, обеспечивая готовность и работоспособность проб не вмешиваться в запуск приложения. Дополнительные сведения см. в статье "Пробы запуска" в Kubernetes.
В следующем примере файла определения pod показана конфигурация пробы запуска:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
Приложения с несколькими репликами
Рекомендации по рекомендациям
Разверните по крайней мере две реплики приложения, чтобы обеспечить высокий уровень доступности и устойчивость в сценариях вниз узла.
В Kubernetes можно использовать replicas поле в развертывании, чтобы указать количество модулей pod, которые требуется запустить. Выполнение нескольких экземпляров приложения помогает обеспечить высокий уровень доступности и устойчивость в сценариях с узлом. Если у вас есть зоны доступности, можно использовать replicas поле, чтобы указать количество модулей pod, которые необходимо выполнить в нескольких зонах доступности.
В следующем примере файла определения pod показано, как использовать replicas поле для указания количества модулей pod, которые требуется запустить:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Дополнительные сведения см. в разделе "Рекомендуемые решения с высоким уровнем доступности" для AKS и реплик в спецификациях развертывания.
Рекомендации по уровню пула кластеров и узлов
Следующие рекомендации по уровню кластера и пула узлов помогают обеспечить высокий уровень доступности и надежности кластеров AKS. Эти рекомендации можно реализовать при создании или обновлении кластеров AKS.
Зоны доступности
Рекомендации по рекомендациям
Используйте несколько зон доступности при создании кластера AKS, чтобы обеспечить высокий уровень доступности в сценариях с высоким уровнем доступности. Помните, что после создания кластера невозможно изменить конфигурацию зоны доступности.
Зоны доступности — это группы центров обработки данных в пределах региона. Эти зоны достаточно близки, чтобы иметь подключения с низкой задержкой друг к другу, но достаточно далеко друг от друга, чтобы снизить вероятность того, что более одной зоны влияет на локальные сбои или погоду. Использование зон доступности помогает синхронизации и доступности данных в сценариях с зоными. Дополнительные сведения см. в разделе "Выполнение в нескольких зонах".
Автоматическое масштабирование кластера
Рекомендации по рекомендациям
Используйте автомасштабирование кластера, чтобы убедиться, что кластер может обрабатывать повышенную нагрузку и уменьшать затраты во время низкой нагрузки.
Чтобы обеспечить соответствие требованиям приложений в AKS, может потребоваться настроить количество узлов, выполняющих рабочие нагрузки. Компонент автомасштабирования кластера наблюдает за модулями pod в кластере, которые не могут быть запланированы из-за ограничений ресурсов. Когда средство автомасштабирования кластера обнаруживает проблемы, оно масштабирует число узлов в пуле узлов в соответствии с требованиями приложения. Он также регулярно проверяет узлы на наличие нехватки запущенных модулей pod и масштабирует количество узлов по мере необходимости. Дополнительные сведения см. в разделе автомасштабирование кластера в AKS.
Параметр можно использовать --enable-cluster-autoscaler при создании кластера AKS для включения автомасштабирования кластера, как показано в следующем примере:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
Вы также можете включить автомасштабирование кластера в существующем пуле узлов и настроить более детальные сведения об автомасштабировании кластера, изменив значения по умолчанию в профиле автомасштабирования на уровне кластера.
Дополнительные сведения см. в статье Об использовании автомасштабирования кластера в AKS.
Подсистема балансировки нагрузки (цен. категории "Стандартный")
Рекомендации по рекомендациям
Используйте Load Balancer (цен. категория для обеспечения большей надежности и ресурсов, поддержки нескольких зон доступности, проб HTTP и функций в нескольких центрах обработки данных.
В Azure номер SKU Load Balancer (цен. категория предназначен для балансировки трафика сетевого уровня, если требуется высокая производительность и низкая задержка. Load Balancer (цен. категория маршрутизирует трафик в пределах и между регионами и в зоны доступности для обеспечения высокой устойчивости. Номер SKU уровня "Стандартный" — это рекомендуемый номер SKU по умолчанию, используемый при создании кластера AKS.
Внимание
30 сентября 2025 г. базовая подсистема балансировки нагрузки будет прекращена. Дополнительные сведения см. в официальном объявлении. Рекомендуется использовать Load Balancer (цен. категория для новых развертываний и обновления существующих развертываний до Load Balancer (цен. категория . Дополнительные сведения см. в статье об обновлении из Basic Load Balancer.
В следующем примере показан LoadBalancer манифест службы, использующий Load Balancer (цен. категория :
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
Дополнительные сведения см. в статье "Использование стандартной подсистемы балансировки нагрузки" в AKS.
Совет
Вы также можете использовать контроллер входящего трафика или сетку службы для управления сетевым трафиком с каждым вариантом, предоставляющим различные функции и возможности.
Пулы системных узлов
Использование пулов выделенных системных узлов
Рекомендации по рекомендациям
Используйте пулы системных узлов, чтобы гарантировать, что другие пользовательские приложения не выполняются на одних узлах, что может привести к нехватке ресурсов и влиять на системные модули pod.
Используйте пулы выделенных системных узлов, чтобы гарантировать отсутствие других пользовательских приложений на одних узлах, что может привести к нехватке ресурсов и потенциальных сбоев кластера из-за условий гонки. Чтобы использовать выделенный пул системных узлов, можно использовать CriticalAddonsOnly фрагмент в пуле системных узлов. Дополнительные сведения см. в разделе "Использование пулов системных узлов" в AKS.
Автомасштабирование для пулов системных узлов
Рекомендации по рекомендациям
Настройте автомасштабирование для пулов системных узлов, чтобы задать минимальные и максимальные ограничения масштабирования для пула узлов.
Используйте автомасштабирование в пулах узлов, чтобы настроить минимальные и максимальные ограничения масштабирования для пула узлов. Пул системных узлов всегда должен быть в состоянии масштабироваться в соответствии с требованиями системных модулей pod. Если пул системных узлов не может масштабироваться, кластер выходит из ресурсов для управления планированием, масштабированием и балансировкой нагрузки, что может привести к неответственному кластеру.
Дополнительные сведения см. в разделе "Использование автомасштабирования кластера" в пулах узлов.
По крайней мере три узла на пул системных узлов
Рекомендации по рекомендациям
Убедитесь, что пулы системных узлов имеют по крайней мере три узла, чтобы обеспечить устойчивость к сценариям замораживания и обновления, что может привести к перезапуску или закрытию узлов.
Пулы системных узлов используются для запуска системных модулей pod, таких как kube-proxy, coredns и подключаемый модуль Azure CNI. Рекомендуется убедиться, что пулы системных узлов имеют по крайней мере три узла , чтобы обеспечить устойчивость к сценариям замораживания и обновления, что может привести к перезапуску или закрытию узлов. Дополнительные сведения см. в разделе "Управление пулами системных узлов" в AKS.
Ускорение работы в сети
Рекомендации по рекомендациям
Используйте ускоренную сеть, чтобы обеспечить низкую задержку, снижение jitter и уменьшение использования ЦП на виртуальных машинах.
Ускорение сети обеспечивает виртуализацию одно корневых операций ввода-вывода (SR-IOV) в поддерживаемых типах виртуальных машин, что значительно повышает производительность сети.
На следующей схеме показано, как две виртуальные машины взаимодействуют с ускорением сети и без нее.
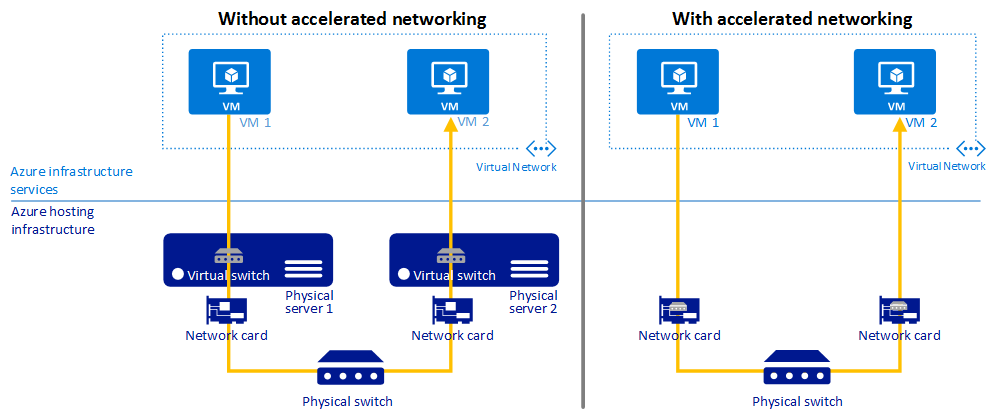
Дополнительные сведения см. в разделе "Ускорение сети".
Версии образов
Рекомендации по рекомендациям
Изображения не должны использовать
latestтег.
Теги образа контейнера
latest Использование тега для образов контейнеров может привести к непредсказуемому поведению и затрудняет отслеживание версии образа, выполняемой в кластере. Эти риски можно свести к минимуму, интегрируя и выполняя средства сканирования и исправления в контейнерах во время сборки и выполнения. Дополнительные сведения см. в рекомендациях по управлению образами контейнеров в AKS.
Обновления образов узлов
AKS предоставляет несколько каналов автоматического обновления для обновлений образа ОС узла. Эти каналы можно использовать для управления временем обновления. Мы рекомендуем присоединиться к этим каналам автоматического обновления, чтобы убедиться, что узлы работают с последними исправлениями безопасности и обновлениями. Дополнительные сведения см. в разделе "Образы ОС узла автоматического обновления" в AKS.
Уровень "Стандартный" для рабочих нагрузок
Рекомендации по рекомендациям
Используйте уровень "Стандартный" для рабочих нагрузок продуктов для повышения надежности кластера и ресурсов, поддержки до 5000 узлов в кластере и обслуживания по времени обслуживания, включенных по умолчанию. Если вам нужен LTS, рассмотрите возможность использования уровня "Премиум".
Уровень "Стандартный" для Служба Azure Kubernetes (AKS) предоставляет финансово поддерживаемое соглашение об уровне обслуживания (SLA) на уровне обслуживания (SLA) для рабочих нагрузок рабочей нагрузки с поддержкой 99,9 %. Уровень "Стандартный" также обеспечивает более высокую надежность кластера и ресурсы, поддержку до 5000 узлов в кластере и соглашение об уровне обслуживания, включенное по умолчанию. Дополнительные сведения см. в разделе "Ценовые категории" для управления кластерами AKS.
Azure CNI для динамического выделения IP-адресов
Рекомендации по рекомендациям
Настройте Azure CNI для динамического выделения IP-адресов для улучшения использования IP-адресов и предотвращения исчерпания IP-адресов для кластеров AKS.
Возможность динамического выделения IP-адресов в Azure CNI выделяет IP-адреса pod из подсети, отдельной от подсети, в котором размещен кластер AKS, и предлагает следующие преимущества:
- Улучшенное использование IP-адресов. IP-адреса выделяются динамически для модулей pod кластера из подсети pod. Это обеспечивает более эффективное использование IP-адресов в кластере по сравнению с традиционным решением CNI, которое выполняет статическое выделение IP-адресов для каждого узла.
- Масштабируемость и гибкость. Подсети узлов и модулей pod можно масштабировать независимо друг от друга. Одну и ту же подсеть pod можно совместно использовать в нескольких пулах узлов кластера или в нескольких кластерах AKS, развернутых в одной виртуальной сети. Можно также настроить отдельную подсеть pod для пула узлов.
- Высокая производительность. Так как модули pod назначены IP-адреса виртуальной сети, они имеют прямое подключение к другим модулям pod кластера и ресурсам в виртуальной сети. Такое решение обеспечивает поддержку очень больших кластеров без снижения производительности.
- Отдельные политики виртуальной сети для модулей pod. Так как модули pod размещаются в отдельной подсети, для них можно настроить отдельные политики виртуальной сети, отличные от политик узлов. Это позволяет использовать множество полезных сценариев, таких как разрешение подключения к Интернету только для модулей pod, а не для узлов, исправление исходного IP-адреса для pod в пуле узлов с помощью шлюза NAT Azure и использование групп безопасности сети для фильтрации трафика между пулами узлов.
- Сетевые политики Kubernetes: политики сети Azure и Calico работают с этим решением.
Дополнительные сведения см. в статье "Настройка сети Azure CNI" для динамического распределения IP-адресов и расширенной поддержки подсети.
Виртуальные машины SKU версии 5
Рекомендации по рекомендациям
Используйте номера SKU виртуальных машин версии 5 для повышения производительности во время и после обновлений, менее общего влияния и более надежного подключения для приложений.
Для пулов узлов в AKS используйте виртуальные машины SKU версии 5 с временными дисками ОС, чтобы обеспечить достаточные вычислительные ресурсы для модулей pod kube-system. Дополнительные сведения см. в рекомендациях по повышению производительности и масштабированию больших рабочих нагрузок в AKS.
Не используйте виртуальные машины серии B
Рекомендации по рекомендациям
Не используйте виртуальные машины серии B для кластеров AKS, так как они не работают хорошо с AKS.
Виртуальные машины серии B являются низкой производительностью и не работают хорошо с AKS. Вместо этого рекомендуется использовать виртуальные машины SKU версии 5.
Диски класса Premium
Рекомендации по рекомендациям
Используйте диски уровня "Премиум" для обеспечения доступности на одной виртуальной машине (виртуальной машине) на 99,9 %.
Диски Azure уровня "Премиум" обеспечивают согласованную задержку в субмиллисекундах и высокий объем операций ввода-вывода в секунду и во всем. Диски уровня "Премиум" предназначены для обеспечения низкой задержки, высокой производительности и согласованной производительности дисков для виртуальных машин.
В следующем примере манифеста YAML показано определение класса хранилища для диска уровня "Премиум":
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Дополнительные сведения см. в статье Об использовании дисков SSD уровня "Премиум" azure версии 2 в AKS.
Аналитика контейнеров
Рекомендации по рекомендациям
Включите Аналитику контейнеров для мониторинга и диагностики производительности контейнерных приложений.
Container Insights — это функция Azure Monitor, которая собирает и анализирует журналы контейнеров из AKS. Собранные данные можно анализировать с помощью коллекции представлений и предварительно созданных книг.
Вы можете включить мониторинг Container Insights в кластере AKS с помощью различных методов. В следующем примере показано, как включить мониторинг Container Insights в существующем кластере с помощью Azure CLI:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
Дополнительные сведения см. в разделе "Включение мониторинга для кластеров Kubernetes".
Политика Azure
Рекомендации по рекомендациям
Применяйте и применяйте требования к безопасности и соответствию требованиям для кластеров AKS с помощью Политика Azure.
Вы можете применять и применять встроенные политики безопасности в кластерах AKS с помощью Политика Azure. Политика Azure помогает применять стандарты организации и оценивать соответствие в масштабе. После установки надстройки Политика Azure для AKS можно применить к кластерам отдельные определения политик или группы определений политик.
Дополнительные сведения см. в статье "Защита кластеров AKS с помощью Политика Azure".
Следующие шаги
В этой статье рассматриваются рекомендации по обеспечению надежности развертывания и кластера для кластеров Служба Azure Kubernetes (AKS). Дополнительные рекомендации см. в следующих статьях:

Azure Kubernetes Service