Что такое озеро данных
Data Lake — это репозиторий для хранения, который может вмещать большой объем данных в собственном необработанном формате. Хранилища озера данных оптимизированы для масштабирования их размера до терабайтов и петабайт данных. Данные обычно приходят из нескольких различных источников и могут включать структурированные, полуструктурированные или неструктурированные данные. Озеро данных помогает хранить все в исходном, нетрансформованном состоянии. Этот метод отличается от традиционного хранилища данных, который преобразует и обрабатывает данные во время приема.
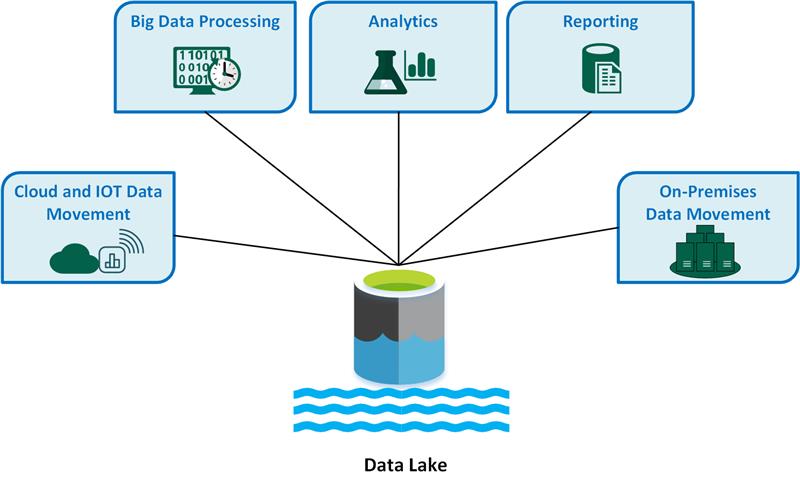
К ключевым вариантам использования озера данных относятся:
- Перемещение данных в облако и Интернет вещей (IoT).
- Обработка больших данных.
- Аналитика.
- Отчеты.
- Перемещение локальных данных.
Рассмотрим следующие преимущества озера данных:
Озеро данных никогда не удаляет данные, так как сохраняет данные в необработанном формате. Эта функция особенно полезна в среде больших данных, так как вы можете заранее не знать, какие аналитические сведения можно получить из данных.
Пользователи могут просматривать данные и создавать собственные запросы.
Озеро данных может быть быстрее, чем традиционные средства извлечения, преобразования, загрузки (ETL).
Озеро данных является более гибким, чем хранилище данных, так как оно может хранить неструктурированные и частично структурированные данные.
Полное решение Data Lake состоит из компонентов хранения и обработки данных. Хранилище озера данных предназначено для отказоустойчивости, бесконечной масштабируемости и приема различных фигур и размеров данных с высокой пропускной способностью. Обработка озера данных включает в себя один или несколько обработчиков обработки, которые могут включать эти цели и могут работать с данными, хранящимися в озере данных в масштабе.
Когда следует использовать озеро данных
Мы рекомендуем использовать озеро данных для изучения данных, аналитики данных и машинного обучения.
Озеро данных может выступать в качестве источника данных для хранилища данных. При использовании этого метода озеро данных получает необработанные данные, а затем преобразует его в структурированный формат, доступный для запросов. Как правило, это преобразование использует конвейер извлечения, загрузки, преобразования (ELT), в котором данные получаются и преобразуются на месте. Реляционные исходные данные могут перейти непосредственно в хранилище данных через процесс ETL и пропустить озеро данных.
Хранилища озера данных можно использовать в сценариях потоковой передачи событий или Интернета вещей, так как озера данных могут сохранять большие объемы реляционных и нереляционных данных без преобразования или определения схемы. Озера данных могут обрабатывать большие объемы небольших операций записи с низкой задержкой и оптимизированы для массовой пропускной способности.
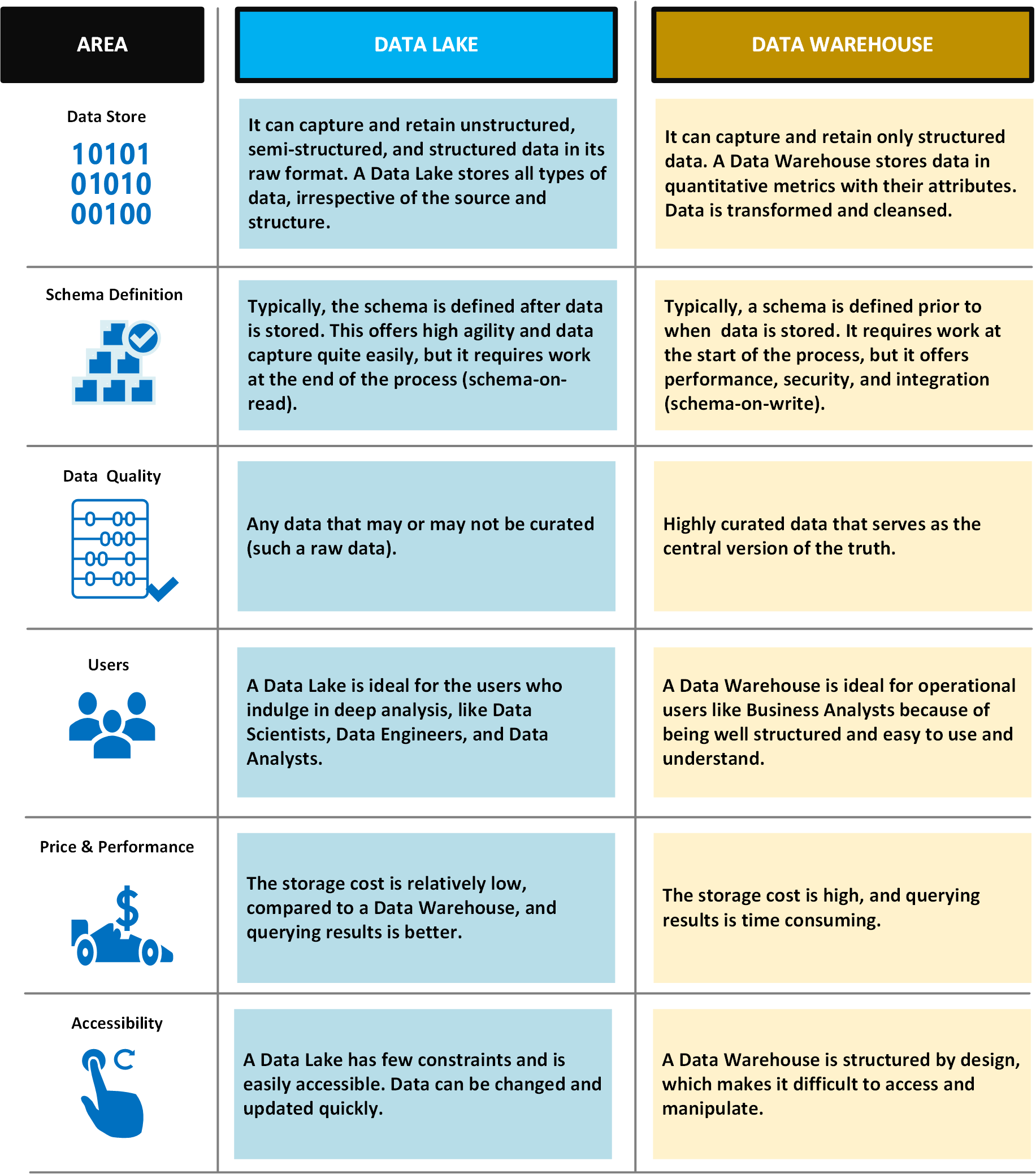
В следующей таблице сравниваются озера данных и хранилища данных.
Сложности
Большие объемы данных: управление большими объемами необработанных и неструктурированных данных может быть сложным и ресурсоемким, поэтому требуется надежная инфраструктура и средства.
Потенциальные узкие места: обработка данных может привести к задержкам и неэффективности, особенно при наличии большого объема данных и различных типов данных.
Риски повреждения данных: неправильное проверка и мониторинг данных приводит к риску повреждения данных, что может скомпрометирует целостность озера данных.
Проблемы контроля качества: надлежащее качество данных является проблемой из-за различных источников данных и форматов. Необходимо реализовать строгие методики управления данными.
Проблемы с производительностью: производительность запросов может снизиться по мере роста озера данных, поэтому необходимо оптимизировать стратегии хранения и обработки.
Выбор технологий
При создании комплексного решения озера данных в Azure рассмотрите следующие технологии:
Azure Data Lake Storage объединяет Хранилище BLOB-объектов Azure с возможностями озера данных, которые обеспечивают доступ, совместимый с Apache Hadoop, иерархические возможности пространства имен и улучшенную безопасность для эффективной аналитики больших данных.
Azure Databricks — это единая платформа, которую можно использовать для обработки, хранения, анализа и монетизации данных. Она поддерживает процессы ETL, панели мониторинга, безопасность, исследование данных, машинное обучение и генерированный ИИ.
Azure Synapse Analytics — это единая служба, которую можно использовать для приема, изучения, подготовки, администрирования и обслуживания данных для немедленных потребностей бизнес-аналитики и машинного обучения. Она интегрируется глубоко с озерами данных Azure, чтобы эффективно запрашивать и анализировать большие наборы данных.
Фабрика данных Azure — это облачная служба интеграции данных, которую можно использовать для создания рабочих процессов, управляемых данными, для оркестрации и автоматизации перемещения и преобразования данных.
Microsoft Fabric — это комплексная платформа данных, которая объединяет инженерию данных, обработку и хранение данных, аналитику в режиме реального времени и бизнес-аналитику в одном решении.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Автор субъекта:
- Avijit Prasad | Консультант по облачным технологиям
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
- Что такое OneLake?
- Общие сведения о Data Lake Storage
- Документация по Azure Data Lake Analytics
- Учебный курс. Введение в Data Lake Storage
- Интеграция Hadoop и Azure Data Lake Storage
- Подключение к Data Lake Storage и хранилищу BLOB-объектов
- Загрузка данных в Data Lake Storage с помощью Фабрика данных Azure