Миграция данных из Amazon S3 в службу хранилища Azure с помощью Фабрики данных Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Фабрика данных Azure обеспечивает эффективный, надежный и экономичный механизм переноса любых объемов данных из Amazon S3 в Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения. В этой статье содержатся следующие сведения для специалистов по обработке и анализу данных и разработчиков:
- Производительность
- Устойчивость копирования
- Безопасность сети
- Общая архитектура решения
- Рекомендации по реализации
Производительность
ADF предлагает бессерверную архитектуру, которая позволяет параллелизму на разных уровнях, что позволяет разработчикам создавать конвейеры для полного использования пропускной способности сети и операций ввода-вывода в секунду хранилища и пропускной способности для максимальной пропускной способности перемещения данных для вашей среды.
Клиенты успешно выполнили перенос сотен миллионов файлов, общий объем которых измеряется петабайтами, из Amazon S3 в Хранилище BLOB-объектов Azure со стабильной пропускной способностью 2 Гбит/с и выше.
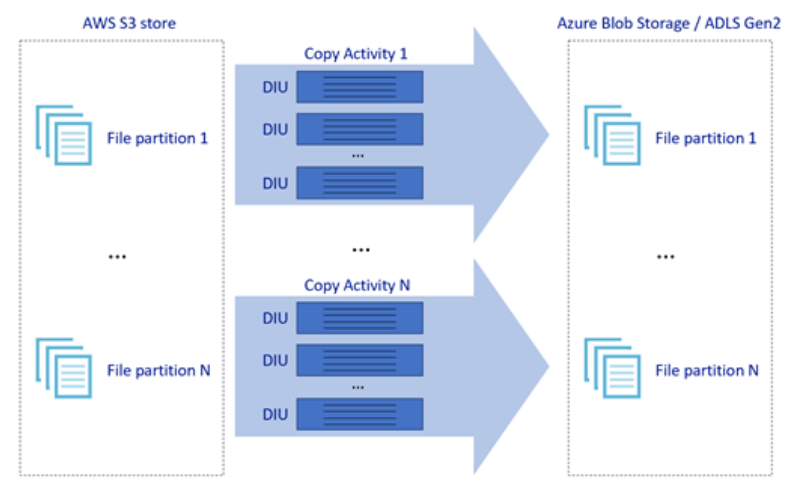
На рисунке выше показано, как можно обеспечить высокую скорость перемещения данных с помощью различных уровней параллелизма.
- Одно действие копирования может воспользоваться масштабируемыми вычислительными ресурсами: при использовании среды выполнения интеграции Azure можно указать до 256 единиц diUs для каждого действия копирования бессерверным образом. При использовании локальной среды выполнения интеграции можно вручную масштабировать компьютер или масштабировать до нескольких компьютеров (до четырех узлов), а одно действие копирования будет секционировать его набор файлов по всем узлам.
- Одно действие копирования считывает данные из хранилища данных и записывает их в него с помощью нескольких потоков.
- Поток управления Фабрики данных Azure может запускать несколько операций копирования параллельно, например с помощью цикла For Each.
Устойчивость
Фабрика данных Azure имеет встроенный механизм повтора в рамках одного действия копирования, позволяющий справляться с определенным количеством временных сбоев в хранилищах данных или в базовой сети.
При копировании двоичных данных из S3 в Хранилище BLOB-объектов и из S3 в ADLS 2-го поколения Фабрика данных Azure автоматически создает контрольные точки. Если при выполнении действия копирования происходит сбой или истекает время ожидания, при последующей попытке копирование возобновляется с последней точки сбоя, а не с начала.
Безопасность сети
По умолчанию Фабрика данных Azure передает данные из Amazon S3 в Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения через зашифрованное подключение по протоколу HTTPS. HTTPS обеспечивает шифрование данных при передаче и предотвращает прослушивание трафика и атаки типа "злоумышленник в середине".
Кроме того, если вы не хотите передавать данные через общедоступный Интернет, вы можете обеспечить более высокую безопасность путем передачи данных через частный пиринговый канал между AWS Direct Connect и Azure Express Route. Ознакомьтесь с архитектурой решения в следующем разделе о том, как это можно сделать.
Архитектура решения
Перенос данных через общедоступный Интернет:
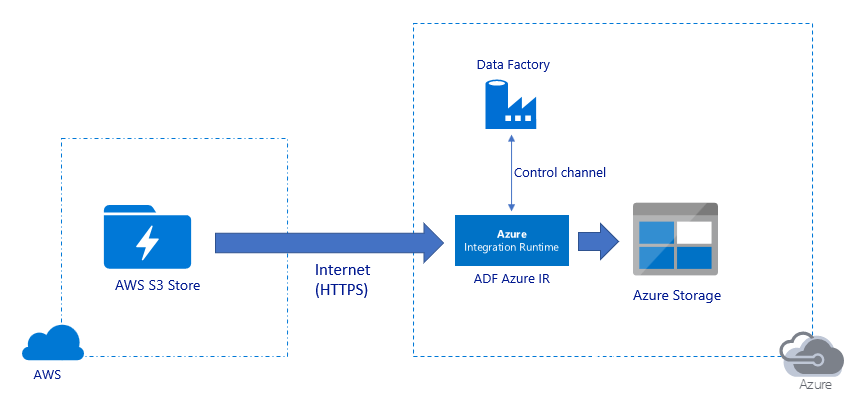
- В этой архитектуре данные безопасно передаются по протоколу HTTPS через общедоступный Интернет.
- Исходный Amazon S3 и целевой Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения настроены для разрешения трафика со всех сетевых IP-адресов. Дополнительные сведения о том, как ограничить сетевой доступ к определенному диапазону IP-адресов, см. далее на следующую страницу.
- Вы можете легко масштабировать ресурсы бессерверным образом, чтобы полностью использовать пропускную способность сети и хранилища с целью получения максимальной скорости передачи данных в среде.
- С помощью этой архитектуры можно обеспечить как перенос исходных моментальных снимков, так и перенос разностных данных.
Перенос данных через частный канал:

- В этой архитектуре перенос данных осуществляется через канал частного пиринга между AWS Direct Connect и Azure Express Route, так что данные никогда не передаются через общедоступный Интернет. Для этого требуется использовать AWS VPC и виртуальную сеть Azure.
- Для реализации этой архитектуры необходимо установить локальную среду выполнения интеграции Фабрики данных Azure на виртуальной машине Windows в виртуальной сети Azure. Вы можете вручную масштабировать локальные виртуальные машины IR или масштабировать их до нескольких виртуальных машин (до четырех узлов) для полного использования сетевых операций ввода-вывода в секунду или пропускной способности хранилища.
- С помощью этой архитектуры можно обеспечить как перенос исходных моментальных снимков, так и перенос разностных данных.
Рекомендации по реализации
Управление проверкой подлинности и учетными данными
- Для проверки подлинности учетной записи Amazon S3 необходимо использовать ключ доступа для учетной записи IAM.
- Для подключения к Хранилищу BLOB-объектов Azure поддерживаются несколько типов проверки подлинности. Использование управляемых удостоверений для ресурсов Azure настоятельно рекомендуется: на основе автоматически управляемого идентификатора ADF в идентификаторе Microsoft Entra можно настроить конвейеры без предоставления учетных данных в определении связанной службы. Кроме того, проверку подлинности в Хранилище BLOB-объектов Azure можно проходить, используя субъект-службу, подписанный URL-адрес или ключ учетной записи хранения.
- Для подключения к Azure Data Lake Storage 2-го поколения также поддерживаются несколько типов проверки подлинности. Настоятельно рекомендуется использовать управляемые удостоверения для ресурсов Azure, хотя также можно применять субъект-службу или ключ учетной записи хранения.
- Если вы не используете управляемые удостоверения для ресурсов Azure, настоятельно рекомендуется хранить учетные данные в Azure Key Vault , чтобы упростить централизованное управление и смену ключей без изменения связанных служб ADF. Это также одна из рекомендаций для CI/CD.
Перенос исходных моментальных снимков
Секционирование данных особенно рекомендуется при переносе более чем 100 ТБ данных. Чтобы секционировать данные, используйте параметр префикса для фильтрации папок и файлов в Amazon S3 по имени, а затем каждое задание копирования ADF может копировать одну секцию одновременно. Для повышения пропускной способности можно одновременно запустить несколько заданий копирования в Фабрике данных Azure.
Если какое-либо из заданий копирования завершится сбоем из-за временной проблемы с сетью или хранилищем данных, оно сможет повторно загрузить эту секцию из AWS S3. Все остальные задания копирования, загружаемые другими секциями, не будут затронуты.
Перенос разностных данных
Наиболее эффективно определить новые или измененные файлы из AWS S3 можно с помощью соглашения об именовании с секционированием по времени. Если данные в AWS S3 были секционированы с информацией о срезе времени в имени файла или папки (например, /y/mm/dd/file.csv), конвейер может легко определить, какие файлы и папки копируются постепенно.
Кроме того, если данные в AWS S3 не секционированы по времени, ADF может определить новые или измененные файлы с помощью lastModifiedDate. В этом случае Фабрика данных Azure будет сканировать все файлы в AWS S3 и копировать только новые и обновленные файлы, метка времени последнего изменения которых больше определенного значения. При наличии большого количества файлов в S3 начальное сканирование файлов может занять много времени независимо от того, сколько файлов соответствует условию фильтра. В этом случае рекомендуется сначала секционировать данные, используя тот же параметр префикса для начальной миграции моментальных снимков, чтобы сканирование файлов выполнялось параллельно.
Сценарии, для которых требуется локальная среда выполнения интеграции на виртуальной машине Azure
Независимо от того, переносите ли вы данные по приватной ссылке или хотите разрешить определенный диапазон IP-адресов в брандмауэре Amazon S3, необходимо установить локальную среду выполнения интеграции на виртуальной машине Windows Azure.
- Рекомендуемая начальная конфигурация для каждой виртуальной машины Azure — Standard_D32s_v3 с 32 виртуальными ЦП и 128 ГБ памяти. Вы можете отслеживать использование ЦП и памяти виртуальной машины среды выполнения интеграции во время переноса данных, чтобы узнать, нужно ли увеличить масштаб виртуальной машины для повышения производительности или уменьшить его, чтобы сократить затраты.
- Кроме того, можно масштабировать, связав до четырех узлов виртуальных машин с одной локальной средой ir. Одно задание копирования, выполняемое в локальной среде IR, автоматически секционирует набор файлов и использует все узлы виртуальной машины для параллельного копирования файлов. Для обеспечения высокой доступности рекомендуется начать с двух узлов виртуальной машины, чтобы избежать единой точки сбоя во время миграции данных.
Ограничение частоты
Рекомендуется провести оценку производительности с помощью репрезентативного образца набора данных, чтобы можно было определить подходящий размер секции.
Начните с одной секции и одного действия копирования с количеством единиц интеграции данных по умолчанию. Постепенно увеличивайте количество единиц интеграции данных, пока не будет достигнуто ограничение пропускной способности и скорости ввода-вывода сети или хранилищ данных либо максимальное количество единиц интеграции данных (256), разрешенное для одного действия копирования.
Затем постепенно увеличивайте количество одновременных действий копирования, пока не будет достигнут предел для вашей среды.
При возникновении ошибок регулирования, о которых сообщает действие копирования Фабрики данных Azure, уменьшите степень параллелизма или количество единиц интеграции данных в Фабрике данных Azure либо повысьте предельную пропускную способность и скорость ввода-вывода сети и хранилищ данных.
Оценка цены
Примечание.
Это гипотетический пример цен. Реальная цена зависит от фактической пропускной способности в среде.
Рассмотрим следующий конвейер, созданный для переноса данных из S3 в Хранилище BLOB-объектов Azure:

Предположим следующее.
- Общий объем данных составляет 2 ПБ.
- Данные переносятся по протоколу HTTPS с помощью первой архитектуры.
- 2 PB разделены на 1 КБ секций, и каждая копия перемещает одну секцию
- Для каждой копии настраивается 256 единиц интеграции данных и достигается пропускная способность 1 Гбит/с.
- Степень параллелизма ForEach имеет значение 2, а суммарная пропускная способность — 2 Гбит/с
- В итоге для завершения переноса потребуется 292 часа.
Ниже приведена оценка цены на основе приведенных выше предположений:

Дополнительная справка
- Соединитель Amazon Simple Storage Service
- Соединитель хранилища BLOB-объектов Azure
- Copy data to or from Azure Data Lake Storage Gen2 Preview using Azure Data Factory (Preview) (Копирование данных в Azure Data Lake Storage Gen2 (предварительная версия) или из него с помощью фабрики данных Azure)
- Руководство по настройке производительности действия копирования
- Создание и настройка локальной среды выполнения интеграции
- Высокая доступность и масштабируемость локальной среды выполнения интеграции
- Вопросы безопасности при перемещении данных
- Хранение учетных данных в Azure Key Vault
- Добавочное копирование файлов на основе имен файлов с разделением по времени
- Копирование новых и измененных файлов на основе LastModifiedDate
- Страница цен на Фабрику данных Azure
Template
Ниже приведен шаблон для переноса петабайт данных, состоящих из сотен миллионов файлов из Amazon S3 в Azure Data Lake Storage 2-го поколения.