Преобразование “Выбор”в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование “Выбор” можно использовать для переименования, удаления и переупорядочивания столбцов. Это преобразование не изменяет данные строки, но выбирает столбцы, которые передаются далее по нисходящей.
При использовании преобразования “Выбор” можно указать фиксированные сопоставления, использовать шаблоны для сопоставления на основе правил или включить автоматическое сопоставление. Фиксированные и основанные на правилах сопоставления можно использовать в одном и том же преобразовании “Выбор”. Если столбец не соответствует одному из заданных сопоставлений, он будет удален.
Фиксированное сопоставление
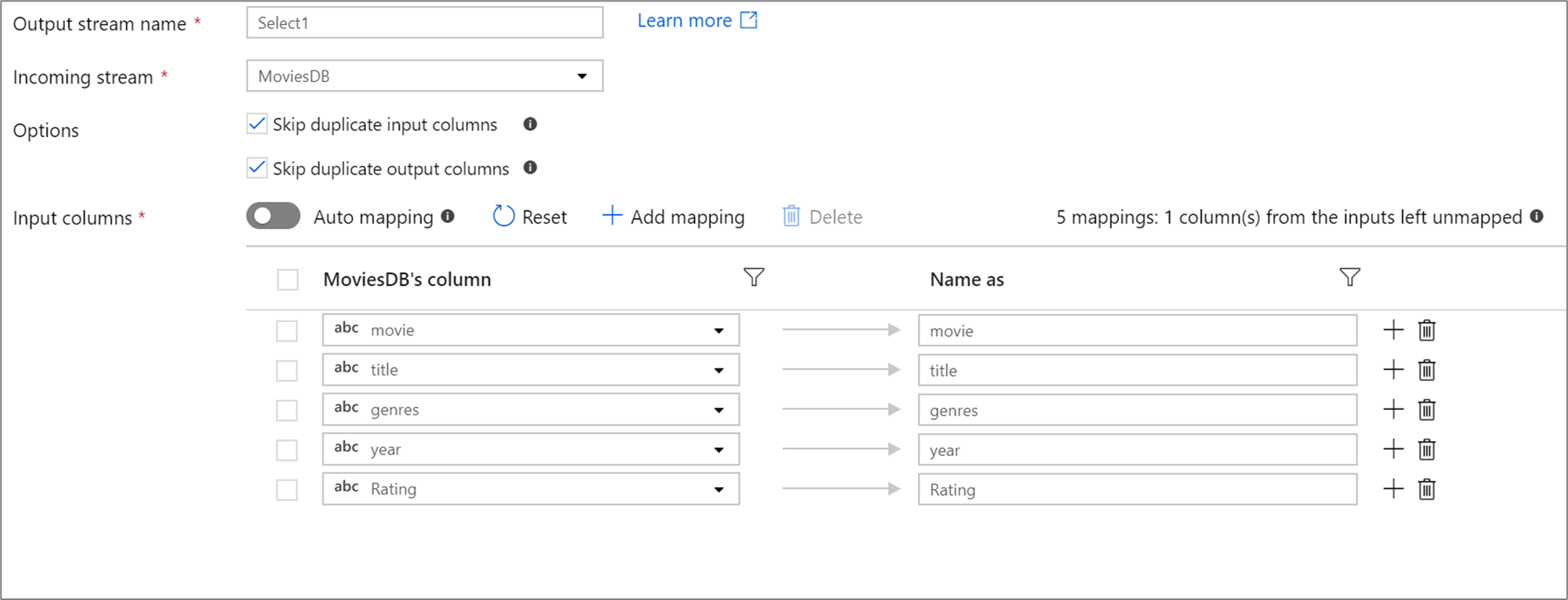
Если в проекции определено менее 50 столбцов, по умолчанию все они будут использовать фиксированное сопоставление. Фиксированное сопоставление берет конкретный входящий столбец и соотносит с ним точное имя.
Примечание.
С помощью фиксированного сопоставления невозможно сопоставить или переименовать смешенный столбец.
Сопоставление иерархических столбцов
С помощью фиксированных сопоставлений можно сопоставить подчиненный столбец в иерархии со столбцом верхнего уровня. Если иерархия определена, используйте раскрывающийся список столбцов для выбора подчиненного столбца. Преобразование “Выбор” создаст новый столбец со значением и типом данных подчиненного столбца.
Rule-based mapping (Выбор преобразования: сопоставление на основе правил)
Если нужно сопоставить несколько столбцов одновременно или передать вниз смещенные столбцы, используйте сопоставление на основе правил, чтобы задать сопоставления с помощью шаблонов столбцов. Используйте для сопоставления атрибуты name, type, stream и position столбцов. Фиксированные и основанные на правилах сопоставления можно применять в любом сочетании. По умолчанию все проекции, содержащие больше 50 столбцов, используют сопоставление на основе правил, которое проверяет каждый столбец и выводит введенное имя.
Чтобы добавить сопоставление на основе правил, нажмите кнопку Добавить сопоставление и выберите Сопоставление на основе правил.

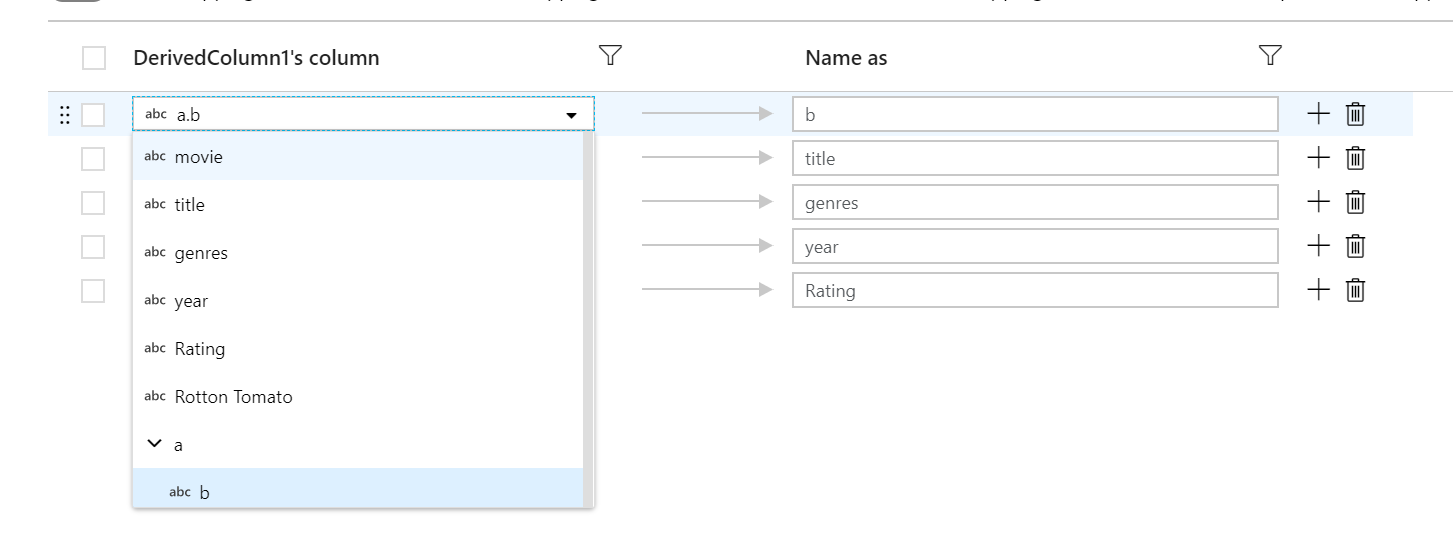
Каждому сопоставлению на основе правил нужны два входных элемента: условие, согласно которому производится сопоставление, и имя для каждого сопоставленного столбца. Оба значения вводятся с помощью построителя выражений. В поле выражения слева введите логическое условие соответствия. В поле выражения справа укажите, с чем будет сопоставляться столбец.

Используйте синтаксис $$, чтобы указать входное имя сопоставленного столбца. Возьмем в качестве примера приведенное выше изображение. Предположим, что пользователь хочет сопоставить все столбцы со строковыми значениями, имена которых содержат меньше шести символов. Входящий столбец с именем test благодаря выражению $$ + '_short' будет переименован в test_short. Если это единственное сопоставление, все столбцы, не отвечающие условию, будут удалены из данных вывода.
С помощью шаблонов можно сопоставлять и смещенные, и определенные столбцы. Чтобы узнать, какие определенные столбцы сопоставляются согласно правилу, щелкните значок очков рядом с правилом. Чтобы проверить полученные результаты, используйте просмотр данных.
Сопоставление регулярного выражения
Если щелкнуть значок шеврона вниз, можно указать условие сопоставления регулярного выражения. Условие сопоставления регулярного выражения позволяет сопоставить все имена столбцов, которые ему соответствуют. Это условие можно использовать в сочетании со стандартными сопоставлениями на основе правил.

В приведенном выше примере для сопоставления используется шаблон регулярного выражения (r) или любое имя столбца, в котором содержится строчная буква r. Как и в стандартном сопоставлении, в сопоставлении на основе правил все сопоставленные столбцы изменяются в соответствии с условием, заданным справа с помощью синтаксиса $$.
Если имя столбца удовлетворяет нескольким сопоставлениям регулярного выражения, вы можете сослаться на конкретные совпадения с помощью синтаксиса $n, где n обозначает совпадение. Например, $2 указывает на второе совпадение в имени столбца.
Иерархии на основе правил
Если в проекции определена иерархия, можно использовать сопоставление на основе правил для сопоставления подчиненных столбцов иерархии. Укажите условие соответствия и сложный столбец, подчиненные столбцы которого нужно сопоставить. Каждый сопоставленный подчиненный столбец будет выводиться с помощью правила переименования, указанного справа.
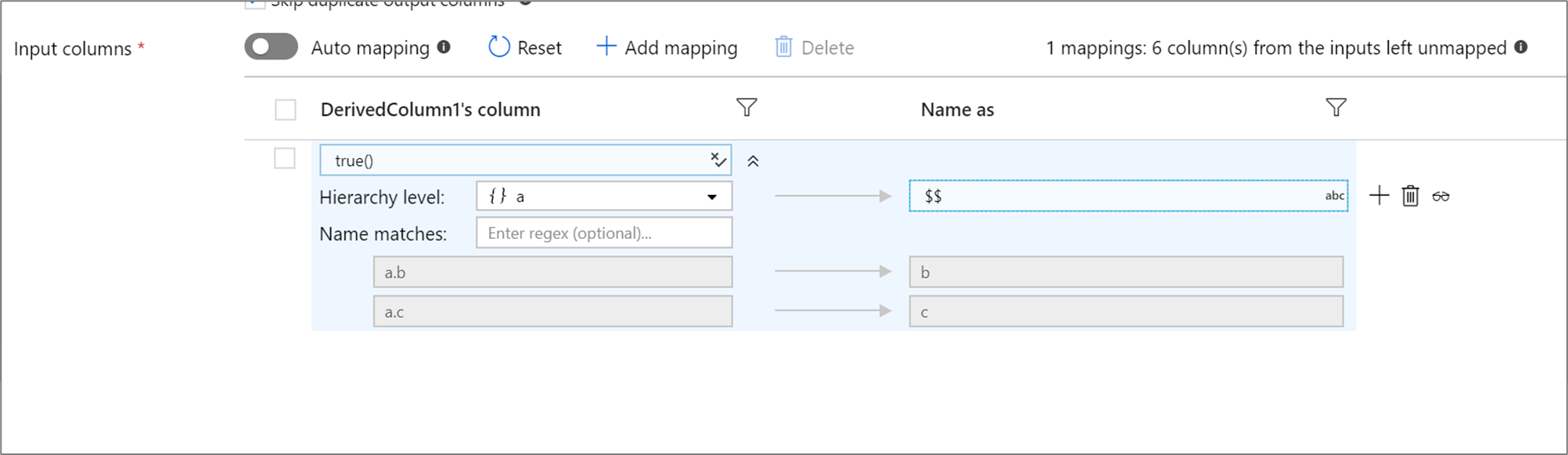
В приведенном выше примере сопоставляются все подчиненные столбцы сложного столбца a. a содержит два подчиненных столбца: b и c. Выходная схема будет содержать два столбца b и c, так как условием переименования является $$.
Определение параметров
Сопоставление на основе правил позволяет применять параметры к именам столбцов. Используйте ключевое слово name, чтобы сопоставить имена входящих столбцов с параметром. Например, если имеется параметр потока данных mycolumn, можно создать правило, которое будет сопоставлять имя любого столбца, соответствующее mycolumn. Сопоставленному столбцу можно присвоить в качестве имени жестко заданную строку (например, "бизнес-ключ"), и ссылаться на нее явным образом. В этом примере используется условие соответствия name == $mycolumn, а условием имени является "бизнес-ключ".
Автоматическое сопоставление
При добавлении преобразования “Выбор” можно включить Автоматическое сопоставление, передвинув ползунок “Автоматическое сопоставление”. При использовании автоматического сопоставления преобразование “Выбор” сопоставляет все входящие столбцы (кроме дубликатов) с тем же именем, что и у входных данных. Это касается и смещенных столбцов, а значит, выходные данные могут содержать столбцы, не определенные в схеме. Дополнительные сведения о смещенных столбцах см. в разделе осмещении схемы.
Если автоматическое сопоставление используется, преобразование “Выбор” будет соблюдать параметры пропуска дубликатов и предоставит новый псевдоним для существующих столбцов. Присвоение псевдонимов полезно при выполнении нескольких операций соединения или поиска в одном и том же потоке и в сценариях самосоединения.
Дубликаты столбцов
По умолчанию преобразование “Выбор” удаляет дубликаты столбцов во входной и в выходной проекциях. Дубликаты входных столбцов часто появляются вследствие преобразований “Соединение” и “Поиск”, когда имена столбцов дублируются на каждой стороне соединения. При сопоставлении двух различных входных столбцов с одним именем на выходе могут получиться дубликаты столбцов. Установите флажок, чтобы указать, следует ли удалять или оставлять дубликаты столбцов.
Упорядочивание столбцов
Порядок сопоставлений определяет порядок выходных столбцов. Если входной столбец сопоставлен несколько раз, будет учитываться только первое сопоставление. У удаляемых дубликатов столбцов будет сохраняться первое совпадение.
Скрипт потока данных
Синтаксис
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Пример
Ниже приведен пример сопоставления “Выбор” и его сценарий потока данных:
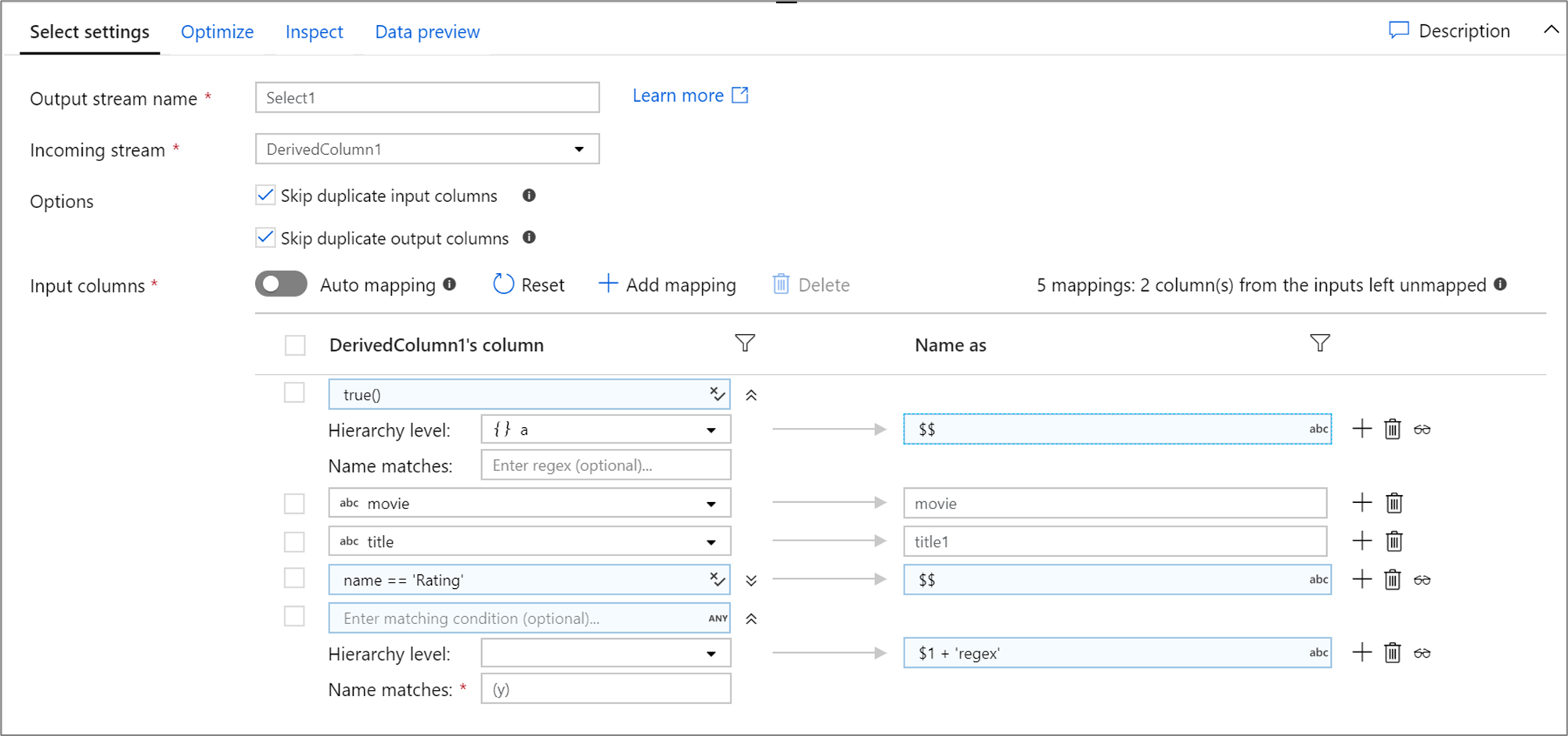
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Связанный контент
- Применив преобразование “Выбор” для переименования, изменения порядка и псевдонима столбцов, используйте преобразование “Приемник”, чтобы разместить данные в хранилище данных.