Основные сведения о моделях хранилищ данных
Современные бизнес-системы управляют все более большими объемами разнородных данных. Такая разнородность означает, что единственное хранилище данных редко будет оптимальным решением. Вместо этого часто рекомендуется хранить различные типы данных в разных хранилищах данных, каждый из которых ориентирован на определенную рабочую нагрузку или шаблон использования. Термин многоязычное хранение обозначает решения, в которых сочетаются разные технологии хранилища данных. Поэтому важно понимать основные модели хранения и их компромиссы.
Выбор правильного хранилища данных, соответствующего всем требованиям, является для проекта ключевым решением. Выбирать приходится буквально из сотен реализаций баз данных SQL и NoSQL. Хранилища данных обычно различают по методам структурирования данных и типам поддерживаемых операций. В этой статье описаны несколько самых распространенных моделей хранилища. Обратите внимание, что некоторые технологии хранилища данных поддерживают несколько моделей хранилища. Например, реляционная СУБД поддерживает технологии хранилища пар "ключ — значение" или графов. На самом деле, существует общая тенденция так называемой поддержки с несколькими моделями , где одна система базы данных поддерживает несколько моделей. Но узнать о других моделях будет полезно в любом случае.
Хранилища данных, включенные в одну категорию, не обязательно предоставляют одинаковый набор возможностей. Большинство хранилищ данных выполняют обработку запросов и данных на стороне сервера. Иногда эта функция встроена в подсистему хранилища данных. В других случаях функции обработки данных вынесены в отдельный модуль или несколько модулей для обработки и анализа. Хранилища данных также поддерживают разные интерфейсы программного доступа и управления.
Для начала вам следует решить, какая модель хранилища отвечает вашим требованиям. Затем найдите конкретное хранилище данных в этой категории, учитывая такие факторы, как набор функций, стоимость и простота управления.
Примечание.
Узнайте больше о выявлении и проверке требований к службе данных для внедрения облака в Microsoft Cloud Adoption Framework для Azure. Кроме того, вы также можете узнать о выборе средств хранения и служб.
Реляционные СУБД
Реляционные базы данных хранят данные в наборе двумерных таблиц со строками и столбцами. Большинство поставщиков предоставляют диалект язык SQL (SQL) для получения и управления данными. Как правило, реляционная СУБД реализует для обновления информации транзакционно согласованный механизм, который соответствует модели ACID (Atomic = атомарность, Consistent = согласованность, Isolated = изоляция, Durable = устойчивость).
Реляционная СУБД часто поддерживает модель "схема для записи". В этой схеме сначала определяется структура данных, а затем она применяется для всех операций чтения или записи.
Эта модель очень полезна, если важны надежные гарантии согласованности , где все изменения атомарны, и транзакции всегда покидают данные в согласованном состоянии. Однако RDBMS обычно не может горизонтально масштабироваться без сегментирования данных каким-то образом. Кроме того, данные в RDBMS должны быть нормализованы, что не подходит для каждого набора данных.
Службы Azure;
- | База данных SQL Azure(базовые показатели безопасности)
- | База данных Azure для MySQL(базовые показатели безопасности)
- | База данных Azure для PostgreSQL(базовые показатели безопасности)
- | База данных Azure для MariaDB(Базовые показатели безопасности)
Рабочая нагрузка
- Записи часто создаются и обновляются.
- Несколько операций должны выполниться в одной транзакции.
- Связи задаются по ограничениям базы данных.
- Индексы используются для оптимизации производительности запросов.
Тип данных
- Данные имеют высокую степень нормализации.
- Схемы базы данных требуются и принудительно применяются.
- Для данных в базе данных настроена связь "многие ко многим".
- Ограничения определяются в схеме и применяются к любым данным в базе данных.
- Данные требуют высокого уровня целостности. Индексы и связи требуют осторожного использования.
- Данные требуют строгой согласованности. Транзакции осуществляются таким образом, который гарантирует, что все данные полностью согласованы для всех пользователей и процессов
- Размер отдельных записей данных меньше среднего размера.
Примеры
- Управление запасами
- управление заказами;
- База данных отчетов
- Учет
Хранилище пар "ключ — значение"
Хранилище ключей и значений связывает каждое значение данных с уникальным ключом. Большинство хранилищ пар "ключ — значение" поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.
Приложение может хранить произвольные данные в виде набора значений. Все сведения о схеме должны быть предоставлены приложением. Хранилище ключей и значений просто извлекает или сохраняет значение по ключу.
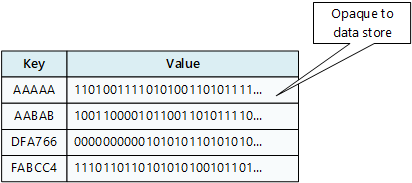
Хранилища ключей и значений оптимизированы для приложений, выполняющих простые подстановки, но менее подходящи, если необходимо запрашивать данные в разных хранилищах ключей и значений. Хранилища ключей и значений также не оптимизированы для запроса по значению.
Одно хранилище пар "ключ — значение" очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Службы Azure;
- Azure Cosmos DB для таблицы и Azure Cosmos DB для NoSQL | (базовые показатели безопасности Azure Cosmos DB)
- | Кэш Azure для Redis(базовые показатели безопасности)
- Таблица Azure служба хранилища | (базовые показатели безопасности)
Рабочая нагрузка
- Доступ к данным осуществляется с помощью одного ключа, например словаря.
- Соединения, блокировки или объединения не нужны.
- Механизмы статистической обработки не используются.
- Как правило, вторичные индексы не используются.
Тип данных
- Каждый ключ связан с одним значением.
- Схема не применяется.
- Сущности не связаны.
Примеры
- Кэширование данных
- Управление сеансом
- Управления параметрами и профилями пользователя
- Рекомендации по продуктам и реклама
Базы данных документов
База данных документов хранит коллекцию документов, в которой каждый документ состоит из именованных полей и данных. Эти данные могут быть простыми значениями или сложными элементами, такими как списки и дочерние коллекции. Документы извлекаются уникальными ключами.
Как правило, документ содержит данные для одной сущности, например клиента или заказа. Документ может содержать сведения, которые будут распространяться по нескольким реляционным таблицам в RDBMS. Документы не должны иметь ту же структуру. Приложения могут сохранять в документах различные данные по мере изменения бизнес-требований.
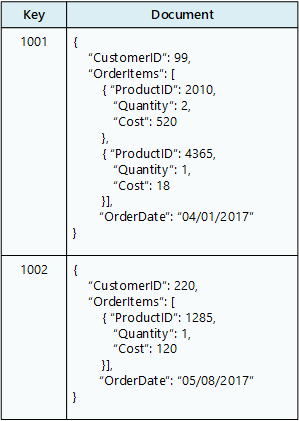
Служба Azure
Рабочая нагрузка
- Операции вставки и обновления являются общими.
- Нет объектно-реляционной несогласованности. Документы можно эффективнее сопоставить со структурами объектов, используемыми в коде приложения.
- Отдельные документы извлекаются и записываются как единый блок.
- Данным требуется индекс по нескольким полям.
Тип данных
- Данными можно управлять не нормализованно.
- Размер отдельных блоков данных документа относительно невелик.
- Тип каждого документа может использовать собственную схему.
- Документы могут содержать дополнительные поля.
- Данные документа полуструктурированные. Это означает, что типы данных каждого поля не строго определены.
Примеры
- Каталог продукции
- Управление содержимым
- Управление запасами
Графовые базы данных
База данных графов хранит сведения двух типов: узлы и грани. Ребра указывают связи между узлами. Узлы и ребра могут иметь свойства, предоставляющие сведения об этом узле или ребрах, аналогичные столбцам в таблице. Грани могут иметь направление, указывающее на характер связи.
Базы данных Graph могут эффективно выполнять запросы в сети узлов и ребер и анализировать связи между сущностями. На следующей схеме представлена база данных персонала организации, структурированная в виде графа. Сущности — это сотрудники и отделы, а края — это отношения отчетов и отделы, в которых работают сотрудники.
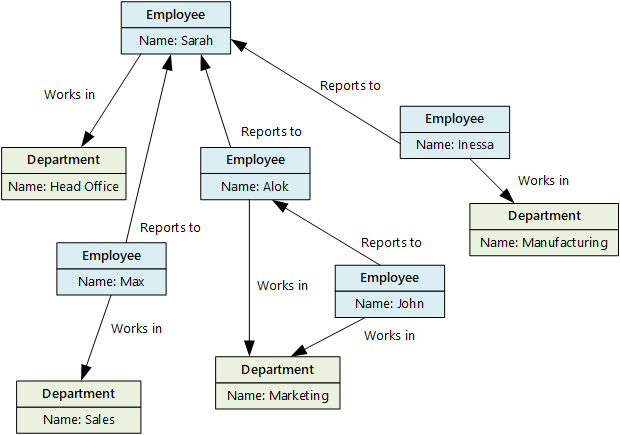
Эта структура упрощает выполнение таких запросов, как "Поиск всех сотрудников, которые сообщают прямо или косвенно Сара" или "Кто работает в том же отделе, что и Джон?" Для больших графов с большим количеством сущностей и связей можно быстро выполнять очень сложный анализ. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Службы Azure;
- Azure Cosmos DB для Apache Gremlin | (базовые показатели безопасности)
- SQL Server | (базовые показатели безопасности)
Рабочая нагрузка
- Сложные связи между элементами данных, включающими много прыжков между связанными элементами данных.
- Связи между элементами данных динамические и изменяются со временем.
- Отношения между объектами являются привилегированными. Для обхода не требуются внешние ключи и соединения.
Тип данных
- Узлы и связи.
- Узлы похожи на строки таблицы или документы JSON.
- Связи так же важны, как и узлы, и явно предоставляются на языке запросов.
- Составные объекты, такие как пользователь с несколькими телефонными номерами, как правило, разделяются на несколько отдельных небольших узлов в сочетании с переходными связями.
Примеры
- Организационные диаграммы
- Графы социальных сетей
- Обнаружение мошенничества
- Системы рекомендаций
аналитика данных
Хранилища аналитики данных предоставляют решения для масштабной параллельной обработки, хранения и анализа данных. Данные распределяются по нескольким серверам для максимальной масштабируемости. Большие форматы файлов данных, такие как файлы разделителей (CSV), parquet и ORC , широко используются в аналитике данных. Исторические данные обычно хранятся в хранилищах данных, таких как хранилище BLOB-объектов или Azure Data Lake Storage 2-го поколения, которые затем получают доступ к Azure Synapse, Databricks или HDInsight как внешние таблицы. Типичный сценарий использования данных, хранящихся в качестве файлов parquet для производительности, описан в статье "Использование внешних таблиц с Synapse SQL".
Службы Azure;
- Azure Synapse Analytics | (базовые показатели безопасности)
- Azure Data Lake | (базовые показатели безопасности)
- Azure Data Обозреватель | (Базовые показатели безопасности)
- Azure Analysis Services;
- HDInsight | (базовые показатели безопасности)
- Azure Databricks(базовые показатели | безопасности)
Рабочая нагрузка
- аналитика данных
- Корпоративная бизнес-аналитика
Тип данных
- Исторические данные из нескольких источников.
- Обычно денормализовано в схеме типа "звезда" или "снежинка", состоящей из таблиц фактов и измерений.
- Как правило, новые данные загружаются по расписанию.
- Таблицы измерений часто включают в себя несколько исторических версий сущности, называемых медленно изменяющимися измерениями.
Примеры
- Корпоративное хранилище данных
Базы данных столбцов
Базы данных столбцов хранят распределяют данные по строкам и столбцам. База данных столбцов в простейшей форме почти неотличима от реляционной базы данных, по крайней мере организационно. Настоящим преимуществом базы данных столбцов является способность денормализованно структурировать разреженные данные.
Базу данных столбцов можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные для одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории баз данных. Семейства столбцов очень хорошо подходят для хранения структурированных изменчивых данных.

В отличие от хранилища пар "ключ — значение" и баз данных документов, большинство хранилищ столбцов используют для упорядоченного хранения данных сами значения ключей, а не хэш-коды от них. Многие реализации позволяют создавать индексы по определенным столбцам в семействе столбцов. Индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Чтение и запись одной строки для одного семейства столбцов обычно являются атомарными операциями. Но некоторые реализации поддерживают атомарность для всей строки, распределенной по нескольким семействам столбцов.
Службы Azure;
- Azure Cosmos DB для Apache Cassandra | (базовые показатели безопасности)
- HBase в HDInsight | (базовые показатели безопасности)
Рабочая нагрузка
- В большинстве баз данных столбцов операции записи выполняются очень быстро.
- Операции обновления и удаления выполняются редко.
- Предназначены для обеспечения доступа с высокой пропускной способностью и малой задержкой.
- Поддерживают простой доступ с выполнением запроса к конкретному набору полей в большой записи.
- Высокая масштабируемость.
Тип данных
- Данные хранятся в таблицах, состоящих из ключевого столбца и одного или нескольких наборов столбцов.
- Определенные столбцы изменяются в зависимости от отдельных строк.
- Доступ к отдельным ячейкам осуществляется с использованием команд GET и PUT.
- Несколько строк возвращаются с использованием команды проверки.
Примеры
- Рекомендации
- Персонализация
- информация от датчиков;
- Телеметрия
- Обмен сообщениями
- Анализ социальных сетей
- Веб-аналитика
- Мониторинг активности
- Прогнозные данные и другие данные временных рядов
Базы данных поисковой системы
База данных поисковой системы позволяет приложениям искать информацию, удерживаемую во внешних хранилищах данных. База данных поисковой системы может индексировать большие объемы данных и предоставлять практически в реальном времени доступ к этим индексам.
В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных. Индексирование может выполняться по модели извлечения, то есть по требованию базы данных, или по модели передачи, то есть по команде из кода внешнего приложения.
Поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые поисковые системы поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, dogs будет считаться соответствием для pets) и морфологии (поиск любых однокоренных слов).
Служба Azure
Рабочая нагрузка
- Индексы данных из нескольких источников и служб.
- Запросы являются специализированными и могут быть сложными.
- Требуется полнотекстовый поиск.
- Требуется специализированный запрос на самообслуживание.
Тип данных
- Полуструктурированный или неструктурированный текст
- Текст со ссылкой на структурированные данные
Примеры
- Каталоги продуктов
- Поиск на сайте
- Ведение журнала
Базы данных временных рядов
Данные временных рядов — это набор значений, упорядоченных по времени. Базы данных временных рядов обычно собирают большие объемы данных в реальном времени из большого количества источников. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией. Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается.
Служба Azure
Рабочая нагрузка
- Записи обычно добавляются последовательно по времени.
- Большая часть операций (95–99 %) — это операции записи.
- Обновления происходят редко.
- Удаление выполняется в пакетном режиме. Удаляются смежные блоки или записи.
- Данные считываются последовательно в порядке возрастания или убывания времени параллельно.
Тип данных
- Метка времени используется в качестве первичного ключа и механизма сортировки.
- Теги могут определять дополнительные сведения о типе, источнике и других сведениях о записи.
Примеры
- Мониторинг и телеметрия событий.
- Данные датчиков или другие данные Интернета вещей.
Хранилище объектов
Хранилище объектов оптимизировано для хранения и извлечения больших двоичных объектов (изображения, файлы, видео- и аудиопотоки, объекты данных и документы приложений большого размера, образы дисков для виртуальных машин). Большие файлы данных также часто используются в этой модели, например файл разделителя (CSV), parquet и ORC. Хранилища объектов могут управлять чрезвычайно большими объемами неструктурированных данных.
Служба Azure
- | Хранилище BLOB-объектов Azure(базовые показатели безопасности)
- | Azure Data Lake Storage 2-го поколения(Базовые показатели безопасности)
Рабочая нагрузка
- Определяется ключом.
- Содержимое обычно является ресурсом, таким как разделитель, изображение или видеофайл.
- Содержимое должно быть устойчивым и внешним для любого уровня приложений.
Тип данных
- Данные большого размера.
- Значение является непрозрачным.
Примеры
- Изображения, видео, офисные документы, PDF-файлы
- Статический HTML, JSON, CSS
- Файлы журнала и аудита
- Резервные копии баз данных
Общие файлы
В некоторых случаях самой эффективной системой хранения и извлечения данных будут простые неструктурированные файлы. Использование общих файловых ресурсов позволяет использовать их совместно через компьютерную сеть. Если созданы необходимые механизмы для поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Служба Azure
Рабочая нагрузка
- Миграция из имеющихся приложений, взаимодействующих с файловой системой.
- Требуется интерфейс SMB.
Тип данных
- Файлы в наборе папок иерархической структуры.
- Доступны в стандартных библиотеках ввода-вывода.
Примеры
- Устаревшие файлы
- Общее содержимое доступно в нескольких виртуальных машинах или экземплярах приложения
Благодаря этому пониманию различных моделей хранения данных необходимо оценить рабочую нагрузку и приложение, а также определить, какое хранилище данных будет соответствовать вашим конкретным потребностям. Используйте дерево принятия решений о хранении данных, чтобы помочь в этом процессе.
Следующие шаги
- Решения и службы облачных служба хранилища Azure
- Просмотр параметров хранилища
- Введение в хранилище Azure
- Общие сведения о Обозреватель данных Azure