Выбор одного экземпляра как лидера, который несет ответственность за управление другими экземплярами для координации действий, выполняемых экземплярами, объединенными совместной задачей в распределенном приложении. Это позволяет обеспечить, чтобы экземпляры не конфликтовали друг с другом, не было конфликта между совместно используемыми ресурсами и не возникало непреднамеренного вмешательства в работу, выполняемую другими экземплярами.
Контекст и проблема
В типичном облачном приложении согласованно выполняется множество задач. Все эти задачи могут быть экземплярами, которые выполняются одним и тем же кодом и которым требуется доступ к тем же ресурсам. Или могут работать вместе в параллельном режиме и выполнять отдельные части сложного вычисления.
Экземпляры задач могут выполняться отдельно в течение большей части времени, но может потребоваться также для координации действий каждого экземпляра, чтобы убедиться, что они не конфликтуют, вызывают конфликты для общих ресурсов или случайно вмешиваются в работу, которую выполняют другие экземпляры задач.
Например:
- В облачной системе, реализующей горизонтальное масштабирование, одновременно может выполняться несколько экземпляров одной задачи, при этом каждый экземпляр может обслуживать другого пользователя. Если эти экземпляры выполняют запись в общий ресурс, то необходимо координировать их действия, чтобы каждый экземпляр не перезаписывал изменения, внесенные другими экземплярами.
- Если задачи параллельно выполняют отдельные элементы сложного вычисления, то результаты должны вычисляться после их полного завершения.
Все экземпляры задач являются кэширующими узлами, поэтому среди них нет естественного лидера, который бы действовал как координатор или агрегатор.
Решение
В качестве лидера необходимо выбрать один экземпляр задачи, и этот экземпляр будет координировать действия других подчиненных экземпляров задач. Если все экземпляры задач выполняются одним и тем же кодом, то все они могут выступать в качестве лидера. Таким образом, процесс выборов должен быть тщательно управляем, чтобы предотвратить одновременное принятие двух или более экземпляров на должность лидера.
Система должна предоставлять надежный механизм для выбора лидера. Этот метод должен справляться с такими событиями, как сбои сети или сбои рабочего процесса. Во многих решениях подчиненные экземпляры задач выполняют мониторинг лидера посредством так называемого метода пульса или с помощью опроса. Если назначенный лидер неожиданно завершает работу, или если сбой сети делает лидера недоступным для подчиненных экземпляров задач, то им необходимо выбрать нового лидера.
Существует несколько стратегий выбора лидера среди набора задач в распределенной среде, в том числе:
- Состязание для получения общего распределенного мьютекса. Первый экземпляр задачи, который получит мьютекс, становится лидером. При этом системе необходимо убедиться, что если лидер завершает работу или отключается от остальной части системы, то мьютекс отменяется, чтобы другой экземпляр задачи мог стать лидером. Эта стратегия показана в приведенном ниже примере.
- Реализация одного из распространенных алгоритмов выборов лидера, таких как алгоритм хулиганов, алгоритм консенсуса Raft или кольцевой алгоритм. Эти алгоритмы предполагают, что каждый кандидат при выборе имеет уникальный идентификатор, и что он может надежно взаимодействовать с другими кандидатами.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Процесс выбора лидера должен быть устойчивым к временным и постоянным сбоям.
- Должна быть возможность выявления ситуаций, когда в лидере произошел сбой или он стал недоступным по другой причине (например, из-за ошибки связи). Необходимая скорость выявления зависит от системы. Некоторые системы способны какое-то время функционировать без лидера. В этот период временная ошибка может быть исправлена. В других случаях может потребоваться немедленно обнаружить сбой лидера и запустить новый процесс выбора.
- В системе, в которой реализовано горизонтальное автомасштабирование, лидер может выйти из строя, если система выполнит обратное масштабирование и, как следствие, завершит работу некоторых вычислительных ресурсов.
- Использование общего распределенного мьютекса вводит зависимость от внешней службы, которая предоставляет мьютекс. Служба представляет собой единую точку отказа. Если она станет недоступной по какой-либо причине, система не сможет выбрать лидера.
- Использование одного выделенного процесса в качестве лидера является простым подходом. Тем не менее, в случае сбоя процесса может возникать значительная задержка при его перезапуске. Эта задержка может негативно влиять на производительность и время отклика других процессов, если они ожидают действий лидера по координации операции.
- Реализация одного из алгоритмов выбора лидера вручную обеспечивает наибольшую гибкость для настройки и оптимизации кода.
- Старайтесь не делать лидером узкое место в системе. Цель руководителя заключается в координации работы подчиненных задач, и не обязательно должно участвовать в этой работе, хотя она должна быть в состоянии сделать это, если задача не избрана в качестве лидера.
Когда следует использовать этот шаблон
Используйте этот шаблон, когда задачи в распределенном приложении (например, размещенном в облаке решении) нуждаются в тщательной координации, а естественный лидер отсутствует.
Этот шаблон может оказаться неэффективным в следующих случаях:
- Существует естественный лидер или выделенный процесс, который всегда может выступить в качестве лидера. Например, может быть возможность реализовать одноэлементный процесс, координирующий экземпляры задач. Если произойдет сбой этого процесса или он станет неработоспособным, то система может завершить его работу и перезапустить его.
- Координация между задачами может достигаться с помощью более упрощенного метода. Например, если нескольким экземплярам задач просто требуется координируемый доступ к общему ресурсу, то лучшим решением для управления доступом является использование оптимистической или пессимистической блокировки.
- Стороннее решение, например Apache Zookeeper , может быть более эффективным решением.
Проектирование рабочей нагрузки
Архитектор должен оценить, как шаблон выборов лидера можно использовать в проектировании рабочей нагрузки для решения целей и принципов, описанных в основных принципах Платформы Azure Well-Architected Framework. Например:
| Принцип | Как этот шаблон поддерживает цели основных компонентов |
|---|---|
| Решения по проектированию надежности помогают рабочей нагрузке стать устойчивой к сбоям и обеспечить восстановление до полнофункционального состояния после сбоя. | Этот шаблон снижает влияние сбоев узлов, надежно перенаправляя работу. Она также реализует отработку отказа с помощью алгоритмов консенсуса, когда лидер не работает. - ИЗБЫТОЧНОСТЬ RE:05 - RE:07 Самовосстановление |
Как и любое решение по проектированию, рассмотрите любые компромиссы по целям других столпов, которые могут быть представлены с этим шаблоном.
Пример
Пример выборов лидера на GitHub показывает, как использовать аренду для большого двоичного объекта служба хранилища Azure, чтобы обеспечить механизм реализации общего распределенного мьютекса. Этот мьютекс можно использовать для выбора лидера среди группы доступных рабочих экземпляров. Первый экземпляр для приобретения аренды выбирается лидером и остается лидером, пока он не выпустит аренду или не сможет продлить аренду. Другие рабочие экземпляры могут продолжать отслеживать аренду BLOB-объектов в случае, если лидер больше недоступен.
Аренда большого двоичного объекта — это блокировка на запись в большой двоичный объект. Один большой двоичный объект может быть субъектом только одной аренды в любой момент времени. Рабочий экземпляр может запрашивать аренду для указанного большого двоичного объекта, и он будет предоставлен в аренду, если другой рабочий экземпляр не содержит аренды над тем же большим двоичным объектом. В противном случае запрос вызовет исключение.
Чтобы избежать сбоя экземпляра лидера, сохраняющего аренду на неопределенный срок, укажите время существования аренды. По истечении этого срока аренда станет доступной. Однако в то время как экземпляр держит аренду, он может запросить продление аренды, и он будет предоставлен аренде в течение дополнительного периода времени. Экземпляр лидера может постоянно повторять этот процесс, если он хочет сохранить аренду. Дополнительные сведения об аренде большого двоичного объекта см. в статье Lease Blob (Аренда большого двоичного объекта).
Класс BlobDistributedMutex в приведенном ниже примере C# содержит RunTaskWhenMutexAcquired метод, позволяющий рабочему экземпляру пытаться получить аренду по указанному большому двоичному объекту. Сведения о большом двоичном объекте (имя, контейнер и учетная запись хранения) передаются в конструктор в объекте BlobSettings, когда создается объект BlobDistributedMutex (этот объект является простой структурой, включенной в пример кода). Конструктор также принимает Task код, который ссылается на код, который должен запускаться экземпляром рабочей роли, если он успешно получает аренду большого двоичного объекта и выбирается лидером. Обратите внимание, что код, который обрабатывает низкоуровневые сведения о получении аренды, реализован в отдельном вспомогательном классе BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Метод RunTaskWhenMutexAcquired в приведенном выше примере кода вызывает метод RunTaskWhenBlobLeaseAcquired, который показан в следующем примере кода. Это фактически и есть приобретение аренды. Метод RunTaskWhenBlobLeaseAcquired выполняется асинхронно. При успешном получении аренды рабочий экземпляр был избран лидером. Целью делегата taskToRunWhenLeaseAcquired является выполнение работы, которая координирует другие рабочие экземпляры. Если аренда не приобретена, другой рабочий экземпляр был избран в качестве лидера, а текущий экземпляр рабочей роли остается подчиненным. Обратите внимание, что TryAcquireLeaseOrWait — это вспомогательный метод, который использует объект BlobLeaseManager для получения аренды.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Задача, запускаемая лидером, также выполняется асинхронно. Пока выполняется эта задача, метод RunTaskWhenBlobLeaseAcquired, показанный в следующем примере кода, периодически пытается возобновить аренду. Это помогает гарантировать, что рабочий экземпляр остается лидером. В примере решения задержка между запросами на продление меньше времени, указанного в течение срока аренды, чтобы предотвратить выбор другого рабочего экземпляра лидера. Если продление завершается ошибкой по какой-либо причине, задача руководителя отменяется.
Если аренда не будет продлена или задача отменена (возможно, в результате завершения работы рабочего экземпляра), аренда будет освобождена. На этом этапе этот или другой рабочий экземпляр можно выбирать в качестве лидера. В приведенном ниже фрагменте кода показана эта часть процесса.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
KeepRenewingLease — это еще один вспомогательный метод, который использует объект BlobLeaseManager для возобновления аренды. Метод CancelAllWhenAnyCompletes отменяет задачи, указанные в качестве первых двух параметров. На следующей схеме показано, как с помощью класса BlobDistributedMutex выбирается лидер и запускается задача, которая координирует операции.
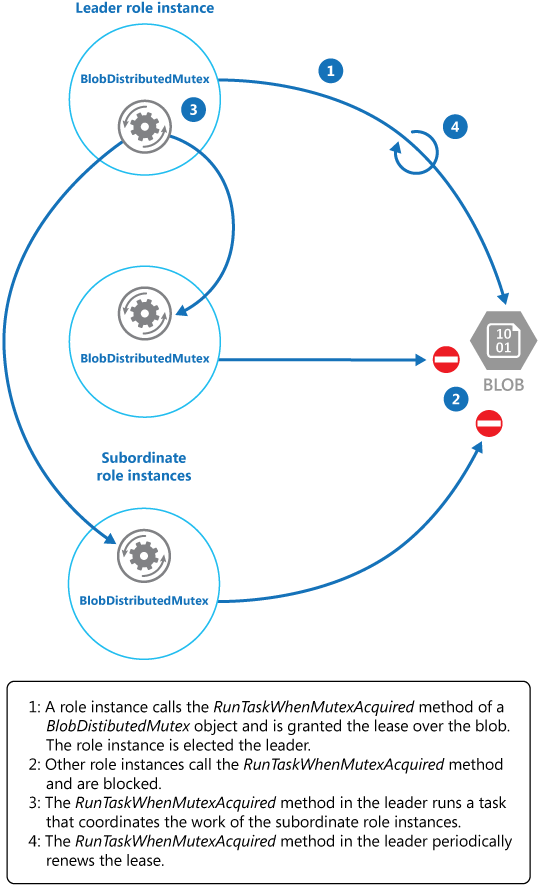
В следующем примере кода показано, как использовать BlobDistributedMutex класс в рабочем экземпляре. Этот код получает аренду большого двоичного объекта с именем MyLeaderCoordinatorTask в контейнере аренды Хранилище BLOB-объектов Azure, и указывает, что код, определенный в MyLeaderCoordinatorTask методе, должен выполняться, если рабочий экземпляр выбран лидером.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Обратите внимание на следующие аспекты, касающиеся примера решения:
- Большой двоичный объект — это потенциальная единая точка отказа. Если служба BLOB-объектов становится недоступной или недоступна, лидер не сможет продлить аренду, а другой рабочий экземпляр не сможет получить аренду. В этом случае экземпляр рабочей роли не сможет выступать в качестве лидера. Однако служба BLOB-объектов обладает отказоустойчивостью, поэтому полный сбой этой службы является крайне маловероятным.
- Если задача, выполняемая лидером, застопорится, лидер может продолжить продление аренды, не позволяя любому другому рабочему экземпляру получить аренду и взять на себя должность лидера для координации задач. В реальной среде работоспособность лидера должна проверяться достаточно часто.
- Процесс выбора является недетерминированным. Вы не можете сделать никаких предположений о том, какой рабочий экземпляр получит аренду BLOB-объекта и станет лидером.
- Большой двоичный объект, используемый в качестве целевого объекта аренды большого двоичного объекта, не должен использоваться ни для какой иной цели. Если рабочий экземпляр пытается хранить данные в этом большом двоичном объекте, эти данные не будут доступны, если экземпляр рабочей роли не является лидером и удерживает аренду BLOB-объектов.
Следующие шаги
При реализации этого шаблона следует принять во внимание следующие рекомендации:
- Этот шаблон содержит доступный для скачивания пример приложения.
- Руководство по автоматическому масштабированию. Существует возможность запускать и останавливать экземпляры узлов задач, так как нагрузка на приложение варьируется. Автомасштабирование может быть полезным для поддержания пропускной способности и производительности во время максимальной нагрузки.
- Асинхронный шаблон на основе задач.
- Пример, демонстрирующий алгоритм Bully.
- Пример, демонстрирующий алгоритм Ring.
- Apache Curator — клиентская библиотека для Apache ZooKeeper.
- Статья Lease Blob (Аренда большого двоичного объекта) на сайте MSDN.