Использование Фабрики данных Azure для переноса данных с локального сервера Netezza в Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Фабрика данных Azure поддерживает производительный, надежный и экономичный механизм переноса данных с локального сервера Netezza в учетную запись хранения Azure или базу данных Azure Synapse Analytics.
В этой статье содержатся следующие сведения для специалистов по обработке и анализу данных и разработчиков:
- Производительность
- Устойчивость копирования
- Безопасность сети
- Общая архитектура решения
- Рекомендации по реализации
Производительность
Фабрика данных Azure предлагает бессерверную архитектуру, обеспечивающую параллелизм на различных уровнях. Разработчики могут создавать конвейеры для использования всей полосы пропускания сети и базы данных, чтобы максимизировать пропускную способность при переносе данных для своей среды.

Приведенная выше схема демонстрирует следующие моменты:
Одно действие копирования может использовать масштабируемые вычислительные ресурсы. При использовании Azure Integration Runtime можно указать до 256 DIU для каждого действия копирования в бессерверном режиме. В локальной среде выполнения интеграции (IR) можно вручную вертикально увеличить масштаб на одной машине или увеличить его горизонтально, распространив на несколько машин (до четырех узлов), и одно действие копирования распределяет секцию по всем этим узлам.
При выполнении одного действия копирования выполняется считывание и запись в хранилище данных с использованием нескольких потоков.
Поток управления Фабрики данных Azure может запускать несколько операций копирования параллельно, например с помощью цикла For Each.
Дополнительные сведения см. в пособии по производительности и масштабируемости действий копирования.
Устойчивость
Фабрика данных Azure имеет встроенный механизм повтора в рамках одного действия копирования, позволяющий справляться с определенным количеством временных сбоев в хранилищах данных или в базовой сети.
Для действия копирования Фабрики данных Azure предусмотрены два способа устранения несовместимых строк при копировании данных между хранилищами источника и приемника. Вы можете либо прервать и завершить действие копирования, либо продолжить копирование остальных данных, просто пропуская несовместимые строки. Кроме того, чтобы понять причину сбоя, можно зарегистрировать несовместимые строки в хранилище BLOB-объектов Azure или Azure Data Lake Store, исправить данные в источнике и повторить действие копирования.
Безопасность сети
По умолчанию Фабрика данных Azure передает данные с локального сервера Netezza в учетную запись хранения Azure или базу данных Azure Synapse Analytics, используя зашифрованное подключение по протоколу HTTPS. HTTPS обеспечивает шифрование данных при передаче и предотвращает прослушивание трафика и атаки типа "злоумышленник в середине".
Кроме того, если вы не хотите, чтобы данные передавались через общедоступный Интернет, вы можете повысить уровень безопасности, передавая данные по каналу частного пиринга через Azure Express Route.
В следующем разделе объясняется, как достичь более высокого уровня безопасности.
Архитектура решения
В этом разделе рассматриваются два способа переноса данных.
Перенос данных через общедоступный Интернет

Приведенная выше схема демонстрирует следующие моменты:
В этой архитектуре данные безопасно передаются по протоколу HTTPS через общедоступный Интернет.
Для реализации этой архитектуры необходимо установить среду выполнения интеграции Фабрики данных Azure (локальную) на компьютере под управлением Windows, который находится за корпоративным брандмауэром. У этой среды выполнения интеграции должна быть возможность напрямую обращаться к серверу Netezza. Чтобы использовать всю пропускную способность сети и хранилища для копирования данных, можно вручную вертикально увеличить масштаб на одном компьютере или увеличить его горизонтально, распространив на несколько компьютеров.
С помощью этой архитектуры можно переносить исходные данные моментальных снимков и разностные данные.
Перенос данных через частную сеть
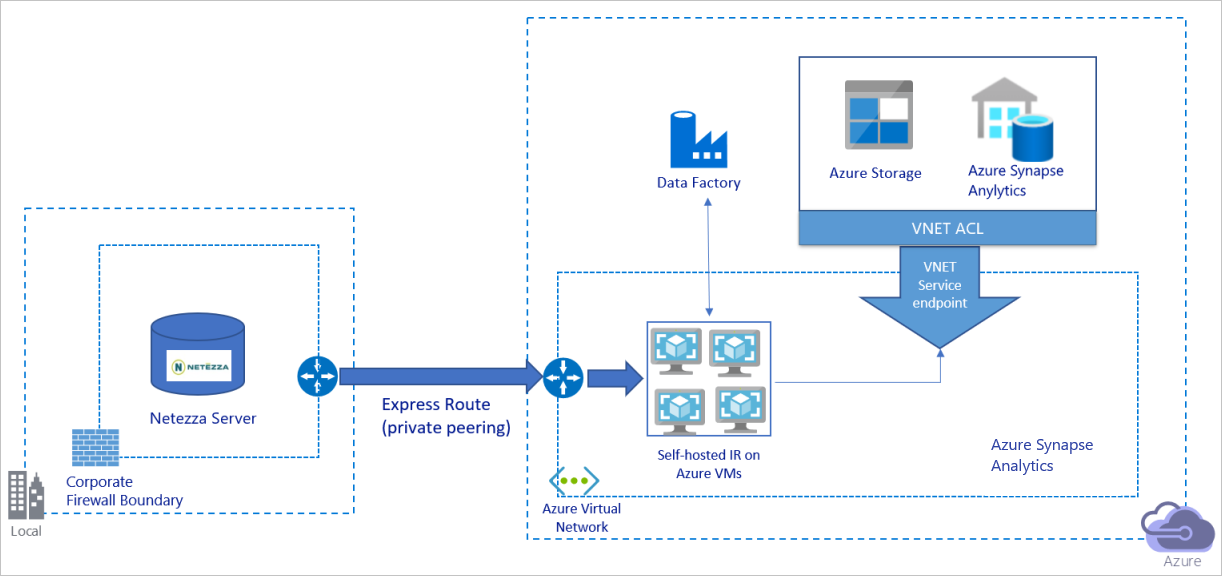
Приведенная выше схема демонстрирует следующие моменты:
В этой архитектуре данные переносятся по каналу частного пиринга через Azure Express Route и никогда не проходят через общедоступный Интернет.
Для реализации такой архитектуры необходимо установить среду выполнения интеграции Фабрики данных Azure (локальную) на виртуальной машине Windows в виртуальной сети Azure. Чтобы использовать всю пропускную способность сети и хранилища для копирования данных, можно вручную вертикально увеличить масштаб на одной виртуальной машине или увеличить его горизонтально, распространив на несколько машин.
С помощью этой архитектуры можно переносить исходные данные моментальных снимков и разностные данные.
Реализация рекомендаций
Управление проверкой подлинности и учетными данными
Для аутентификации в Netezza можно использовать проверку подлинности ODBC со строкой подключения.
Аутентификация в хранилище BLOB-объектов Azure:
Мы настоятельно рекомендуем использовать управляемые удостоверения для ресурсов Azure. Созданные на основе автоматически управляемого удостоверения Фабрика данных Azure в идентификаторе Microsoft Entra, управляемые удостоверения позволяют настраивать конвейеры без необходимости предоставлять учетные данные в определении связанной службы.
Кроме того, проверку подлинности в хранилище BLOB-объектов Azure можно проходить с использованием субъекта-службы, подписанного URL-адреса или ключа учетной записи хранения.
Аутентификация в хранилище Azure Data Lake Storage 2-го поколения:
Мы настоятельно рекомендуем использовать управляемые удостоверения для ресурсов Azure.
Также можно использовать субъект-службу или ключ учетной записи хранения.
Аутентификация в Azure Synapse Analytics
Мы настоятельно рекомендуем использовать управляемые удостоверения для ресурсов Azure.
Также можно использовать субъект-службу или проверку подлинности SQL.
Если вы не используете управляемые удостоверения для ресурсов Azure, настоятельно рекомендуется хранить учетные данные в Azure Key Vault, чтобы упростить централизованное управление и смену ключей без изменения связанных служб Фабрики данных Azure. Это также одна из рекомендаций для CI/CD.
Перенос исходных моментальных снимков
Для небольших таблиц (т. е. таблиц объемом менее 100 ГБ или таблиц, которые могут быть перенесены в Azure в течение двух часов) каждое задание копирования может загружать данные потаблично. Для повышения пропускной способности можно запустить несколько заданий копирования Фабрики данных Azure для параллельной загрузки отдельных таблиц.
В каждом задании копирования для выполнения параллельных запросов и копирования данных по секциям достичь определенного уровня параллелизма также можно с помощью параметра свойства parallelCopies с одним из следующих параметров секции данных:
Для повышения эффективности рекомендуем начать со среза данных. Убедитесь, что значение в параметре
parallelCopiesменьше, чем общее число секций срезов данных в вашей таблице на сервере Netezza.Если объем всех секций срезов данных все равно велик (например, 10 ГБ или больше), мы рекомендуем перейти на динамическую секцию диапазона. Этот вариант обеспечивает большую гибкость при определении количества секций и объема каждой секции по столбцам секционирования, верхней и нижней границам.
Для больших таблиц (т. е. таблиц с томом размером 100 ГБ и выше или таблиц, которые не могут быть перенесены в Azure в течение двух часов) рекомендуется секционировать данные по пользовательскому запросу, а затем заставлять каждое задание копирования копировать по одной секции за раз. Для повышения пропускной способности можно одновременно запустить несколько заданий копирования Фабрики данных Azure. Для каждого целевого объекта задания копирования, которое загружает одну секцию по пользовательскому запросу, увеличить пропускную способность можно, включив параллелизм с помощью среза данных или динамического диапазона.
Если какое-либо задание копирования завершит работу сбоем из-за временной проблемы с сетью или хранилищем данных, оно сможет повторно загрузить эту секцию из таблицы. Другие задания копирования, которые загружают другие секции, при этом не затрагиваются.
При загрузке данных в базу данных Azure Synapse Analytics мы рекомендуем включить в задании копирования PolyBase с использованием хранилища BLOB-объектов Azure в качестве промежуточного места хранения.
Перенос добавочных данных
Для поиска в таблице новых и обновленных строк используйте столбец timestamp или инкрементный ключ в схеме. Последнее значение можно сохранить в качестве верхнего предела во внешней таблице, а затем использовать его для фильтрации добавочных данных при следующей загрузке.
У каждой таблицы может быть собственный столбец верхнего предела для поиска новых и обновленных строк. Для управления этим процессом мы рекомендуем создать внешнюю таблицу. В этой таблице каждая строка представляет одну таблицу с сервера Netezza с именем столбца верхнего предела и его текущим значением.
Настройка локальной среды выполнения интеграции
Если вы переносите данные с сервера Netezza в Azure, то независимо от того, находится ли ваш сервер в локальной среде за корпоративным брандмауэром или в виртуальной сети, вам потребуется установить на компьютере Windows или на виртуальной машине локальную среду IR, которая послужит подсистемой для перемещения данных. При установке локальной среды IR рекомендуется использовать следующую стратегию:
Для каждого компьютера или виртуальной машины Windows начните с конфигурации в 32 виртуальных ЦП и 128 ГБ памяти. Во время переноса данных вы можете отслеживать загрузку ЦП и памяти виртуальной машины среды выполнения интеграции, чтобы понимать, требуется ли вертикально увеличить масштаб виртуальной машины для повышения производительности или уменьшить его, чтобы сократить затраты.
Кроме того, можно выполнить горизонтальное масштабирование, связав до четырех узлов виртуальных машин с одной локальной средой выполнения интеграции. Одно задание копирования, выполняемое в локальной среде выполнения интеграции, автоматически использует все узлы виртуальных машин для параллельного копирования данных. Для обеспечения высокой доступности рекомендуется начать с четырех узлов виртуальных машин, чтобы избежать возникновения единой точки отказа во время переноса данных.
Ограничение секций
Рекомендуется провести оценку производительности с помощью репрезентативного образца набора данных, чтобы можно было определить подходящий размер секции для каждого задания копирования. Мы рекомендуем загружать каждую секцию в Azure в течение не более двух часов.
Для копирования таблицы начните с одного действия копирования с одной машиной локальной среды IR. Постепенно увеличивайте значение parallelCopies в зависимости от количества секций срезов данных в таблице. Выясните, удается ли загрузить в Azure всю таблицу в течение двух часов с учетом пропускной способности, полученной при задании копирования.
Если загрузить ее в Azure в течение двух часов невозможно, а емкость локальной среды IR и хранилища данных используется не полностью, постепенно увеличивайте количество одновременных действий копирования до тех пор, пока не достигнете предела сети или пропускной способности хранилищ данных.
Продолжайте отслеживать загрузку ЦП и памяти на компьютере локальной среды IR и будьте готовы вертикально масштабировать ее или масштабировать горизонтально на несколько компьютеров, когда видите, что ЦП и память используются полностью.
При возникновении ошибок регулирования, о которых сообщает действие копирования в Фабрике данных Azure, сократите параллелизм или уменьшите значение parallelCopies в Фабрике данных Azure либо попробуйте увеличить лимиты пропускной способности или операций ввода-вывода в секунду для хранилищ данных и сети.
Подбор ценовой категории
Рассмотрим следующий конвейер, который создается для переноса данных с локального сервера Netezza в базу данных Azure Synapse Analytics:

Предположим, что выполняются следующие условия:
Общий объем данных составляет 50 терабайт (ТБ).
Мы переносим данные с помощью архитектуры первого решения (сервер Netezza находится в локальной среде за брандмауэром).
Том 50 ТБ разделен на 500 секций, и каждое действие копирования перемещает одну из них.
Для каждого действия копирования настраивается одна локальная среда IR на четыре компьютера и обеспечивается пропускная способность 20 мегабит в секунду (Мбит/с). (В рамках действия копирования
parallelCopiesимеет значение 4, и каждый поток загрузки данных из таблицы достигает пропускной способности в 5 Мбит/с.)Степень параллелизма ForEach имеет значение 3, а суммарная пропускная способность — 60 Мбит/с.
В итоге для завершения переноса потребуется 243 часа.
На основе приведенных выше предположений спрогнозируем цену:
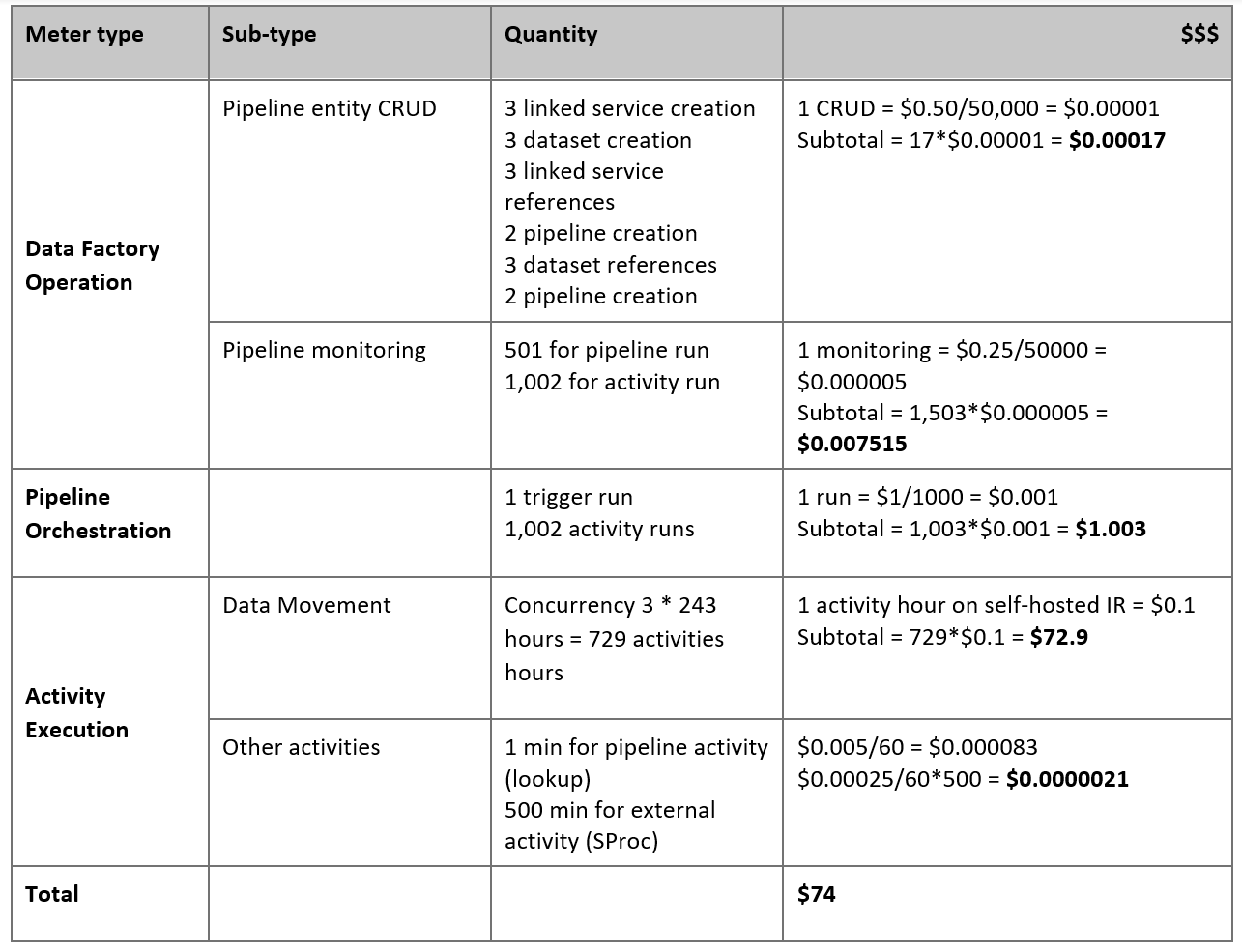
Примечание.
В таблице выше указаны гипотетические цены. Реальная цена зависит от фактической пропускной способности в среде. Цена за компьютер с Windows (с установленной локальной средой IR) сюда не включена.
Дополнительная справка
Дополнительные сведения см. в следующих статьях и пособиях:
- Соединитель Netezza
- Соединитель ODBC
- Соединитель Хранилища BLOB-объектов Azure
- Copy data to or from Azure Data Lake Storage Gen2 Preview using Azure Data Factory (Preview) (Копирование данных в Azure Data Lake Storage Gen2 (предварительная версия) или из него с помощью фабрики данных Azure)
- Соединитель Azure Synapse Analytics
- Руководство по настройке производительности действия копирования
- Создание и настройка локальной среды выполнения интеграции
- Высокая доступность и масштабируемость локальной среды выполнения интеграции
- Вопросы безопасности при перемещении данных
- Хранение учетных данных в Azure Key Vault
- Добавочное копирование данных из одной таблицы
- Добавочное копирование данных из нескольких таблиц
- Страница цен на Фабрику данных Azure