Запрос данных в Azure Data Lake с помощью Azure Data Explorer
Azure Data Lake Storage — это высокомасштабируемое и экономичное решение озера данных для анализа больших данных. Оно сочетает в себе мощь высокопроизводительной файловой системы с обширными возможностями масштабирования и экономией для быстрого получения аналитических сведений. Data Lake Storage 2-го поколения расширяет возможности Хранилища BLOB-объектов Azure и оптимизировано для рабочих нагрузок аналитики.
Azure Data Explorer интегрируется с Хранилищем BLOB-объектов Azure и Azure Data Lake Storage (1-го и 2-го поколений), предоставляя быстрый, кэшированный и индексированный доступ к данным, которые хранятся во внешнем хранилище. Вы можете анализировать и запрашивать данные без предварительного приема в Azure Data Explorer. Кроме того, вы можете одновременно запрашивать принятые и непринятые внешние данные. Дополнительные сведения см. в статье Создание внешней таблицы с помощью мастера веб-интерфейса Azure Data Explorer. Краткий обзор см. в статье Внешние таблицы.
Совет
Для наилучшей производительности запросов данные необходимо принять в Azure Data Explorer. Возможность запрашивать внешние данные без предварительного приема необходимо использовать только для исторических данных или данных, которые редко запрашиваются. Оптимизируйте производительность запрашивания внешних данных для получения наилучших результатов.
Создание внешней таблицы
Предположим, у вас есть множество CSV-файлов, которые содержат исторические сведения о продуктах, хранящихся в хранилище, и вы хотите выполнить быстрый анализ, чтобы найти пять самых популярных продуктов за прошлый год. В этом примере CSV-файлы выглядят следующим образом:
| Отметка времени | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | Двусторонняя дискета с высокой плотностью и размером 3,5 дюйма |
| 2019-01-01 11:30:55 | YDX1 | Синтезатор Yamaha DX1 |
| ... | ... | ... |
Файлы хранятся в Хранилище BLOB-объектов Azure mycompanystorage в контейнере с именем archivedproducts, секционированном по дате:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Чтобы выполнить запрос KQL к этим CSV-файлам напрямую, используйте команду .create external table для определения внешней таблицы в Azure Data Explorer. Дополнительные сведения о параметрах команды для создания внешней таблицы см. в статье о командах для работы с внешними таблицами.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Теперь внешняя таблица отображается в области пользовательского веб-интерфейса Azure Data Explorer слева:

Разрешения внешней таблицы
- Пользователь базы данных может создать внешнюю таблицу. Создатель таблицы автоматически получает права администратора таблицы.
- Администратор кластера, базы данных или таблицы может изменять существующую таблицу.
- Любой пользователь или читатель базы данных может отправлять запросы к внешней таблице.
Отправка запросов к внешней таблице
После определения внешней таблицы можно использовать функцию external_table() для ссылки на нее. Остальная часть запроса создается на стандартном языке запросов Kusto.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Совместное запрашивание внешних и принятых данных
Можно отправить один запрос к внешним таблицам и к принятым таблицам данных. Вы можете выполнять операторы join или union с внешней таблицей с указанием других данных из Azure Data Explorer, серверов SQL или других источников. Используйте оператор let( ) statement, чтобы назначить короткое имя ссылке на внешнюю таблицу.
В примере ниже Products — это принятая таблица данных, а ArchivedProducts — внешняя таблица, которую мы определили ранее:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Запрашивание данных в иерархических форматах
Azure Data Explorer позволяет запрашивать данные в иерархических форматах, например JSON, Parquet, Avro и ORC. Чтобы сопоставить иерархическую схему данных со схемой внешней таблицы (если они отличаются), используйте команды сопоставления внешних таблиц. Например, если требуется отправить запрос к файлам журналов JSON в следующем формате:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
Определение внешней таблицы выглядит следующим образом:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Определите сопоставление JSON, которое сопоставляет поля данных с полями определения внешней таблицы:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
При отправке запроса к внешней таблице будет вызвано сопоставление, а соответствующие данные будут сопоставлены со столбцами внешней таблицы:
external_table('ApiCalls') | take 10
Дополнительные сведения о синтаксисе сопоставления см. в статье о сопоставлениях данных.
Отправка запроса к внешней таблице TaxiRides в кластере help
Используйте тестовый кластер с именем help, чтобы испытать различные возможности Azure Data Explorer. Кластер help включает определение внешней таблицы для набора данных о такси Нью-Йорка, содержащего данные о миллиардах поездок в такси.
Создание внешней таблицы TaxiRides
В этом разделе показан запрос, используемый для создания внешней таблицы TaxiRides в кластере help. Так как эта таблица уже создана, можно пропустить этот раздел и перейти непосредственно к запрашиванию данных внешней таблицы TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Вы можете найти созданную таблицу TaxiRides в области пользовательского веб-интерфейса Azure Data Explorer слева:
Запрашивание данных внешней таблицы TaxiRides
Выполните вход в https://dataexplorer.azure.com/clusters/help/databases/Samples.
Отправка запросов к внешней таблице TaxiRides без секционирования
Выполните этот запрос во внешней таблице TaxiRides , чтобы отобразить поездки за каждый день недели во всем наборе данных.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Этот запрос позволяет отобразить самый загруженный день недели. Так как данные не секционированы, на получение результатов запросу может понадобиться несколько минут.

Отправка запросов к внешней таблице TaxiRides с секционированием
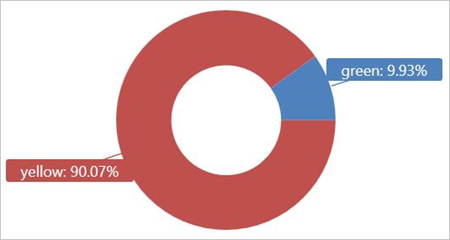
Выполните этот запрос для внешней таблицы TaxiRides, чтобы отобразить типы такси (желтые или зеленые) за январь 2017 г.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Этот запрос использует секционирование, которое оптимизирует время выполнения и производительность запроса. Запрос выполняет фильтрацию в секционированном столбце (pickup_datetime) и возвращает результаты через несколько секунд.
Вы можете написать другие запросы для выполнения с внешней таблицей TaxiRides и получения дополнительных сведений о данных.
Оптимизация производительности запроса
Оптимизируйте производительность запросов в озере данных, используя следующие рекомендации по запрашиванию внешних данных.
Формат данных
- Используйте формат столбцов для аналитических запросов по следующим причинам:
- Считывать можно только столбцы, актуальные для запроса.
- Методы кодирования столбцов могут значительно сократить объем данных.
- Azure Data Explorer поддерживает форматы столбцов Parquet и ORC. Формат Parquet рекомендуется благодаря его оптимизированной реализации.
Регион Azure
Убедитесь, что внешние данные находятся в том же регионе Azure, что и кластер Azure Data Explorer. Эта позволяет сократить затраты и время выборки данных.
Размер файла
Оптимальный размер файла составляет сотни МБ (до 1 ГБ). Избегайте большого количества небольших файлов, требующих ненужных затрат ресурсов, так как это может привести к медленному перечислению файлов и ограниченному использованию формата столбцов. Число файлов должно быть больше числа ядер ЦП в кластере Azure Data Explorer.
Сжатие
Используйте сжатие для уменьшения объема данных, получаемых из удаленного хранилища. Для формата Parquet используйте механизм внутреннего сжатия Parquet, который сжимает группы столбцов отдельно, что позволяет считывать их по отдельности. Чтобы проверить использование механизма сжатия, убедитесь, что файлы именованы следующим образом: <имя_файла>.gz.parquet или <имя_файла>.snappy.parquet, а не <имя_файла>.parquet.gz.
Секционирование
Упорядочите данные с помощью секций (папок), которые позволяют запросу пропускать ненужные пути. При планировании секционирования учитывайте размер файла и типичные фильтры в запросах, такие как метка времени или идентификатор арендатора.
Размер виртуальной машины
Выберите SKU виртуальных машин с большим числом ядер и более высокой пропускной способностью сети (память менее важна). Дополнительные сведения см. в статье Выбор правильного номера SKU виртуальной машины для кластера Azure Data Explorer.