Разбейте задачу, которая выполняет сложную обработку, на ряд отдельных элементов для повторного использования при необходимости. Это позволяет повысить производительность, масштабируемость и повторное использование начальных шагов, позволяя элементам задач, выполняющим обработку, развертываться и масштабироваться независимо. Шаблон каналов и фильтров поддерживает высокий уровень модульности.
Контекст и проблема
У вас есть конвейер последовательных задач, которые необходимо обработать. Простой, но негибкий подход к реализации этого приложения заключается в том, чтобы выполнить эту обработку в монолитном модуле. Однако этот подход, скорее всего, снижает возможности рефакторинга кода, оптимизации его или повторного использования, если части одной и той же обработки требуются в другом месте приложения.
На следующей схеме показана одна из проблем с обработкой данных с помощью монолитного подхода, неспособность повторно использовать код в нескольких конвейерах. В этом примере приложение получает и обрабатывает данные из двух источников. Отдельный модуль обрабатывает данные из каждого источника, выполняя ряд задач для преобразования данных перед передачей результата в бизнес-логику приложения.
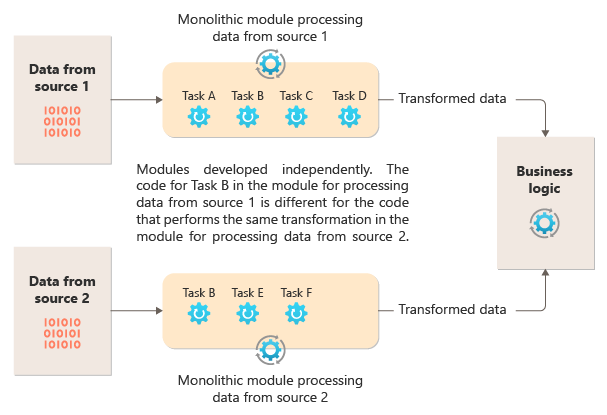
Некоторые задачи, выполняемые монолитными модулями, функционально похожи, но код должен повторяться в обоих модулях и, скорее всего, тесно связан с его модулем. Помимо невозможности повторного использования логики этот подход представляет риск при изменении требований. Необходимо помнить, чтобы обновить код в обоих местах.
Существуют другие проблемы с монолитной реализацией, не связанной с несколькими конвейерами или повторное использование. При монолите у вас нет возможности выполнять определенные задачи в разных средах или масштабировать их независимо. Некоторые задачи могут быть ресурсоемкими и могут воспользоваться запуском на мощном оборудовании или параллельном выполнении нескольких экземпляров. Другие задачи могут не иметь одинаковых требований. Кроме того, с монолитами сложно переупорядочение задач или внедрение новых задач в конвейер. Для этих изменений требуется повторное тестирование всего конвейера.
Решение
Разбейте процесс обработки, требуемый для каждого потока, на ряд отдельных компонентов (или фильтров), каждый из которых выполняет определенную задачу. Составные задачи должны использовать несколько фильтров, а не один. Фильтры создаются в конвейеры путем соединения фильтров с каналами. Фильтры являются независимыми, автономными и обычно без отслеживания состояния. Фильтры получают сообщения из входящего канала и публикуют сообщения в другом исходящем канале. Фильтры могут преобразовать сообщение или проверить его в одном или нескольких критериях, чтобы включить условную логику. Каналы не выполняют маршрутизацию или другую логику. Они подключаются только к фильтрам, передавая выходное сообщение из одного фильтра в качестве входных данных в следующий.
Фильтры действуют независимо и не знают о других фильтрах. Они знают только о своих входных и выходных схемах. Таким образом, фильтры можно упорядочить в любом порядке, пока входная схема для любого фильтра соответствует выходной схеме для предыдущего фильтра. Использование стандартизированной схемы для всех фильтров повышает возможность переупорядочения фильтров. Архитектура каналов и фильтров поощряет повторное использование композиции.
Свободное связывание фильтров упрощает следующие действия.
- Создание новых конвейеров, состоящих из существующих фильтров
- Обновление или замена логики в отдельных фильтрах
- При необходимости переупорядочение фильтров
- Выполнение фильтров на разных оборудованиях, где требуется
- Параллельное выполнение фильтров
На этой схеме показано решение, реализованное с помощью каналов и фильтров:
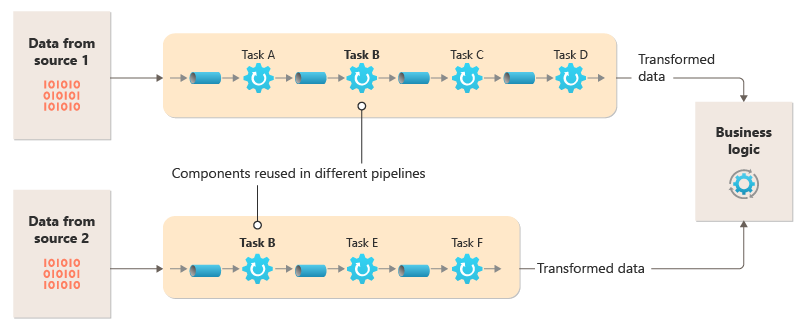
Время обработки одного запроса зависит от скорости самых медленных фильтров в конвейере. Один или несколько фильтров могут быть узкими местами, особенно если большое количество запросов отображается в потоке из определенного источника данных. Возможность запуска параллельных экземпляров медленных фильтров позволяет системе распределять нагрузку и улучшать пропускную способность.
Возможность запускать фильтры в разных вычислительных экземплярах позволяет масштабировать их независимо и использовать эластичность, которую обеспечивают многие облачные среды. Фильтр, который вычислительный ресурсоемкий, может работать на высокопроизводительном оборудовании, а другие менее требовательные фильтры могут размещаться на менее дорогих сырьевых оборудованиях. Фильтры даже не должны находиться в одном центре обработки данных или географическом расположении, что позволяет каждому элементу конвейера выполняться в среде, близкой к нужным ресурсам. Для этих усилий требуются определенные методы проектирования, такие как обмен сообщениями, многопоточное использование и т. д. для максимальной эластичности каждого канала или фильтра. На этой схеме показан пример, примененный к конвейеру для данных из источника 1:
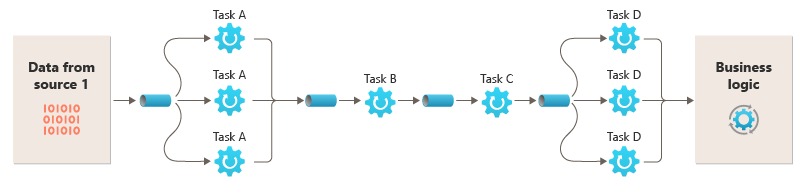
Если входные и выходные данные фильтра структурированы как поток, вы можете выполнять обработку для каждого фильтра параллельно. Первый фильтр в конвейере может начать работу и вывести результаты, которые передаются непосредственно следующему фильтру в последовательности, прежде чем первый фильтр завершит работу.
Использование шаблона каналов и фильтров вместе с шаблоном компенсирующих транзакций является альтернативным подходом к реализации распределенных транзакций. Вы можете разбить распределенную транзакцию на отдельные, компенсированные задачи, каждая из которых может быть реализована с помощью фильтра, который также реализует шаблон компенсирующей транзакции. Фильтры можно реализовать в конвейере в виде отдельных размещенных задач, которые выполняются близко к данным, которые они поддерживают.
Проблемы и рекомендации
Рассмотрим следующие моменты, когда вы решите, как реализовать этот шаблон:
Монолитный характер. Обычно этот шаблон реализуется в виде монолитного конвейера, поэтому для любого изменения вся цепочка фильтров должна быть проверена в конце. Кроме того, необходимо учитывать отказоустойчивость всего процесса; Если фильтр или канал завершается сбоем, весь конвейер, скорее всего, завершится ошибкой.
Сложность. Повышенная гибкость, которую обеспечивает этот шаблон, может также вызвать сложности, особенно если фильтры в конвейере распределяются между разными серверами.
Надежность. Используйте инфраструктуру, которая гарантирует, что поток данных между фильтрами в канале не теряется.
Идемпотентность. Если фильтр в конвейере завершается сбоем после получения сообщения, а работа перепланирована на другой экземпляр фильтра, часть работы может быть завершена. Если работа обновляет некоторые аспекты глобального состояния (например, сведения, хранящиеся в базе данных), одно обновление может повторяться. Аналогичная проблема может возникнуть, если фильтр завершается сбоем после публикации результатов в следующий фильтр, но до того, как он указывает, что он успешно завершил свою работу. В таких случаях другой экземпляр фильтра может повторить эту работу, что приводит к тому, что те же результаты будут размещены дважды. Этот сценарий может привести к последующим фильтрам в конвейере, обрабатывая одни и те же данные дважды. Таким образом, фильтры в конвейере должны быть разработаны для идемпотента. Дополнительные сведения см . в блоге Idempotency Patterns на блоге Джонатана Оливера.
Повторяющиеся сообщения. Если фильтр в конвейере завершается сбоем после того, как он отправляет сообщение на следующий этап конвейера, может быть запущен другой экземпляр фильтра, и он будет публиковать копию того же сообщения в конвейер. Этот сценарий может привести к передаче двух экземпляров одного сообщения следующему фильтру. Чтобы избежать этой проблемы, конвейер должен обнаруживать и устранять повторяющиеся сообщения.
Примечание.
Если конвейер реализуется с помощью очередей сообщений (например, Служебная шина Azure очередей), инфраструктура очереди сообщений может обеспечить автоматическое обнаружение и удаление повторяющихся сообщений.
Контекст и состояние. В конвейере каждый фильтр по сути выполняется изолированно. Способ его вызова не должен вызывать предположения. Таким образом, каждый фильтр должен быть предоставлен с достаточным контекстом для выполнения своей работы. Этот контекст может включать значительный объем сведений о состоянии. Если фильтры используют внешнее состояние, например данные в базе данных или внешнем хранилище, необходимо учитывать влияние на производительность. Каждый фильтр должен загружать, работать и сохранять это состояние, что добавляет затраты на решения, которые загружают внешнее состояние за один раз.
Допустимое сообщение. Фильтры должны быть терпимыми к данным в входящего сообщения, с которыми они не работают. Они работают с данными, соответствующими им, и игнорируют другие данные и передают их без изменений в выходном сообщении.
Обработка ошибок . Каждый фильтр должен определить, что делать в случае критической ошибки. Фильтр должен определить, завершается ли сбой конвейера или распространяет исключение.
Когда следует использовать этот шаблон
Используйте этот шаблон в следующих случаях:
Процесс обработки, требуемый приложением, можно легко разделить на ряд независимых этапов.
У этапов обработки, которые выполняются приложением, разные требования к масштабируемости.
Примечание.
Вы можете группировать фильтры, которые должны масштабироваться вместе в одном процессе. Дополнительные сведения см. в описании шаблона консолидации вычислительных ресурсов.
Вам требуется гибкость, чтобы разрешить переупорядочение шагов обработки, которые выполняет приложение, или разрешить возможность добавлять и удалять шаги.
Система будет работать эффективнее, если распределить шаги обработки между несколькими серверами.
Необходимо надежное решение, которое свести к минимуму последствия сбоя на шаге во время обработки данных.
Этот шаблон может оказаться неэффективным в следующих случаях:
Приложение следует шаблону ответа на запрос.
Обработка задач должна быть завершена как часть первоначального запроса, например сценария запроса или ответа.
Шаги обработки, выполняемые приложением, не являются независимыми, или они должны выполняться вместе в рамках одной транзакции.
Объем контекста или сведений о состоянии, который требуется шагу, делает этот подход неэффективным. Возможно, вы сможете сохранить сведения о состоянии в базе данных, но не используйте эту стратегию, если дополнительная нагрузка на базу данных приводит к чрезмерному конфликту.
Проектирование рабочей нагрузки
Архитектор должен оценить, как шаблон каналов и фильтров можно использовать в проектировании рабочей нагрузки для решения целей и принципов, описанных в основных принципах платформы Azure Well-Architected Framework. Например:
| Принцип | Как этот шаблон поддерживает цели основных компонентов |
|---|---|
| Решения по проектированию надежности помогают рабочей нагрузке стать устойчивой к сбоям и обеспечить восстановление до полнофункционального состояния после сбоя. | Отдельная ответственность каждого этапа позволяет сосредоточить внимание и избежать отвлекающих факторов при обработке данных. - Простота RE:01 - Задания RE:07 Фоновые задания |
Как и любое решение по проектированию, рассмотрите любые компромиссы по целям других столпов, которые могут быть представлены с этим шаблоном.
Пример
Чтобы предоставить инфраструктуру, необходимую для реализации конвейера, можно использовать последовательность очередей сообщений. Начальная очередь сообщений получает необработанные сообщения, которые становятся началом реализации каналов и фильтров. Компонент, реализованный как задача фильтра, прослушивает сообщение в этой очереди, выполняет свою работу, а затем отправляет новое или преобразованное сообщение в следующую очередь в последовательности. Другая задача фильтра может прослушивать сообщения в этой очереди, обрабатывать их, публиковать результаты в другую очередь и т. д., пока не завершится процесс каналов и фильтров. На этой схеме показан конвейер, использующий очереди сообщений:

Конвейер обработки изображений можно реализовать с помощью этого шаблона. Если рабочая нагрузка принимает образ, образ может пройти через ряд в значительной степени независимых и переупорядоченных фильтров для выполнения таких действий, как:
- Модерация контента
- изменение размера
- Водяных знаков
- переориентация
- Удаление метаданных exif
- Публикация сети доставки содержимого (CDN)
В этом примере фильтры можно реализовать как отдельные развернутые Функции Azure или даже одно приложение-функцию Azure, содержащее каждый фильтр в виде изолированного развертывания. Использование триггеров функций Azure, входных привязок и выходных привязок может упростить код фильтра и автоматически работать с конвейером на основе очередей с помощью проверки утверждения для обработки изображения.

Ниже приведен пример того, что один фильтр, реализованный как функция Azure, активируется из канала хранилища очередей с проверкой утверждения на изображение, и запись новой проверки утверждения в другой канал хранилища очередей может выглядеть следующим образом. Мы заменили реализацию псевдокодом в комментариях для краткости. Более похожий код можно найти в демонстрации шаблона каналов и фильтров, доступных на сайте GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Примечание.
Платформа Spring Integration Framework реализует шаблон каналов и фильтров.
Следующие шаги
При реализации этого шаблона могут оказаться полезными следующие ресурсы:
- Демонстрация шаблона каналов и фильтров с помощью сценария обработки изображений доступна на сайте GitHub.
- Шаблоны Идемпотентности, на блоге Джонатана Оливера.
Связанные ресурсы
При реализации этого шаблона могут быть также важны следующие шаблоны:
- Шаблон проверки утверждений. Конвейер, реализованный с помощью очереди, может не содержать фактический элемент, отправляемый через фильтры, а указатель на данные, которые необходимо обработать. В этом примере используется проверка утверждений в хранилище очередей Azure для образов, хранящихся в Хранилище BLOB-объектов Azure.
- Шаблон конкурирующих потребителей. Конвейер может содержать несколько экземпляров одного или нескольких фильтров. Этот подход полезен для запуска параллельных экземпляров медленных фильтров. Она позволяет системе распределять нагрузку и улучшать пропускную способность. Каждый экземпляр фильтра конкурирует за входные данные с другими экземплярами, но два экземпляра фильтра не должны обрабатывать одни и те же данные. В этой статье объясняется подход.
- Шаблон консолидации вычислительных ресурсов. Возможно, можно группировать фильтры, которые должны масштабироваться в один процесс. В этой статье содержатся дополнительные сведения о преимуществах и компромиссах этой стратегии.
- Шаблон компенсирующих транзакций. Вы можете реализовать фильтр как операцию, которая может быть отменена или имеет компенсирующую операцию, которая восстанавливает состояние до предыдущей версии, если произошел сбой. В этой статье объясняется, как реализовать этот шаблон для поддержания или достижения конечной согласованности.
- Каналы и фильтры — шаблоны интеграции enterprise.