Секционирование в Azure Cosmos DB для Apache Cassandra
Область применения: ![]() Кассандра
Кассандра
В этой статье описывается, как работает секционирование в Azure Cosmos DB для Apache Cassandra.
API для Cassandra использует секционирование для масштабирования отдельных таблиц в пространстве ключей для удовлетворения потребностей в производительности приложения. Секции формируются на основе значения ключа секции, связанного с каждой записью таблицы. Все записи в секции используют одинаковое значение ключа секции. Azure Cosmos DB автоматически и прозрачно управляет размещением секций в физических ресурсах, чтобы эффективно удовлетворять требования к масштабируемости и производительности таблицы. По мере того, как растут требования приложения к пропускной способности и хранению, Azure Cosmos DB перемещает и распределяет данные между большим числом физических компьютеров.
С точки зрения разработчика секционирование ведет себя так же, как и для Azure Cosmos DB для Apache Cassandra, как и в собственном Apache Cassandra. однако есть некоторые неявные различия.
Различия между Apache Cassandra и Azure Cosmos DB
В Azure Cosmos DB каждая машина, на которой хранятся секции, сама по себе называется физической секцией. Физическая секция — это аналог виртуальной машины: выделенная единица вычислений или набор физических ресурсов. Каждая секция, хранящаяся в этой единице вычислений, называется логической секцией в Azure Cosmos DB. Если вы уже знакомы с Apache Cassandra, логические секции можно рассматривать так же, как и обычные секции в Cassandra.
Apache Cassandra рекомендует ограничение в 100 МБ на размер данных, которые могут храниться в секции. API cassandra для Azure Cosmos DB позволяет до 20 ГБ на логическую секцию и до 30 ГБ данных на физическую секцию. В Azure Cosmos DB, в отличие от Apache Cassandra, объем вычислений, доступный в физической секции, выражается с помощью одной метрики единиц запросов, которая позволяет воспринимать рабочую нагрузку с точки зрения запросов (операций чтения или записи) в секунду, а не ядер, памяти или операций ввода-вывода. Это помогает оптимизировать планирование ресурсов, так как вы понимаете стоимость каждого запроса. У каждой физической секции может быть до 10000 доступных единиц запроса. Дополнительные сведения о вариантах масштабируемости см. в статье по эластичному масштабированию в API для Cassandra.
В Azure Cosmos DB каждая физическая секция состоит из набора реплик, в который входит не менее четырех реплик. В этом отличие от Apache Cassandra, где можно настроить коэффициент репликации, равный 1. Однако это снизит уровень доступности, если единственный узел с данными выйдет из строя. В API для Cassandra всегда существует коэффициент репликации 4 (кворум 3). Azure Cosmos DB автоматически управляет наборами реплик, тогда как в Apache Cassandra для обслуживания набора реплик требуются различные инструменты.
Apache Cassandra применяет концепцию токенов, которые являются хэшами ключей секций. В основе токенов лежит 64-разрядный хэш Murmur3 со значениями от–2^63 до –2^63–1. В Apache Cassandra этот диапазон обычно называется Token Ring. Token Ring распределяется на диапазоны токенов, которые, в свою очередь, делятся между узлами, присутствующими в собственном кластере Apache Cassandra. Секционирование для Azure Cosmos DB реализуется аналогичным образом, но использует другой хэш-алгоритм и имеет более крупный внутренний Token Ring. Однако внешне мы предоставляем тот же диапазон токенов, что и Apache Cassandra, т. е. от–2^63 до –2^63–1.
Первичный ключ
Все таблицы в API для Cassandra должны иметь определенный primary key тип. Ниже приведен синтаксис для первичного ключа.
column_name cql_type_definition PRIMARY KEY
Предположим, нам нужно создать пользовательскую таблицу, в которой хранятся сообщения для разных пользователей:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
В этом проекте мы определили поле id как первичный ключ. Первичный ключ функционирует как идентификатор для записи в таблице, а также используется в качестве ключа секции в Azure Cosmos DB. Если первичный ключ определен ранее описанным способом, в каждой секции будет только одна запись. В результате мы получим идеальное горизонтальное и масштабируемое распределение при записи данных в базу данных. Этот принцип отлично подходит для вариантов использования с поиском по паре "ключ-значение". Приложение должно предоставлять первичный ключ при считывании данных из таблицы для повышения производительности чтения.

Составной первичный ключ
В Apache Cassandra также есть понятие compound keys. Составной primary key содержит не менее двух столбцов; первый столбец — partition key, а все дополнительные столбцы — clustering keys. Ниже показан синтаксис для compound primary key.
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Предположим, мы хотим изменить приведенную выше структуру и обеспечить эффективное извлечение сообщений для определенного пользователя:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
В этом проекте мы теперь определяем user как ключ секции, а id — как ключ кластеризации. Вы можете определить столько ключей кластеризации, сколько требуется, но каждое значение (или сочетание значений) для ключа кластеризации должно быть уникальным, чтобы в результате можно было добавить несколько записей в одну и ту же секцию, например:
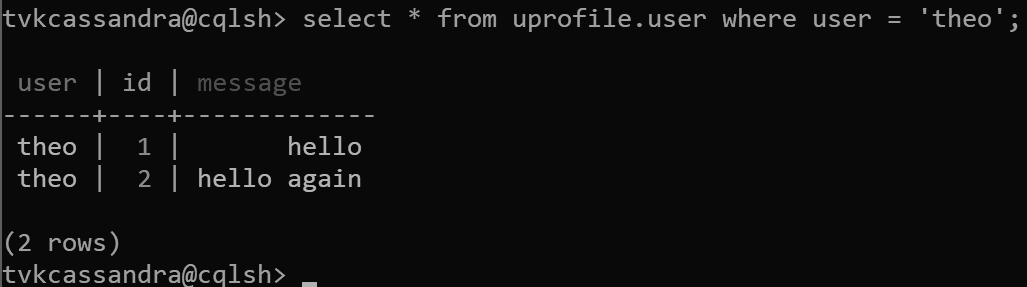
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Возвращаемые данные сортируются по ключу кластеризации, как предполагается в Apache Cassandra:
Предупреждение
Если при запросе данных в таблице с составным первичным ключом нужно отфильтровать ключ секции и другие неиндексированные поля, кроме ключа кластеризации, обязательно явно добавьте вторичный индекс в ключ секции:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB для Apache Cassandra не применяет индексы к ключам секций по умолчанию, а индекс в этом сценарии может значительно повысить производительность запросов. Дополнительные сведения можно получить в статье о дополнительной индексации.
При использовании данных, смоделированных таким образом, каждой секции можно назначить несколько записей, сгруппированных по пользователям. Таким способом можно выдать запрос, эффективно направляемый посредством partition key (в данном случае user), чтобы получить все сообщения для данного пользователя.
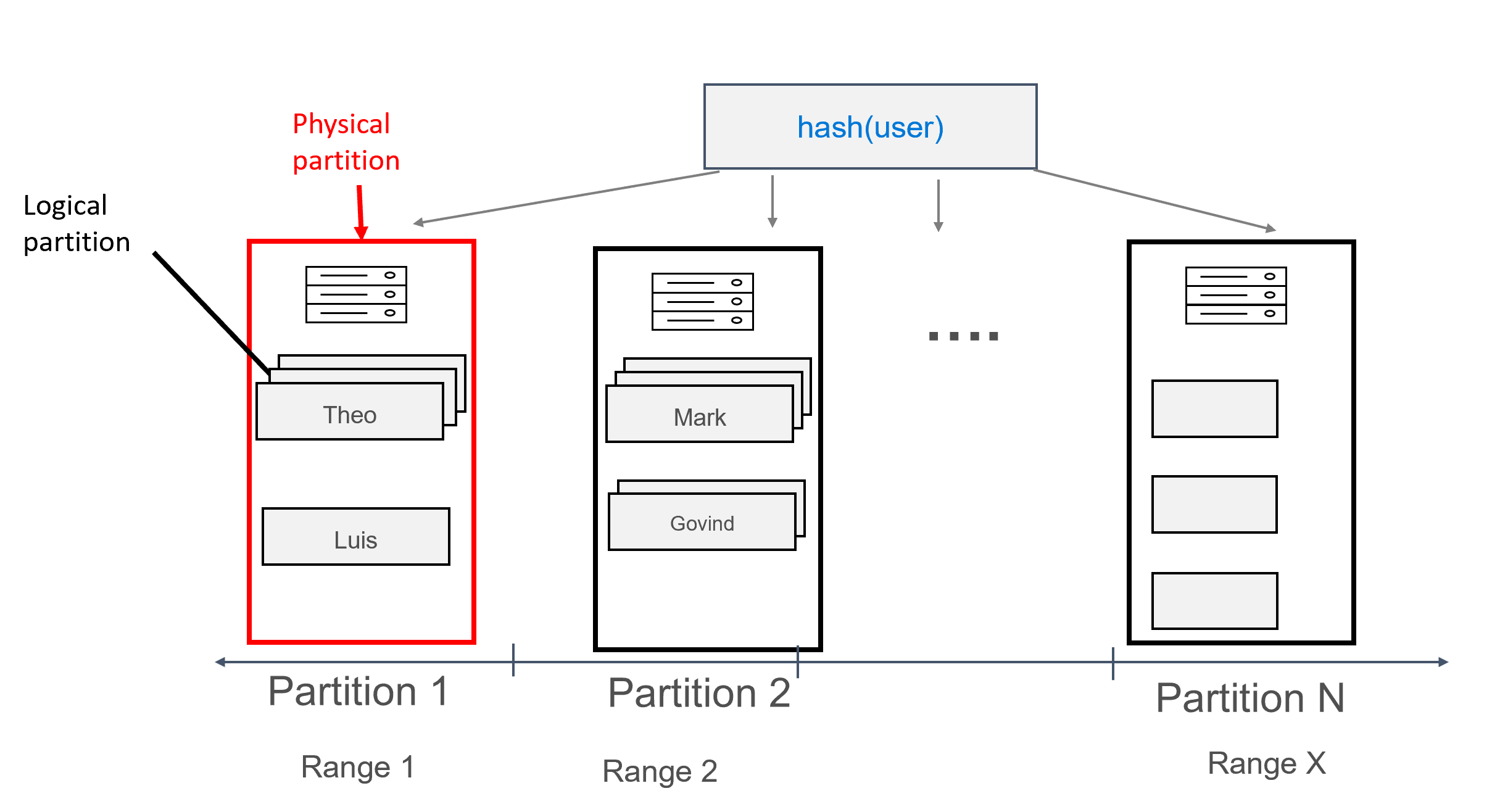
Составной ключ секции
Составные ключи секции, по сути, работают так же, как и составные ключи, описанные выше, с той лишь разницей, что в качестве составного ключа секции можно указать несколько столбцов. Ниже показан синтаксис составных ключей секций.
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Например, можно использовать следующий код, где уникальное сочетание firstname и lastname будет формировать ключ секции, а id — это ключ кластеризации:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Следующие шаги
- Дополнительные сведения о секционировании и горизонтальном масштабировании в Azure Cosmos DB.
- Дополнительные сведения о подготовленной пропускной способности в базе данных Azure Cosmos DB см. в этой статье.
- Дополнительные сведения о глобальном распределении в базе данных Azure Cosmos DB см. в этой статье.