Форматы файлов и кодеки сжатия, поддерживаемые в Фабрике данных Azure и Synapse Analytics (устаревшая версия)
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Данная статья применима к следующим соединителям: Amazon S3, Хранилище BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения, Файлы Azure, Файловая система, FTP, Google Cloud Storage, HDFS, HTTP и SFTP.
Внимание
Служба представила новую модель набора данных на основе формата, см. соответствующую статью формата с подробными сведениями:
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат JSON
- Формат ORC
- Формат Parquet
Остальные конфигурации, упомянутые в данной статье, по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Текстовый формат (устаревшая версия)
Примечание.
Изучите новую модель из статьи о текстовом формате с разделителями. Нижеприведенные конфигурации для набора данных хранилища данных на основе файлов по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Если вам нужно считать данные из текстового файла или записать в него данные, задайте для свойства type в разделе format набора данных значение TextFormat. В разделе format также можно указать следующие необязательные свойства. Инструкции по настройке см. в разделе Пример TextFormat.
| Свойство | Description | Допустимые значения | Обязательное поле |
|---|---|---|---|
| columnDelimiter | Знак, используемый для разделения столбцов в файле. Вы можете использовать редкие непечатаемые символы, которые не содержатся в ваших данных. Например, укажите "\u0001", что соответствует символу начала заголовка (SOH). | Допускается только один знак. Значение по умолчанию — запятая (,). Чтобы использовать символ Юникода, см. соответствующие коды в статье о символах Юникода. |
No |
| rowDelimiter | символ, используемый для разделения строк в файле. | Допускается только один знак. По умолчанию используется одно из следующих значений: для чтения — [\r\n, \r, \n], для записи — \r\n. | No |
| escapeChar | Специальный символ, используемый для экранирования разделителя столбцов в содержимом входного файла. Не следует указывать escapeChar и quoteChar для таблицы одновременно. |
Допускается только один знак. Нет значения по умолчанию. Пример: если у вас есть запятая (',') в качестве разделителя столбцов, но вы хотите, чтобы в тексте была запятая (пример: "Hello, world"), вы можете определить "$" в качестве escape-символа и использовать в коде строку "Hello$, world". |
No |
| quoteChar | Символ, используемый для заключения строкового значения в кавычки. Разделители столбцов и строк внутри знаков кавычек будут рассматриваться как часть строкового значения. Это свойство применяется к входному и выходному наборам данных. Не следует указывать escapeChar и quoteChar для таблицы одновременно. |
Допускается только один знак. Нет значения по умолчанию. Например, если в качестве разделителя столбцов используется запятая (,) и нужно, чтобы этот знак встречался в тексте (например, <Hello, world>), то можно в качестве знака кавычек определить двойную кавычку (") и использовать в исходном тексте строку "Hello, world". |
No |
| nullValue | один или несколько символов, используемых для представления значения NULL. | Один или несколько знаков. Значения по умолчанию: \N и NULL для чтения и \N для записи. | No |
| encodingName | задает имя кодировки. | Допустимое имя кодировки. Ознакомьтесь с описанием свойства Encoding.EncodingName. Пример: windows-1250 или shift_jis. По умолчанию используется UTF-8. | No |
| firstRowAsHeader | Указывает, следует ли рассматривать первую строки в качестве заголовка. Служба считывает первую строку входного набора данных как заголовок. Служба записывает первую строку как заголовок в выходной набор данных. Примеры сценариев см. в разделе Сценарии использования firstRowAsHeader и skipLineCount. |
Истина False (по умолчанию) |
No |
| skipLineCount | Указывает количество непустых строк, которые нужно пропустить при чтении данных из входных файлов. Если указаны skipLineCount и firstRowAsHeader, то сначала пропускаются строки, а затем считываются данные заголовка из входного файла. Примеры сценариев см. в разделе Сценарии использования firstRowAsHeader и skipLineCount. |
Целое число | No |
| treatEmptyAsNull | Указывает, следует ли интерпретировать NULL или пустую строку как значение NULL при считывании данных из входного файла. | True (по умолчанию) False |
No |
Пример TextFormat
В следующем определении JSON для набора данных задаются некоторые необязательные свойства.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Чтобы использовать escapeChar вместо quoteChar, замените строку с quoteChar следующим escape-символом:
"escapeChar": "$",
Сценарии использования firstRowAsHeader и skipLineCount
- Вы выполняете копирование из нефайлового источника в текстовый файл и хотите добавить строку заголовка, содержащую метаданные схемы (например, схемы SQL). В этом случае укажите
firstRowAsHeaderсо значением true в выходном наборе данных. - Вы копируете данные из текстового файла, содержащего строку заголовка, в нефайловый приемник и хотите удалить эту строку. Укажите
firstRowAsHeaderсо значением true во входном наборе данных. - Вы копируете данные из текстового файла и хотите пропустить несколько строк в начале, которые не содержат ни данных, ни заголовка. Укажите
skipLineCount, чтобы задать число пропускаемых строк. Если остальная часть файла содержит строку заголовка, можно также указатьfirstRowAsHeader. Если указаныskipLineCountиfirstRowAsHeader, сначала пропускаются строки, а затем из входного файла считываются данные заголовка.
Формат JSON (устаревшая версия)
Примечание.
Изучите новую модель из статьи о формате JSON. Нижеприведенные конфигурации для набора данных хранилища данных на основе файлов по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Чтобы импортировать JSON-файл "как есть" в базу данных Azure Cosmos DB или экспортировать его из нее, см. раздел "Документы JSON для импорта и экспорта" статьи о перемещении данных в базу данных Azure Cosmos DB и из нее.
Если требуется проанализировать JSON-файлы или записать данные в формате JSON, задайте для свойства type в разделе format значение JsonFormat. В разделе format также можно указать следующие необязательные свойства. Инструкции по настройке см. в разделе Пример JsonFormat.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| filePattern | Шаблон данных, хранящихся в каждом JSON-файле. Допустимые значения: setOfObjects и arrayOfObjects. Значение по умолчанию — setOfObjects. Подробные сведения об этих шаблонах см. в разделе Шаблоны файлов JSON. | No |
| jsonNodeReference | Для итерации и извлечения данных из объектов в поле массива с таким же шаблоном укажите путь JSON этого массива. Это свойство поддерживается только в том случае, если данные копируются из JSON-файлов. | No |
| jsonPathDefinition | Выражение пути JSON для каждого столбца с его сопоставлением с настраиваемым именем столбца (начало в нижнем регистре). Это свойство поддерживается только в том случае, если данные копируются из JSON-файлов и данные можно извлечь из объекта или массива. Для полей в области корневого объекта выражение пути должно начинаться с корня $. Для полей внутри массива, выбранных с помощью свойства jsonNodeReference, выражение должно начинаться с элемента массива. Инструкции по настройке см. в разделе Пример JsonFormat. |
No |
| encodingName | задает имя кодировки. Список допустимых имен кодировок приведен в описании свойства Encoding.EncodingName. Например: windows-1250 или shift_jis. По умолчанию используется UTF-8. | No |
| nestingSeparator | Символ, используемый для разделения уровней вложенности. Значение по умолчанию — точка (.). | No |
Примечание.
В случае перекрестного применения данных в массиве в несколько строк (случай 1 > выборка 2 в примерах JsonFormat) вы можете развернуть только один массив с помощью свойства jsonNodeReference.
Шаблоны файлов JSON
Действие копирования может проанализировать следующие шаблоны JSON-файлов.
Тип 1: setOfObjects
Каждый файл содержит один объект или несколько разделенных строками или объединенных объектов. Если этот параметр выбран в выходном наборе данных, то в результате копирования будет создан JSON-файл, где каждый объект будет находиться в отдельной строке (файл с разделителем-строкой).
Пример единого объекта JSON
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Пример JSON-файла с разделителем-строкой
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Пример объединенного JSON-файла
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Тип 2: arrayOfObjects
Каждый файл содержит массив объектов.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Пример JsonFormat
Вариант 1. Копирование данных из JSON-файлов
Пример 1. Извлечение данных из объекта и массива
В этом примере предполагается, что один корневой объект JSON соответствует одной записи в таблице результатов. Если у вас есть JSON-файл со следующим содержимым:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
и вы хотите скопировать это содержимое (посредством извлечения данных из объекта и массива) в таблицу SQL Azure в следующем формате:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
Входной набор данных с типом JsonFormat определяется следующим образом (частичное определение только соответствующих частей). В частности:
- Раздел
structureопределяет настраиваемые имена столбцов и соответствующие типы данных при преобразовании в табличные данные. Этот раздел является необязательным, если вам не нужно сопоставлять столбцы. Дополнительные сведения см. в статье о сопоставлении столбцов исходного набора данных со столбцами целевого набора данных. jsonPathDefinitionуказывает путь к файлу JSON для каждого столбца, который определяет, откуда следует извлекать данные. Чтобы скопировать данные из массива, с помощьюarray[x].propertyможно извлечь значение нужного свойства из объектаxthили с помощьюarray[*].propertyнайти нужное значение в любом объекте с таким свойством.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Пример 2. Применение нескольких объектов с одинаковым шаблоном из массива
В этом примере предполагается, что один корневой объект JSON будет преобразован в несколько записей в таблице результатов. Если у вас есть JSON-файл со следующим содержимым:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
И если вы хотите скопировать этот файл в таблицу Azure SQL в следующем формате путем сведения данных внутри массива и перекрестного соединения с общими сведениями о корневом объекте:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
Входной набор данных с типом JsonFormat определяется следующим образом (частичное определение только соответствующих частей). В частности:
- Раздел
structureопределяет настраиваемые имена столбцов и соответствующие типы данных при преобразовании в табличные данные. Этот раздел является необязательным, если вам не нужно сопоставлять столбцы. Дополнительные сведения см. в статье о сопоставлении столбцов исходного набора данных со столбцами целевого набора данных. jsonNodeReferenceуказывает на итерацию и извлечение данных из объектов с тем же шаблоном в массивеorderlines.jsonPathDefinitionуказывает путь к файлу JSON для каждого столбца, который определяет, откуда следует извлекать данные. В этом примереordernumber,orderdateиcityрасположены в корневом объекте. Путь JSON к нему начинается с$., аorder_pdиorder_priceопределяются с помощью пути, производного от элемента массива без$..
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Обратите внимание на следующие моменты.
- Если параметры
structureиjsonPathDefinitionне определены в наборе данных, то действие Copy обнаружит схему из первого объекта и выполнит сведение всего объекта. - Если входной JSON-файл содержит массив, по умолчанию действие копирования преобразует все значение массива в строку. Вы можете извлечь данные из строки с помощью
jsonNodeReferenceилиjsonPathDefinition. Или можно пропустить строку, не указывая ее вjsonPathDefinition. - Если на том же уровне существует повторяющиеся имена, то действие копирования выберет последнее из них.
- В именах свойств учитывается регистр. Два свойства с одинаковым именем, но в разных регистрах, рассматриваются как два отдельных свойства.
Вариант 2. Запись данных в JSON-файл
Если в базе данных SQL есть следующая таблица:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | Дэвид |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
и для каждой записи вы предполагаете запись в объект JSON в следующем формате:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
Выходной набор данных с типом JsonFormat определяется следующим образом (частичное определение только соответствующих частей). В частности, раздел structure определяет настраиваемые имена свойств в конечном файле. Для определения уровня вложенности от имен будет использоваться разделитель вложенности nestingSeparator (по умолчанию — точка (.)). Этот раздел является необязательным, если вы не собираетесь изменять исходное имя свойства или вкладывать свойства.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Формат Parquet (устаревшая версия)
Примечание.
Ознакомьтесь с новой моделью из статьи Формат Parquet. Нижеприведенные конфигурации для набора данных хранилища данных на основе файлов по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Если вы хотите проанализировать файлы Parquet или записать данные в формате Parquet, задайте format type для свойства значение ParquetFormat. Вам не нужно указывать какие-либо свойства в подразделе Format раздела typeProperties. Пример:
"format":
{
"type": "ParquetFormat"
}
Обратите внимание на следующие аспекты:
- Данные сложных типов (MAP, LIST) не поддерживаются.
- Пробелы в именах столбцов не поддерживаются.
- Parquet-файл имеет следующие варианты сжатия: NONE, SNAPPY, GZIP и LZO. Служба поддерживает чтение данных из PARQUET-файла в любом из указанных форматов сжатия за исключением LZO, в котором для чтения данных используется кодек сжатия, указанный в метаданных. Однако при записи в PARQUET-файл служба по умолчанию выбирает SNAPPY. В настоящее время изменить это поведение нельзя.
Внимание
Для копирования посредством локальной среды выполнения интеграции (IR), то есть между локальным и облачным хранилищами данных, если вы не копируете файлы Parquet как есть, на компьютере среды выполнения интеграции необходимо установить 64-разрядную JRE 8 (среду выполнения Java) или OpenJDK. Подробные сведения приведены в следующем абзаце.
Для копирования, запущенного в локальной среде IR с сериализацией/десериализацией файлов Parquet, служба определяет местонахождение среды выполнения Java, сначала проверяя реестр (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) на наличие JRE, если он не найден, после чего проверяя системную переменную JAVA_HOME для OpenJDK.
- Для использования JRE: для 64-разрядного IR требуется 64-разрядная JRE. Ее можно найти здесь.
- Для использования OpenJDK: он поддерживается в среде выполнения интеграции, начиная с версии 3.13. Упакуйте jvm.dll со всеми другими необходимыми сборками OpenJDK на компьютере с локальной IR и соответственно установите системную переменную среды JAVA_HOME.
Совет
Если вы копируете данные в формат Parquet или из формата Parquet с помощью локальной среди выполнения интеграции и возникает ошибка: "Ошибка при вызове Java, сообщение: java.lang.OutOfMemoryError:Java heap space", можно добавить переменную среды _JAVA_OPTIONS в компьютере, на котором размещена локальная среда выполнения интеграции для настройки минимального и максимального размера кучи для виртуальной машины Java, чтобы расширить возможности такой копии, а затем повторно запустить конвейер.
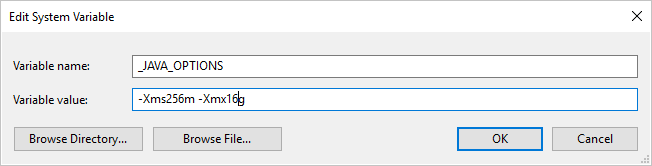
Пример: задайте переменную _JAVA_OPTIONS со значением -Xms256m -Xmx16g. Флаг Xms указывает начальный пул выделения памяти для виртуальной машины Java (JVM), а Xmx указывает максимальный пул выделения памяти. Это означает, что JVM будет запущена с объемом памяти Xms и сможет использовать не более Xmx объема памяти. По умолчанию служба использует минимум 64 МБ и максимум 1 ГБ.
Сопоставление типов данных для файлов Parquet
| Промежуточный тип данных службы | Тип-примитив Parquet | Исходный тип Parquet (десериализация) | Исходный тип Parquet (сериализация) |
|---|---|---|---|
| Логический | Логический | Неприменимо | Неприменимо |
| SByte | Int32 | Int8 | Int8 |
| Байт | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Binary или Int64 | UInt64 | Десятичное число |
| Одна | Тип с плавающей запятой | Неприменимо | Неприменимо |
| Двойной | Двойной | Неприменимо | Неприменимо |
| Десятичное число | Binary | Десятичное число | Десятичное |
| Строка | Binary | Utf8 | Utf8 |
| Дата/время | Int96 | Неприменимо | Неприменимо |
| TimeSpan | Int96 | Неприменимо | Неприменимо |
| DateTimeOffset | Int96 | Неприменимо | Неприменимо |
| ByteArray | Binary | Неприменимо | Неприменимо |
| GUID | Binary | Utf8 | Utf8 |
| Char | Binary | Utf8 | Utf8 |
| CharArray | Не поддерживается | Неприменимо | Неприменимо |
Формат ORC (устаревшая версия)
Примечание.
Изучите новую модель из статьи о формате ORC. Нижеприведенные конфигурации для набора данных хранилища данных на основе файлов по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Если вы хотите проанализировать файлы ORC или записать данные в формате ORC, задайте format type для свойства значение OrcFormat. Вам не нужно указывать какие-либо свойства в подразделе Format раздела typeProperties. Пример:
"format":
{
"type": "OrcFormat"
}
Обратите внимание на следующие аспекты:
- Данные сложных типов (STRUCT, MAP, LIST, UNION) не поддерживаются.
- Пробелы в именах столбцов не поддерживаются.
- Для ORC-файлов используется три параметра сжатия: NONE, ZLIB и SNAPPY. Служба поддерживает чтение данных из ORC-файла в любом из этих форматов. Для чтения данных используется кодек сжатия из метаданных. Однако при записи в ORC-файл служба по умолчанию выбирает ZLIB. В настоящее время изменить это поведение нельзя.
Внимание
Для копирования посредством локальной среды выполнения интеграции (IR), то есть между локальным и облачным хранилищами данных, если вы не копируете файлы ORC как есть, на компьютере среды выполнения интеграции необходимо установить 64-разрядную JRE 8 (среда выполнения Java) или OpenJDK. Подробные сведения приведены в следующем абзаце.
Для копирования, запущенного в локальной среде IR с сериализацией и десериализацией ORC-файлов Parquet, служба определяет местонахождение среды выполнения Java, сначала проверяя реестр (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) на наличие пакета JRE, если он не найден, после чего проверяя системную переменную JAVA_HOME для OpenJDK.
- Для использования JRE: для 64-разрядного IR требуется 64-разрядная JRE. Ее можно найти здесь.
- Для использования OpenJDK: он поддерживается в среде выполнения интеграции, начиная с версии 3.13. Упакуйте jvm.dll со всеми другими необходимыми сборками OpenJDK на компьютере с локальной IR и соответственно установите системную переменную среды JAVA_HOME.
Сопоставление типов данных для ORC-файлов
| Промежуточный тип данных службы | Типы ORC |
|---|---|
| Логический | Логический |
| SByte | Байт |
| Байт | Короткие |
| Int16 | Короткие |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | Строка |
| Одна | Тип с плавающей запятой |
| Двойной | Двойной |
| Десятичное число | Десятичное |
| Строка | Строка |
| Дата/время | Метка времени |
| DateTimeOffset | Метка времени |
| TimeSpan | Метка времени |
| ByteArray | Binary |
| GUID | Строка |
| Char | Char(1) |
Формат AVRO (устаревшая версия)
Примечание.
Узнайте о новой модели из статьи о формате Avro. Нижеприведенные конфигурации для набора данных хранилища данных на основе файлов по-прежнему поддерживаются как есть для обеспечения обратной совместимости. В дальнейшем предлагается использовать новую модель.
Если вы хотите проанализировать файлы Avro или записать данные в формате Avro, задайте format type для свойства значение AvroFormat. Вам не нужно указывать какие-либо свойства в подразделе Format раздела typeProperties. Пример:
"format":
{
"type": "AvroFormat",
}
О том, как пользоваться форматом Avro в таблице Hive, можно узнать из руководства по Apache Hive.
Обратите внимание на следующие аспекты:
- Сложные типы данных (записи, перечисления, массивы, сопоставления, объединения и фиксированные данные) не поддерживаются.
Поддержка сжатия (устаревшая версия)
Служба поддерживает сжатие и распаковку данных во время копирования. Если вы указываете свойство compression во входном наборе данных, действие копирования читает сжатые файлы из источника и распаковывает их. При указании этого свойства в выходном наборе данных действие копирования сжимает, а затем записывает данные в приемник. Ниже приведено несколько примеров сценариев:
- Чтение сжатых данных GZIP из большого двоичного объекта Azure, их распаковка и запись данных результатов в базу данных SQL Azure. Вы определяете входной набор данных больших двоичных объектов Azure с помощью свойства
compressiontypeкак GZIP. - Считайте данные из обычного текстового файла в локальной файловой системе, сожмите их в формате GZip и запишите сжатые данные в BLOB-объект Azure. Вы определяете входной набор данных больших двоичных объектов Azure с помощью свойства
compressiontypeкак GZIP. - Считайте ZIP-файл с FTP-сервера, распакуйте его, чтобы получить содержащиеся в нем файлы, и отправьте их в хранилище Azure Data Lake Store. Вы определяете входной набор данных FTP с помощью свойства
compressiontypeкак ZipDeflate. - Считайте сжатые с помощью кодека GZIP данные из BLOB-объекта Azure, распакуйте их и сожмите с помощью BZIP2, а затем запишите результирующие данные в BLOB-объект Azure. Вы определяете входной набор данных Azure Blob с
compressiontype, установленным на GZIP, а выходной набор данных сcompressiontype, установленным на BZIP2.
Чтобы указать сжатие для набора данных, используйте свойство compression в наборе данных JSON, как показано в следующем примере.
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Раздел compression содержит два свойства:
Type — кодек сжатия. Возможные значения: GZIP, Deflate, BZIP2 или ZipDeflate. Обратите внимание, что при использовании операции копирования для распаковки файлов ZipDeflate и записи в хранилище данных приемника на основе файлов файлы будут извлечены в папку:
<path specified in dataset>/<folder named as source zip file>/.Level — коэффициент сжатия; возможные значения: Optimal и Fastest.
Fastest: операция сжатия должна выполняться как можно быстрее, даже если итоговый файл будет сжат не оптимально.
Optimal: операция сжатия должна выполняться оптимально, даже если для ее завершения требуется больше времени.
Дополнительные сведения см. в разделе Уровень сжатия.
Примечание.
Параметры сжатия для данных в форматах AvroFormat, OrcFormat или ParquetFormat не поддерживаются. Для чтения данных в этих форматах служба выявляет и использует в метаданных кодек сжатия. При записи в файл в одном из этих форматов служба выбирает кодек сжатия по умолчанию для этого формата. Например, ZLIB для OrcFormat и SNAPPY для ParquetFormat.
Неподдерживаемые типы файлов и форматы сжатия
Вы можете использовать функции расширяемости для преобразования файлов, которые не поддерживаются. Два варианта включают функции Azure и настраиваемые задачи при помощи пакетной службы Azure.
Вы можете увидеть пример, в котором функция Azure используется для извлечения содержимого tar-файла. Дополнительные сведения см. в разделе Действия с функциями Azure.
Вы также можете создать данную функциональность при помощи настраиваемого действия dotnet. С дополнительной информацией можно ознакомиться здесь
Связанный контент
Узнайте о последних поддерживаемых форматах файлов и сжатиях в разделе Поддерживаемые форматы файлов и сжатия.