Управление файловым пространством для баз данных в базе данных Azure SQL Database
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
В этой статье описываются различные типы пространства хранилища для баз данных в Базе данных SQL Azure, а также действия, которые можно предпринять, если необходимо явно управлять выделенным файловым пространством.
Обзор
При База данных SQL Azure существуют шаблоны рабочих нагрузок, в которых выделение базовых файлов данных для баз данных может превышать количество используемых страниц данных. Это условие может возникать при увеличении объема пространства и удалении данных. Это объясняется тем, что выделенное файловое пространство автоматически не освобождается.
Мониторинг использования файлового пространства и сжатие файлов базы данных может потребоваться в следующих сценариях:
- предоставление места для роста данных в эластичном пуле, когда файловое пространство, выделенное для баз данных, достигает максимального размера пула;
- уменьшение максимального размера отдельной базы данных или эластичного пула;
- изменение уровня служб или производительности отдельной базы данных или эластичного пула с меньшим максимальным размером.
Примечание.
Операции сжатия не следует рассматривать как обычную операцию обслуживания. Файлы данных и журналов, увеличивающиеся из-за регулярных, повторяющихся бизнес-операций, не нуждаются в операциях сжатия.
Мониторинг использования пространства файлов
Большинство метрик дискового пространства, отображаемых в следующих API-интерфейсах измеряют только размер используемых страниц данных:
- API метрик на основе Azure Resource Manager, включая PowerShell get-metrics.
Тем не менее следующие API-интерфейсы также измеряют размер пространства, выделяемого для баз данных и эластичных пулов:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats.
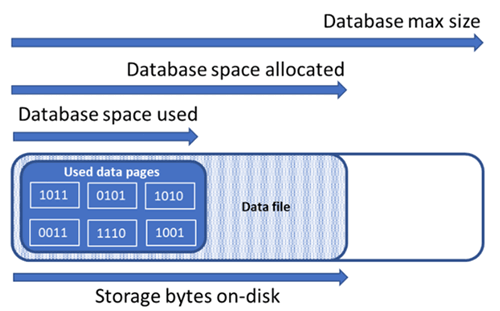
Общие сведения о типах дискового пространства для базы данных
Для управления файловым пространством базы данных важно разобраться со следующими объемами дискового пространства.
| Объем пространства базы данных | Определение | Комментарии |
|---|---|---|
| Место, занятое данными | Объем пространства, используемого для хранения данных базы данных. | Как правило, используемое пространство увеличивается (уменьшается) при операциях вставки (удаления). В некоторых случаях используемое пространство остается неизменным при операциях вставки или удаления в зависимости от объема и шаблона данных, участвующих в операции и фрагментации. Например, удаление одной строки на каждой странице данных не обязательно приведет к уменьшению используемого пространства. |
| Выделенное пространство данных | Объем форматированного файлового пространства, который стал доступным для хранения данных базы данных. | Объем выделенного пространства увеличивается автоматически, но никогда не уменьшается после удалений. Такое поведение гарантирует, что будущие вставки выполняются быстрее, так как пространство не нуждается в переформатировании. |
| Выделенное, но неиспользуемое пространство данных | Разница между объемом выделенного и используемого пространства данных. | Это количество представляет максимальный объем свободного пространства, которое можно освободить путем сжатия файлов данных базы данных. |
| Максимальный размер данных | Максимальный объем пространства, который можно использовать для хранения данных базы данных. | Объем выделенного пространства данных не может превышать максимальный размер данных. |
На следующей схеме показана связь между разными типами дискового пространства для базы данных.
Запрос одной базы данных для сведений о пространстве файлов
Используйте следующий запрос на sys.database_files , чтобы вернуть объем выделенного места в файле базы данных и объем неиспользуемого пространства. Единицы результатов запроса указываются в МБ.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Общие сведения о типах дискового пространства для эластичного пула
Для управления файловым пространством эластичного пула важно разобраться со следующими объемами дискового пространства.
| Объем пространства эластичных пулов | Определение | Комментарии |
|---|---|---|
| Место, занятое данными | Общий объем пространства данных, используемого всеми базами данных в эластичном пуле. | |
| Выделенное пространство данных | Общий объем пространства данных, выделенного всеми базами данных в эластичном пуле. | |
| Выделенное, но неиспользуемое пространство данных | Разница между объемом выделенного пространства данных и пространства данных, используемого всеми базами данных в эластичном пуле. | Это количество представляет максимальный объем выделенного для эластичного пула пространства, которое можно освободить путем сжатия файлов данных базы данных. |
| Максимальный размер данных | Максимальный объем пространства данных, который эластичный пул может использовать для всех своих баз данных. | Выделенное для эластичного пула пространство не должно превышать максимальный размер эластичного пула. В этом случае выделенное неиспользуемое пространство можно освободить путем сжатия файлов данных базы данных. |
Примечание.
Сообщение об ошибке "Эластичные пулы достигло предела хранилища" указывает, что объекты базы данных были выделены достаточно места для удовлетворения ограничения хранилища эластичного пула, но в выделении пространства данных может быть неиспользуемое пространство. Рассмотрите возможность увеличения предельного объема хранилища эластичного пула или в качестве краткосрочного решения, освобождая пространство данных с помощью примеров в неиспользуемом выделенном пространстве. Кроме того, следует учитывать потенциальное негативное влияние на производительность сжатия файлов базы данных, см. раздел "Обслуживание индекса" после сжатия.
Запрос эластичного пула для получения сведений о дисковом пространстве
Следующие запросы можно использовать для определения объема дискового пространства для эластичного пула.
Используемое пространство данных эластичного пула
Измените следующий запрос, чтобы получить объем пространства, занятого данными эластичного пула. Единицы результатов запроса указываются в МБ.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Выделенное пространство данных эластичного пула и неиспользуемое выделенное пространство
Измените следующие примеры, чтобы получить таблицу, в которой перечислено выделенное пространство и неиспользуемое выделенное пространство для каждой базы данных в эластичном пуле. Таблица сортирует базы данных по объему неиспользованного выделенного пространства от наибольших к наименьшим. Единицы результатов запроса указываются в МБ.
Результаты запроса для определения выделенного пространства для каждой базы данных в пуле могут суммироваться для представления общего пространства, выделенного для эластичного пула. Выделенное пространство эластичного пула не должно превышать максимальный размер эластичного пула.
Внимание
Модуль PowerShell Azure Resource Manager по-прежнему поддерживается базой данных SQL Azure, но вся будущая разработка сосредоточена на модуле Az.Sql. Исправления ошибок для модуля AzureRM будут продолжать выпускаться как минимум до декабря 2020 г. Аргументы команд в модулях Az и AzureRm практически идентичны. Дополнительные сведения о совместимости см. в статье Знакомство с новым модулем Az для Azure PowerShell.
Сценарию PowerShell требуется модуль SQL Server PowerShell. Дополнительные сведения см. в разделе Установка модуля SQL Server PowerShell.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
В качестве примера выходных данных скрипта приведен следующий снимок экрана:

Максимальный размер данных эластичного пула
Измените следующий запрос T-SQL, чтобы получить максимальный размер данных последнего записанного эластичного пула. Единицы результатов запроса указываются в МБ.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Освобождение неиспользуемого выделенного пространства
Внимание
Команды сжатия могут повлиять на производительность базы данных во время выполнения, поэтому по возможности их следует выполнять в периоды низкого уровня использования.
Сжатие файлов данных
Из-за потенциального воздействия на производительность базы данных База данных SQL Azure не сжимает файлы данных автоматически. Однако клиенты могут сжимать файлы данных через самообслуживание во время выбора. Это не должно быть запланированной регулярной операцией, а скорее одноразовым событием в ответ на значительное сокращение объема пространства, доступного для использования в файле данных.
Совет
Не рекомендуется сжимать файлы данных, если из-за обычной рабочей нагрузки приложения файлы снова будут увеличиваться до того же выделенного размера.
В Базе данных SQL Azure для сжатия файлов можно использовать команду DBCC SHRINKDATABASE или DBCC SHRINKFILE.
DBCC SHRINKDATABASEСжимает все файлы данных и журналов в базе данных с помощью одной команды. Команда сжимает по одному файлу данных за раз, что может занять много времени для больших баз данных. Она также сжимает файл журнала, что обычно не требуется, так как База данных SQL Azure автоматически сжимает файлы журнала по мере необходимости.DBCC SHRINKFILEкоманда поддерживает более сложные сценарии:- При необходимости она может применяться к отдельным файлам, а не для сжатия всех файлов в базе данных.
- Каждая команда
DBCC SHRINKFILEможет выполняться параллельно с другими командамиDBCC SHRINKFILEдля одновременного сжатия нескольких файлов и сокращения общего времени сжатия за счет более эффективного использования ресурсов и более высокой вероятности блокировки пользовательских запросов, если они выполняются во время сжатия.- Сжатие нескольких файлов данных одновременно позволяет ускорить операцию сжатия. При использовании параллельного сжатия файлов данных может наблюдаться временная блокировка одного запроса сжатия по другому.
- Если заключительный фрагмент файла не содержит данных, уменьшение размера выделенного файла можно существенно ускорить, указав аргумент
TRUNCATEONLY. Это не требует перемещения данных в файле.
- Дополнительные сведения об этих командах сжатия см. в статьях DBCC SHRINKDATABASE и DBCC SHRINKFILE.
- Операции сжатия баз данных и файлов поддерживаются в предварительной версии для гипермасштабирования База данных SQL Azure. Дополнительные сведения см. в разделе "Сжатие" для База данных SQL Azure гипермасштабирования.
Следующие примеры необходимо выполнить при подключении к целевой базе данных пользователя, а не к базе данных master.
Для использования DBCC SHRINKDATABASE для сжатия всех файлов данных и журналов в заданной базе данных, воспользуйтесь следующей командой:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
В База данных SQL Azure база данных может иметь один или несколько файлов данных, созданных автоматически по мере роста данных. Чтобы определить структуру файлов вашей базы данных, включая используемый и выделенный размер каждого файла, запросите представление каталога sys.database_files, используя следующий пример скрипта.
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Вы можете выполнить сжатие только для одного файла с помощью команды DBCC SHRINKFILE, например:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Обратите внимание на потенциальное негативное влияние на производительность сжатия файлов базы данных, см. раздел "Обслуживание индекса" после сжатия.
Сжатие файла журнала транзакций
В отличие от файлов данных, база данных Azure SQL автоматически сжимает файл журнала транзакций во избежание чрезмерного использования пространства, которое может привести к ошибкам нехватки места. Обычно пользователям нет необходимости сжимать файл журнала транзакций.
В уровнях служб premium и критически важный для бизнеса, если журнал транзакций становится большим, он может значительно способствовать использованию локального хранилища в направлении максимального ограничения локального хранилища. Если потребление локального хранилища близко к ограничению, клиенты могут выбрать сжатие журнала транзакций с помощью команды DBCC SHRINKFILE , как показано в следующем примере. Локальное хранилище освобождается сразу после завершения команды, не дожидаясь периодической операции автоматического сжатия.
Следующий пример должен выполняться при подключении к целевой пользовательской базе данных, а не master к базе данных.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Автоматическое сжатие
В качестве альтернативы сжатию файлов данных вручную можно включить автоматическое сжатие для базы данных. Однако автоматическое сжатие может быть менее эффективным при восстановлении файлового пространства, чем операции DBCC SHRINKDATABASE и DBCC SHRINKFILE.
По умолчанию автоматическое сжатие отключено, что рекомендуется для большинства баз данных. Если необходимо включить автоматическое сжатие, рекомендуется отключить его после достижения целей управления пространством, а не постоянного включения. Дополнительные сведения см. в разделе Рекомендации для AUTO_SHRINK.
Например, автоматическое сжатие может быть полезно в конкретном сценарии, когда эластичный пул содержит множество баз данных со значительным увеличением и сокращением используемого пространства файлов данных, в результате чего размер пула приближается к максимальному. Это довольно редкий сценарий.
Чтобы включить автоматическое сжатие, выполните следующую команду при подключении master к базе данных (а не базе данных).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Дополнительные сведения об этой команде см. в статье Параметры ALTER DATABASE SET (Transact-SQL).
Обслуживание индекса после сокращения
После завершения операции сжатия в файлах данных индексы могут быть фрагментированы. Это снижает их эффективность оптимизации производительности для определенных рабочих нагрузок, таких как запросы с использованием масштабного сканирования. Если снижение производительности происходит после завершения операции сжатия, рассмотрите возможность обслуживания индекса для перестроения индексов. Имейте в виду, что перестроение индекса требует свободного места в базе данных, поэтому может привести к увеличению выделенного пространства, противодействуя эффекту сжатия.
Дополнительные сведения об обслуживании индексов см. в статье Оптимизация обслуживания индексов для повышения производительности запросов и снижения потребления ресурсов.
Сжатие больших баз данных
Если выделенное пространство базы данных находится в сотнях гигабайтов или выше, сжатие может потребовать значительного времени для завершения, часто измеряемого в часах или днях для многотерабайтовых баз данных. Существуют методы оптимизации процесса и рекомендации, которые можно использовать, чтобы сделать этот процесс более эффективным и менее влияющим на рабочие нагрузки приложений.
Фиксация базовых показателей использования пространства
Перед началом сжатия зафиксируйте текущее используемое и выделенное пространство в каждом файле базы данных, выполнив следующий запрос на использование пространства:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
После завершения сжатия вы можете снова выполнить этот запрос и сравнить результат с исходными базовыми показателями.
Усечение файлов данных
Рекомендуется сначала выполнить сжатие для каждого файла данных с использованием параметра TRUNCATEONLY. Таким образом, если в конце файла выделено, но неиспользуемое пространство, оно удаляется быстро и без перемещения данных. Следующий пример команды усекает файл данных с идентификатором file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
После выполнения этой команды для каждого файла данных вы можете повторно выполнить запрос на использование пространства, чтобы узнать, сокращено ли выделенное пространство. Вы также можете просмотреть выделенное пространство для базы данных на портале Azure.
Определение плотности страницы индекса
Если усечение файлов данных не привело к достаточному сокращению выделенного пространства, вам потребуется сжать файлы данных. Но в качестве необязательного, но рекомендуемого шага сначала следует определить среднюю плотность страниц для индексов в базе данных. Для того же объема данных сжатие будет выполняться быстрее, если плотность страницы высокая, так как придется перемещать меньше страниц. Если плотность страниц для некоторых индексов низкая, рассмотрите возможность выполнения обслуживания этих индексов, чтобы повысить плотность страниц, прежде чем сжимать файлы данных. Это также позволит сократить выделенное дисковое пространство.
Чтобы определить плотность страниц для всех индексов в базе данных, используйте следующий запрос. Плотность страницы указывается в столбце avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Если есть индексы с большим количеством страниц, плотность страниц которых ниже 60–70 %, рассмотрите возможность перестроения или реорганизации этих индексов перед сжатием файлов данных.
Примечание.
Для больших баз данных запрос для определения плотности страниц может занять длительное время (часы). Кроме того, перестроение или реорганизация больших индексов также требует значительных затрат времени и ресурсов. Существует компромисс между дополнительными временными затратами на увеличение плотности страницы с одной стороны и сокращением продолжительности сжатия и достижением большей экономии места с другой.
Если есть несколько индексов с низкой плотностью страниц, вы можете перестроить их параллельно на нескольких сеансах базы данных, чтобы ускорить процесс. Однако убедитесь, что вы не приближаетесь к ограничениям ресурсов базы данных, и оставьте достаточное количество ресурсов для рабочих нагрузок приложений, которые могут выполняться. Отслеживайте потребление ресурсов (ЦП, ввод-вывод данных, ввод-вывод журнала) на портале Azure или с помощью представления sys.dm_db_resource_stats и запускайте дополнительные параллельные перестроения, только если использование ресурсов по каждому из этих измерений остается существенно ниже 100 %. Если загрузка ЦП, а также показатели ввода-вывода данных или ввода-вывода журнала составляет 100 %, вы можете масштабировать базу данных, чтобы иметь больше ядер ЦП и увеличить пропускную способность ввода-вывода. Это может привести к более быстрому выполнению дополнительных параллельных перестроек.
Пример команды перестроения индекса
Ниже приведен пример команды для перестроения индекса и увеличения плотности страницы с помощью инструкции ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Эта команда инициирует возобновляемое перестроение индекса в подключенном режиме. Это позволяет выполняемым одновременно рабочим нагрузкам продолжать использовать таблицу, пока выполняется перестроение, а также возобновить перестроение, если оно по какой-либо причине было прервано. Но такой тип перестроения медленнее автономного перестроения, которое блокирует доступ к таблице. Если другим рабочим нагрузкам не требуется доступ к таблице во время перестроения, задайте для параметров ONLINE и RESUMABLE значение OFF и удалите предложение WAIT_AT_LOW_PRIORITY.
Дополнительные сведения об обслуживании индексов см. в статье Оптимизация обслуживания индексов для повышения производительности запросов и снижения потребления ресурсов.
Сжатие нескольких файлов данных
Как отмечалось ранее, сжатие при перемещении данных — это длительный процесс. Если в базе данных есть несколько файлов данных, вы можете ускорить процесс, сжав несколько файлов данных параллельно. Для этого откройте несколько сеансов базы данных и используйте DBCC SHRINKFILE для каждого сеанса с разными значениями file_id. Как и при перестроении индексов (см. выше), перед запуском каждой новой команды параллельного сжатия убедитесь, что у вас достаточно ресурсов (ЦП, ввод-вывод данных, ввод-вывод журнала).
Следующая пример команды сжимает файл данных с file_id 4, пытаясь уменьшить размер выделенного файла до 52 000 МБ, переместив страницы в файле:
DBCC SHRINKFILE (4, 52000);
Если вы хотите уменьшить выделенное пространство для файла до минимально возможного, выполните оператор без указания целевого размера.
DBCC SHRINKFILE (4);
Если рабочая нагрузка выполняется одновременно с сжатием, она может начать использовать место хранения, освобожденное путем сжатия, прежде чем сжатие завершится и усечен файл. В таком случае сжатие не сможет уменьшить выделенное пространство до указанного целевого значения.
Вы можете устранить эту проблему, сжимая каждый файл небольшими порциями. Это означает, что в команде DBCC SHRINKFILE вы задаете целевое значение, которое немного меньше, чем текущее выделенное пространство для файла, как видно из результатов запроса на базовое использование пространства. Например, если выделенное пространство для файла с идентификатором file_id 4 составляет 200 000 МБ, и вы хотите уменьшить его до 100 000 МБ, вы можете сначала задать целевое значение 170 000 МБ.
DBCC SHRINKFILE (4, 170000);
После выполнения этой команды файл будет усечен, а его выделенный размер уменьшится до 170 000 МБ. Затем вы можете повторить эту команду, задавая целевое значение 140 000 МБ, затем 110 000 МБ и т. д., пока файл не будет сжат до нужного размера. Если команда выполняется, а файл не сжимается, используйте меньшие шаги, например 15 000 МБ, а не 30 000 МБ.
Чтобы отслеживать ход сжатия для всех одновременно запущенных сеансов сжатия, вы можете использовать следующий запрос.
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Примечание.
Ход сжатия может быть нелинейным, и значение в percent_complete столбце может оставаться практически неизменным в течение длительного периода времени, даже если сжатие по-прежнему выполняется.
После завершения сжатия для всех файлов данных повторно выполните запрос на использование пространства (или проверьте это значение на портале Azure), чтобы определить результирующее уменьшение размера выделенного хранилища. Если между используемым пространством и выделенным пространством по-прежнему существует большое различие, можно перестроить индексы , как описано ранее. Это может временно увеличить выделенное пространство дальше, однако сжатие файлов данных снова после перестроения индексов должно привести к более глубокому сокращению выделенного пространства.
Временные ошибки во время сжатия
Иногда команда сжатия может завершиться ошибкой с различными ошибками, такими как время ожидания и взаимоблокировки. Как правило, эти ошибки являются временными и не повторяются, если выполнение этой команды повторить. Если сжатие завершается с ошибкой, прогресс, достигнутый в перемещении страниц данных, сохраняется, и та же самая команда сжатия может быть выполнена снова, чтобы продолжить сжатие файла.
В следующем примере скрипта показано, как можно запустить сжатие в цикле повторных попыток, чтобы автоматически повторять попытки до настраиваемого количества раз при возникновении ошибки истечения времени ожидания или взаимоблокировок. Этот подход к повторным попыткам применим ко многим другим ошибкам, которые могут возникать во время сжатия.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Помимо тайм-аутов и взаимоблокировок, сжатие может столкнуться с ошибками из-за некоторых известных проблем.
Возвращаемые ошибки и шаги по их устранению:
- Номер ошибки: 49503, сообщение об ошибке: %.*ls: не удалось переместить страницу %d:%d, так как это страница постоянного хранилища версий с внестрочными данными. Причина задержки страницы: %ls. Метка времени задержки страницы: %I64d.
Эта ошибка возникает при длительном выполнении активных транзакций, создавших версии строк в постоянном хранилище версий (PVS). Страницы, содержащие эти версии строк, не могут быть перемещены сжатием, поэтому операция завершается с этой ошибкой.
Чтобы избежать этого, вам нужно дождаться завершения этих длительных транзакций. Кроме того, можно определить и завершить эти длительные транзакции, но это может повлиять на приложение, если оно не обрабатывает ошибки транзакций корректно. Один из способов найти длительные транзакции — выполнить следующий запрос в базе данных, где вы выполнили команду сжатия.
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Вы можете завершить транзакцию, используя команду KILL и указав соответствующее значение session_id из результата запроса.
KILL 4242; -- replace 4242 with the session_id value from query results
Внимание
Завершение транзакции может негативно повлиять на рабочие нагрузки.
После того, как длительные транзакции будут прерваны или завершены, внутренняя фоновая задача через некоторое время удалит ненужные версии строк. Вы можете контролировать размер PVS, чтобы оценить ход очистки, используя следующий запрос. Запустите запрос в базе данных, где вы выполнили команду сжатия.
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Как только размер PVS, указанный в столбце persistent_version_store_size_gb, существенно уменьшится по сравнению с его первоначальным размером, повторное сжатие должно завершиться успешно.
- Номер ошибки: 5223, сообщение об ошибке: %.*ls: не удается освободить пустую страницу %d:%d.
Эта ошибка может возникать, если существуют текущие операции обслуживания индекса, например ALTER INDEX. Повторите команду сжатия после завершения этих операций.
Если эта ошибка повторится, возможно, потребуется перестроить связанный индекс. Чтобы найти индекс для перестроения, выполните следующий запрос в той же базе данных, где вы запускали команду сжатия.
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Перед выполнением этого запроса замените заполнители <file_id> и <page_id> фактическими значениями из полученного вами сообщения об ошибке. Например, если сообщение — Не удается освободить пустую страницу 1:62669, тогда значение <file_id> равно 1, а значение <page_id> равно 62669.
Перестройте индекс, определенный запросом, и повторите команду сжатия.
- Номер ошибки: 5201, сообщение об ошибке: DBCC SHRINKDATABASE: файл с идентификатором %d базы данных с идентификатором %d был пропущен, так как в нем недостаточно свободного места для освобождения.
Эта ошибка означает, что файл данных не может быть сжат дальше. Вы можете перейти к следующему файлу данных.
Связанный контент
Сведения о максимальных размерах базы данных см. в статьях:
- Ограничения ресурсов для отдельной базы данных в Базе данных SQL Azure при использовании модели приобретения на основе виртуальных ядер
- Ограничения ресурсов для одиночных баз данных в модели приобретения на основе единиц DTU
- Ограничения для эластичных пулов в службе "База данных SQL Azure" в рамках модели приобретения на основе виртуальных ядер
- Ограничения ресурсов для эластичных пулов в модели приобретения на основе единиц DTU