Выбор столбцов распространения в Azure Cosmos DB для PostgreSQL
Область применения: ![]() Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Выбор столбца распределения каждой таблицы является одним из важнейших решений при моделировании, принимаемых вами. Azure Cosmos DB для PostgreSQL сохраняет строки в сегментах на основе значения столбца распределения строк.
Правильный выбор группирует связанные данные на одних и тех же физических узлах, что ускоряет запросы и обеспечивает поддержку всех функций SQL. Неправильный выбор приведет к медленной работе системы.
Общие советы
Ниже приведены четыре критерия выбора оптимального столбца распределения для распределенных таблиц.
Выбирайте столбец, который является ключевым для рабочей нагрузке приложения.
Этот столбец можно рассматривать как важнейшую составляющую в процессе секционирования данных.
Примеры:
device_idв рабочей нагрузке IoTsecurity_idдля финансового приложения, отслеживающего ценные бумагиuser_idдля аналитики пользователейtenant_idдля мультитенантного приложения SaaS
Выбирайте столбец с достаточной кратностью и равномерным статистическим распределением.
Столбец должен содержать много значений и равномерно распределяться по всем сегментам.
Примеры:
- Кратность превышает 1000
- Не выбирайте столбец с одинаковым значением во многих строках (неравномерное распределение данных).
- Если в рабочей нагрузке SaaS один арендатор значительно больше остальных, распределение данных может оказаться неравномерным. В этой ситуации можно реализовать изоляцию арендатора, чтобы создать для работы с этим арендатором выделенный сегмент.
Выбирайте столбец, который будет выгоден с точки зрения ваших существующих запросов.
Для транзакционной или операционной рабочей нагрузки (где большинство запросов занимает по несколько миллисекунд) выбирайте столбец, который отображается как фильтр в предложениях
WHEREпо крайней мере 80 % запросов. Например, это может быть столбецdevice_idв запросеSELECT * FROM events WHERE device_id=1.Для аналитической рабочей нагрузки (где большинство запросов занимает 1–2 секунды) выбирайте столбец, который позволяет выполнять запросы параллельно между рабочими узлами. Например, такой столбец часто встречается в предложениях GROUP BY или запрашивается для получения нескольких значений одновременно.
Выбирайте столбец, который есть в большинстве больших таблиц.
Таблицы размером более 50 ГБ следует распределять. Выбор одинакового столбца распределения для всех таких таблиц позволяет совместно размещать данные этого столбца на рабочих узлах. Совместное размещение позволяет эффективно выполнять соединения и свертки, а также применять внешние ключи.
Другие (меньшие) таблицы могут быть локальными или ссылочными. Если таблицу меньшего размера требуется соединить с распределенными таблицами, сделайте ее ссылочной.
Примеры использования
Мы рассмотрели общие критерии выбора столбца распределения. Теперь давайте выясним, как они используются в распространенных сценариях.
Мультитенантные приложения
Архитектура с несколькими клиентами использует форму иерархического моделирования базы данных для распределения запросов между узлами в кластере. Верхняя часть иерархии данных называется идентификатором клиента и должна храниться в столбце в каждой таблице.
Azure Cosmos DB для PostgreSQL проверяет запросы, чтобы узнать, какой идентификатор клиента они включают и находит соответствующий сегмент таблицы. Он направляет запрос на один рабочий узел, содержащий сегмент. Выполнение запроса со всеми соответствующими данными, размещенными на том же узле, называется совместным размещением.
На следующей схеме показано совместное размещение в модели данных с несколькими клиентами. Она содержит две таблицы, учетные записи и кампании, распределенные по account_id. Затененные поля представляют сегменты. Зеленые сегменты хранятся на одном рабочем узле, а синие сегменты хранятся на другом рабочем узле. Обратите внимание, что запрос на соединение между учетными записями и кампаниями содержит все необходимые данные на одном узле, если обе таблицы ограничены одним идентификатором учетной записи.
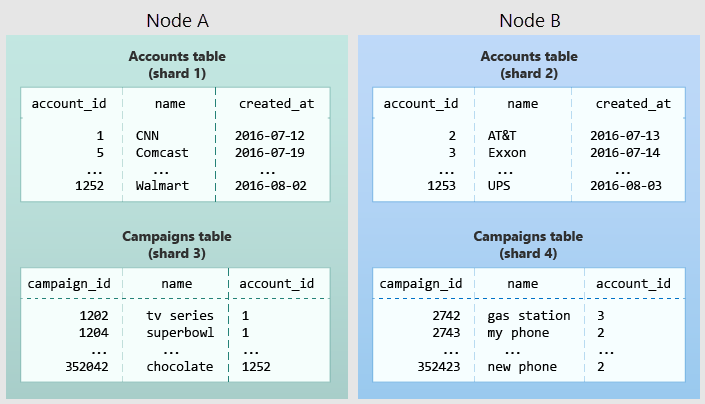
Чтобы применить эту схему в собственной схеме, укажите, что представляет собой клиент в приложении. К общим примерам относятся компания, учетная запись, организация или клиент. Имя столбца будет примерно таким company_id же или customer_id. Изучите каждый запрос и задумайтесь, будет ли он работать, если у него есть дополнительные предложения WHERE для ограничения всех таблиц, вовлеченных в строки с одинаковым идентификатором клиента? Запросы в модели с несколькими клиентами ограничены клиентом. Например, для запросов по продажам или инвентаризации используется область в определенном хранилище.
Рекомендации
- Распределяйте таблицы по общему столбцу идентификаторов арендаторов. Например, в приложении SaaS, где клиенты являются компаниями, идентификатор клиента, скорее всего, будет идентификатором компании.
- Преобразуйте небольшие таблицы между клиентами в ссылочные таблицы. Если несколько клиентов совместно используют небольшую таблицу данных, распространите ее в виде ссылочной таблицы.
- Ограничьте фильтрацию всех запросов приложений по идентификатору арендатора. Каждый запрос должен запрашивать сведения для одного клиента за раз.
Ознакомьтесь с учебником по нескольким клиентам, содержащим пример того, как создать приложение такого типа.
Приложения, работающие в режиме реального времени
Архитектура с несколькими клиентами представляет иерархическую структуру и использует совместное размещение данных для маршрутизации запросов на каждого клиента. В отличие от этого, архитектуры в режиме реального времени зависят от конкретных свойств распределения своих данных, чтобы добиться высокой параллельной обработки.
Идентификатор сущности используется в качестве термина для столбцов распределения в модели реального времени. Типичными сущностями являются пользователи, узлы или устройства.
Запросы в режиме реального времени обычно запрашивают числовые статистические выражения, сгруппированные по датам или категориям. Azure Cosmos DB для PostgreSQL отправляет эти запросы каждому сегменту для частичных результатов и собирает окончательный ответ на узле координатора. Запросы выполняются быстрее, когда количество узлов может быть максимально возможным и если ни один узел не должен выполнять непропорциональное количество операций.
Рекомендации
- Выберите столбец с большим количеством элементов в качестве столбца распределения. Для сравнения поле состояния в таблице заказа со значениями Paid и Shipped плохо выбирает столбец распределения. В нем предполагается только несколько значений, ограничивающих количество сегментов, которые могут содержать данные, и количество узлов, которые могут их обработать. Между столбцами с большим количеством элементов также удобно выбрать столбцы, которые часто используются в предложениях GROUP-BY или в качестве ключей объединения.
- Выберите столбец с равномерным распределением. Если таблица распределяется по столбцу, смещенному по определенным общим значениям, данные в таблице будут накапливаться в определенных сегментах. Узлы, которые содержат эти сегменты, в итоге выполняют больше работы, чем другие узлы.
- Распределите таблицы фактов и измерений по общим столбцам. У вашей таблицы фактов может быть только один ключ распределения. Таблицы, которые присоединяются к другому ключу, не будут совместно размещаться с таблицей фактов. Выберите одно измерение для совместного размещения в зависимости от частоты его соединения и размера соединяемых строк.
- Замените некоторые таблицы измерений на ссылочные таблицы. Если таблица измерения не может быть совместно размещена с таблицей фактов, можно повысить производительность запросов, выполнив распространение копий таблицы измерения на все узлы в форме ссылочной таблицы.
Пример создания приложения такого типа см. в учебнике по работе с панелями мониторинга в реальном времени.
Данные временных рядов
В рабочей нагрузке временных рядов приложения запрашивают последние сведения во время архивации старых данных.
Наиболее распространенной ошибкой в моделировании сведений временных рядов в Azure Cosmos DB для PostgreSQL является использование метки времени в качестве столбца распространения. Распределение хэшей на основе времени распределяет время случайным образом по разным сегментам, а не сохраняет диапазоны времени в сегментах. Запросы, в которых используется время, как правило, представляют собой ссылки на диапазон времени, например самые последние данные. Этот тип распределения хэшей приводит к сетевым издержкам.
Рекомендации
- Не выбирайте метку времени в качестве столбца распределения. Выберите другой столбец распределения. В приложении с несколькими клиентами используйте идентификатор клиента или в приложении в режиме реального времени используйте идентификатор сущности.
- Вместо этого используйте секционирование таблиц PostgreSQL для времени. Секционирование таблиц используется для разбиения большой таблицы данных, упорядоченных по времени, на несколько наследуемых таблиц с каждой таблицей, содержащей разные диапазоны времени. Распределение секционированной таблицы Postgres создает сегменты для унаследованных таблиц.
Следующие шаги
- Узнайте, как совместное размещение между распределенными данными помогает быстрее выполнять запросы.
- Изучите возможности столбца распределения в распределенной таблице и других полезных диагностических запросов.