Обработка естественного языка (NLP) имеет много использования: анализ тональности, обнаружение тем, обнаружение языка, извлечение ключевых фраз и классификация документов.
В частности, можно использовать NLP для:
- Классификация документов. Например, документы можно пометить как конфиденциальные или нежелательные.
- Выполните последующую обработку или поиск. Выходные данные NLP можно использовать для этих целей.
- Суммируйте текст, определив сущности, которые присутствуют в документе.
- Пометьте документы ключевыми словами. Для ключевых слов NLP может использовать идентифицированные сущности.
- Выполните поиск на основе содержимого и получение. Добавление тегов делает эту функцию возможной.
- Сводка важных разделов документа. NLP может объединять идентифицированные сущности в разделы.
- Классификация документов для навигации. Для этого NLP использует обнаруженные разделы.
- Перечисление связанных документов на основе выбранного раздела. Для этого NLP использует обнаруженные разделы.
- Оценка текста для тональности. Используя эту функцию, вы можете оценить положительный или отрицательный тон документа.
Apache, Apache® Spark и логотип пламени являются зарегистрированными товарными знаками или товарными знаками Apache Software Foundation в США и/или других странах. Использование этих меток не подразумевает подтверждения от Apache Software Foundation.
Потенциальные варианты использования
Бизнес-сценарии, которые могут воспользоваться пользовательскими NLP, включают:
- Аналитика документов для рукописных или машинных документов в финансах, здравоохранении, розничной торговле, правительстве и других секторах.
- Задачи NLP, не зависящие от отрасли, для обработки текста, такие как распознавание сущностей имен (NER), классификация, суммирование и извлечение связей. Эти задачи автоматизируют процесс извлечения, идентификации и анализа сведений о документе, таких как текст и неструктурированные данные. Примерами этих задач являются модели стратификации рисков, классификация онтологии и сводные данные розничной торговли.
- Получение информации и создание графа знаний для семантического поиска. Эта функция позволяет создавать медицинские графы знаний, поддерживающие обнаружение наркотиков и клинические испытания.
- Перевод текста для систем ИИ для общения в клиентских приложениях в розничной торговле, финансах, путешествиях и других отраслях.
Apache Spark в качестве настраиваемой платформы NLP
Apache Spark — это платформа параллельной обработки, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. Azure Synapse Analytics, Azure HDInsight и Azure Databricks предлагают доступ к Spark и используют свою мощность обработки.
Для настраиваемых рабочих нагрузок NLP Spark NLP служит эффективной платформой для обработки большого количества текста. Эта библиотека NLP с открытым кодом предоставляет библиотеки Python, Java и Scala, которые предлагают полную функциональность традиционных библиотек NLP, таких как spaCy, NLTK, Стэнфорд CoreNLP и Open NLP. Spark NLP также предлагает такие функции, как проверка орфографии, анализ тональности и классификация документов. NLP Spark улучшает предыдущие усилия, обеспечивая точность, скорость и масштабируемость.
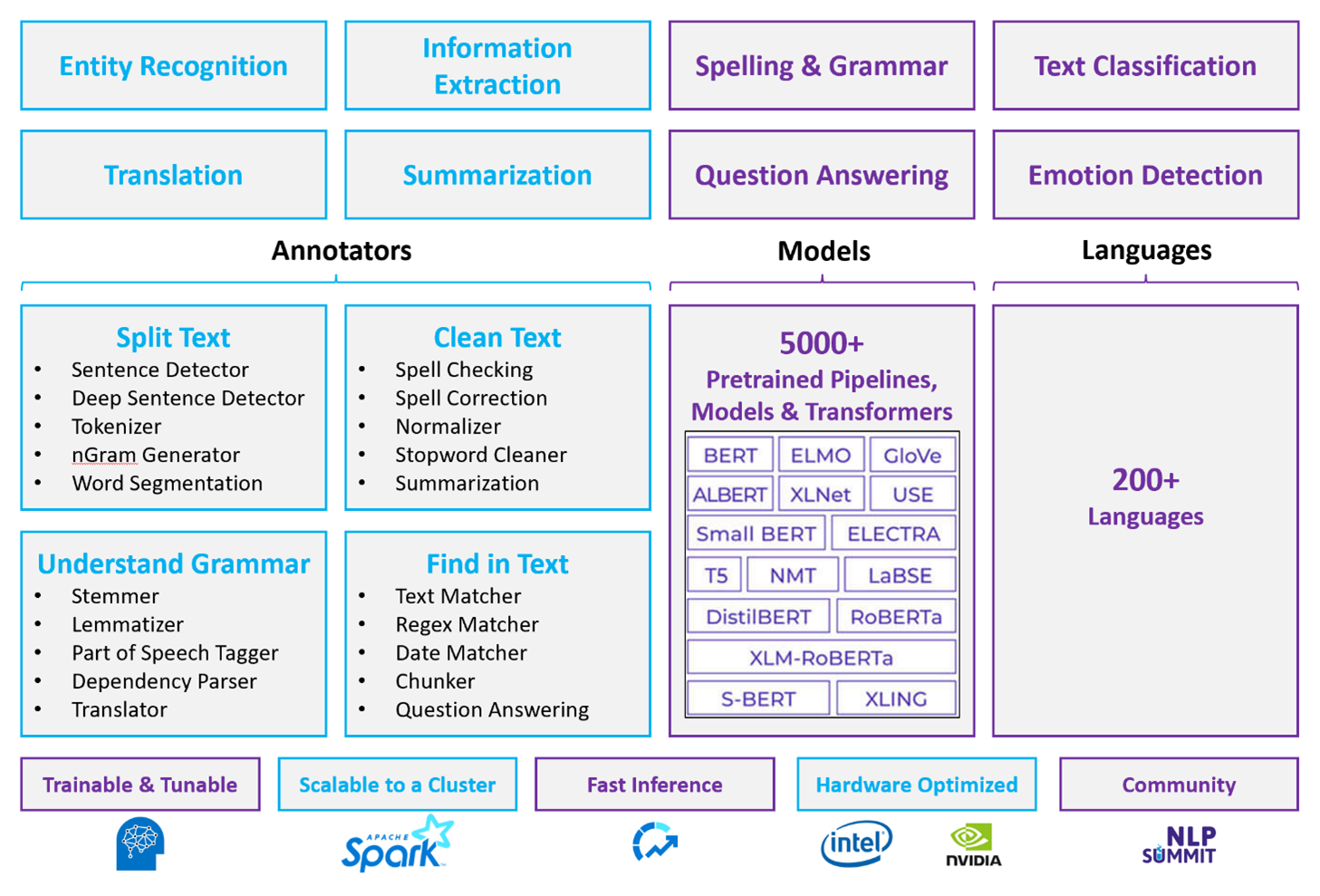
Последние общедоступные тесты показывают Spark NLP как 38 и 80 раз быстрее, чем spaCy, с сравнимой точностью для обучения пользовательских моделей. Spark NLP — это единственная библиотека с открытым исходным кодом, которая может использовать распределенный кластер Spark. Spark NLP — это собственное расширение машинного обучения Spark, которое работает непосредственно на кадрах данных. В результате увеличение скорости в кластере приводит к еще одному упорядочению повышения производительности. Так как каждый конвейер NLP Spark — это конвейер машинного обучения Spark, NLP хорошо подходит для создания унифицированных конвейеров NLP и машинного обучения, таких как классификация документов, прогнозирование рисков и конвейеры рекомендаций.
Помимо отличной производительности, Spark NLP также обеспечивает высокую точность для растущего числа задач NLP. Команда Spark NLP регулярно читает последние актуальные академические документы и реализует современные модели. За последние два-три года лучшие модели использовали глубокое обучение. Библиотека поставляется с предварительно созданными моделями глубокого обучения для распознавания именованных сущностей, классификации документов, обнаружения тональности и распознавания эмоций и обнаружения предложений. Библиотека также включает десятки предварительно обученных языковых моделей, которые включают поддержку слов, блоков, предложений и внедрения документов.
Библиотека оптимизирована для процессоров, GPU и последних микросхем Intel Xeon. Вы можете масштабировать процессы обучения и вывода, чтобы воспользоваться преимуществами кластеров Spark. Эти процессы могут выполняться в рабочей среде на всех популярных платформах аналитики.
Сложности
- Для обработки коллекции текстовых документов свободной формы требуется значительное количество вычислительных ресурсов. Обработка также является интенсивной. Такие процессы часто включают развертывание вычислений GPU.
- Без стандартного формата документа может быть трудно добиться согласованной точности результатов при использовании обработки текста свободной формы для извлечения конкретных фактов из документа. Например, думайте о текстовом представлении счета- это может быть трудно создать процесс, который правильно извлекает номер счета и дату, когда счета находятся у различных поставщиков.
Основные критерии выбора
В Azure службы Spark, такие как Azure Databricks, Azure Synapse Analytics и Azure HDInsight, предоставляют функции NLP при использовании с Spark NLP. Службы ИИ Azure — это еще один вариант для функций NLP. Чтобы решить, какую службу следует использовать, рассмотрите следующие вопросы:
Вы хотите использовать предварительно созданные или предварительно обученные модели? Если да, рассмотрите возможность использования API, предоставляемых службами ИИ Azure. Или скачайте модель по выбору через NLP Spark.
Нужно ли обучать пользовательские модели на основе большой совокупности текстовых данных? Если да, попробуйте использовать Azure Databricks, Azure Synapse Analytics или Azure HDInsight с Spark NLP.
Требуются ли низкоуровневые возможности NLP, например разметка, выделение корней слов, лемматизация и частота условия или инверсная частота в документе? Если да, попробуйте использовать Azure Databricks, Azure Synapse Analytics или Azure HDInsight с Spark NLP. Или используйте библиотеку программного обеспечения с открытым исходным кодом в выбранном средстве обработки.
Требуются ли простые, высокоуровневые возможности NLP, например распознавание сущностей и намерений, распознавание темы, проверка орфографии и анализ тональности. Если да, рассмотрите возможность использования API, предоставляемых службами ИИ Azure. Или скачайте модель по выбору через NLP Spark.
Матрица возможностей
В следующих таблицах приведены основные различия в возможностях служб NLP.
Общие возможности
| Возможность | Служба Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Предоставление предварительно обученных моделей как услуги | Да | Да |
| REST API | Да | Да |
| Программируемость | Python, Scala | Сведения о поддерживаемых языках см. в разделе "Дополнительные ресурсы" |
| Поддерживает обработку наборов больших данных и больших документов | Да | Нет |
Низкоуровневые возможности NLP
| Возможности аннотаторов | Служба Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Детектор предложений | Да | Нет |
| Детектор глубоких предложений | Да | Да |
| Tokenizer | Да | Да |
| Генератор N-грамм | Да | Нет |
| Сегментация Word | Да | Да |
| Парадигматический модуль | Да | Нет |
| Лемматический модуль | Да | Нет |
| Лексико-грамматический анализ | Да | Нет |
| Средство синтаксического анализа зависимостей | Да | Нет |
| Перевод текста | Да | Нет |
| Стоп-слово более чистое | Да | Нет |
| Исправление орфографии | Да | Нет |
| Нормализатор | Да | Да |
| Сопоставление текста | Да | Нет |
| TF/IDF | Да | Нет |
| Сопоставление регулярных выражений | Да | Внедрено в службу Распознавание речи (LUIS). Не поддерживается в беседных Распознавание речи (CLU), которая заменяет LUIS. |
| Сопоставление дат | Да | Возможно, в LUIS и CLU через распознаватели DateTime |
| Блокировщик | Да | Нет |
Высокоуровневые возможности NLP
| Возможность | Служба Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Проверка орфографии | Да | Нет |
| Сводка | Да | Да |
| Ответы на вопросы | Да | Да |
| Определение тональности | Да | Да |
| Определение эмоций | Да | Поддержка интеллектуального анализа мнений |
| Классификация маркеров | Да | Да, с помощью пользовательских моделей |
| Классификация текстов | Да | Да, с помощью пользовательских моделей |
| Текстовое представление | Да | Нет |
| Распознавание именованных сущностей | Да | Да— анализ текста предоставляет набор NER, а пользовательские модели находятся в распознавании сущностей. |
| Распознавание сущностей | Да | Да, с помощью пользовательских моделей |
| Распознавание языка | Да | Да |
| Поддерживает языки, кроме английского языка | Да, поддерживает более 200 языков | Да, поддерживает более 97 языков |
Настройка NLP Spark в Azure
Чтобы установить NLP Spark, используйте следующий код, но замените <version> последним номером версии. Дополнительные сведения см. в документации по NLP Spark.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Разработка конвейеров NLP
Для порядка выполнения конвейера NLP spark NLP следует той же концепции разработки, что и традиционные модели машинного обучения Spark ML. Но В Spark NLP применяются методы NLP.

Основные компоненты конвейера NLP Spark:
DocumentAssembler: преобразователь, который подготавливает данные, изменяя его в формат, который может обрабатывать NLP Spark. Этот этап является точкой входа для каждого конвейера NLP Spark. DocumentAssembler может считывать
Stringстолбец или столбецArray[String]. Можно использоватьsetCleanupModeдля предварительной обработки текста. По умолчанию этот режим отключен.SentenceDetector: annotator, который обнаруживает границы предложения с помощью заданного подхода. Этот аннотатор может возвращать каждое извлеченное предложение в объекте
Array. Он также может возвращать каждое предложение в другой строке, если заданоexplodeSentencesзначение true.Токенизатор: аннотатор, разделяющий необработанный текст на маркеры или единицы, такие как слова, цифры и символы, и возвращает маркеры в
TokenizedSentenceструктуре. Этот класс не подходит. Если вы подходите для маркеризатора, внутреннийRuleFactoryиспользует входную конфигурацию для настройки правил маркеризации. Токенизатор использует открытые стандарты для идентификации маркеров. Если параметры по умолчанию не соответствуют вашим потребностям, можно добавить правила для настройки токенизатора.Нормализатор: annotator, который очищает маркеры. Нормализатор требует стебли. Нормализатор использует регулярные выражения и словарь для преобразования текста и удаления грязных символов.
WordEmbeddings: аноматоры поиска, которые сопоставляют маркеры с векторами. Можно использовать
setStoragePathдля указания словаря поиска пользовательских маркеров для внедрения. Каждая строка словаря должна содержать маркер и его векторное представление, разделенное пробелами. Если маркер не найден в словаре, результатом является нулевой вектор того же измерения.
В NLP Spark используются конвейеры Spark MLlib, которые MLflow изначально поддерживает. MLflow — это платформа с открытым исходным кодом для жизненного цикла машинного обучения. К его компонентам относятся:
- Отслеживание MLflow: записывает эксперименты и предоставляет способ запроса результатов.
- Проекты MLflow: позволяет запускать код для обработки и анализа данных на любой платформе.
- Модели MLflow: развертывает модели в различных средах.
- Реестр моделей: управляет моделями, которые хранятся в центральном репозитории.
MLflow интегрирован в Azure Databricks. MLflow можно установить в любой другой среде Spark для отслеживания экспериментов и управления ими. Реестр моделей MLflow можно также использовать для обеспечения доступности моделей для рабочих целей.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Основные авторы:
- Мориц Стеллер | Старший архитектор облачных решений
- Зойнер Теджада | Генеральный директор и архитектор
Следующие шаги
Документация по Spark NLP:
Компоненты Azure:
Сведения о ресурсах:
Связанные ресурсы
- Крупномасштабная обработка пользовательского естественного языка в Azure
- Выбор технологии служб искусственного интеллекта Microsoft Azure
- Сравнение продуктов и технологий машинного обучения от корпорации Майкрософт
- MLflow и Машинное обучение Azure
- Обогащение ИИ с помощью обработки изображений и естественного языка в Когнитивный поиск Azure
- Анализ веб-каналов новостей с помощью аналитики в режиме реального времени с помощью обработки изображений и естественного языка