RAG (получение дополненного поколения) в Azure Databricks
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Agent Framework состоит из набора средств для Databricks, предназначенных для создания, развертывания и оценки агентов ИИ для производства, таких как приложения получения дополненного поколения (RAG).
В этой статье описывается, что такое RAG и преимущества разработки приложений RAG в Azure Databricks.
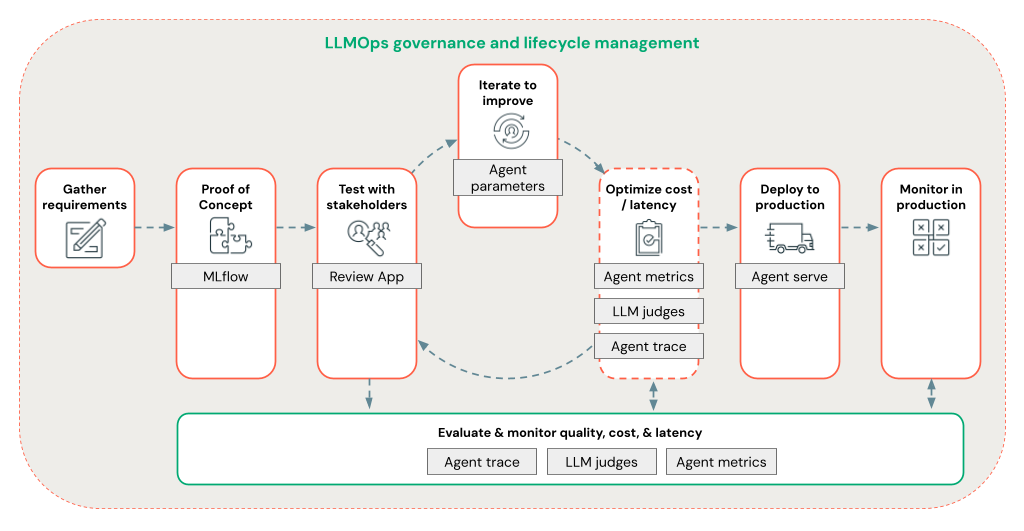
Agent Framework позволяет разработчикам быстро выполнять итерацию по всем аспектам разработки RAG с помощью комплексного рабочего процесса LLMOps.
Требования
- Вспомогательные функции ИИ на основе ИИ Azure должны быть включены для рабочей области.
- Все компоненты агентического приложения должны находиться в одной рабочей области. Например, в случае приложения RAG модель обслуживания и экземпляр векторного поиска должны находиться в одной рабочей области.
Что такое RAG?
RAG — это метод разработки искусственного интеллекта, который улучшает большие языковые модели (LLM) с внешними знаниями. Этот метод улучшает LLM следующим образом:
- Собственные знания: RAG может включать в себя частную информацию, которая изначально не используется для обучения LLM, таких как заметки, сообщения электронной почты и документы для ответа на вопросы, относящиеся к домену.
- Актуальные сведения: приложение RAG может предоставить LLM с информацией из обновленных источников данных.
- Ссылаясь на источники: RAG позволяет LLM ссылаться на определенные источники, позволяя пользователям проверять фактическую точность ответов.
- Списки управления безопасностью и доступом данных (ACL): шаг извлечения может быть разработан для выборочного получения персональных или частных сведений на основе учетных данных пользователя.
Составные системы ИИ
Приложение RAG является примером составной системы ИИ: он расширяет возможности языка LLM путем объединения его с другими инструментами и процедурами.
В простейшей форме приложение RAG выполняет следующие действия:
- Получение: запрос пользователя используется для запроса внешнего хранилища данных, например векторного хранилища, поиска текстового ключевого слова или базы данных SQL. Цель — получить вспомогательные данные для ответа LLM.
- Расширение. Извлеченные данные объединяются с запросом пользователя, часто используя шаблон с дополнительным форматированием и инструкциями для создания запроса.
- Поколение: запрос передается в LLM, который затем создает ответ на запрос.
Неструктурированные и структурированные данные RAG
Архитектура RAG может работать с неструктурированными или структурированными вспомогательными данными. Данные, используемые с RAG, зависят от вашего варианта использования.
Неструктурированные данные: данные без определенной структуры или организации. Документы, содержащие текст и изображения или мультимедийное содержимое, например аудио или видео.
- PDF-файлы
- Документы Google и Office
- Вики-страницы
- Изображения
- Видео
Структурированные данные: табличные данные, расположенные в строках и столбцах с определенной схемой, например таблицы в базе данных.
- Записи клиентов в системе бизнес-аналитики или хранилища данных
- Данные транзакций из базы данных SQL
- Данные из API приложений (например, SAP, Salesforce и т. д.)
В следующих разделах описывается приложение RAG для неструктурированных данных.
Конвейер данных RAG
Конвейер данных RAG предварительно обрабатывает и индексирует документы для быстрого и точного извлечения.
На схеме ниже показан пример конвейера данных для неструктурированного набора данных с помощью алгоритма семантического поиска. Databricks Jobs оркеструет каждый шаг.
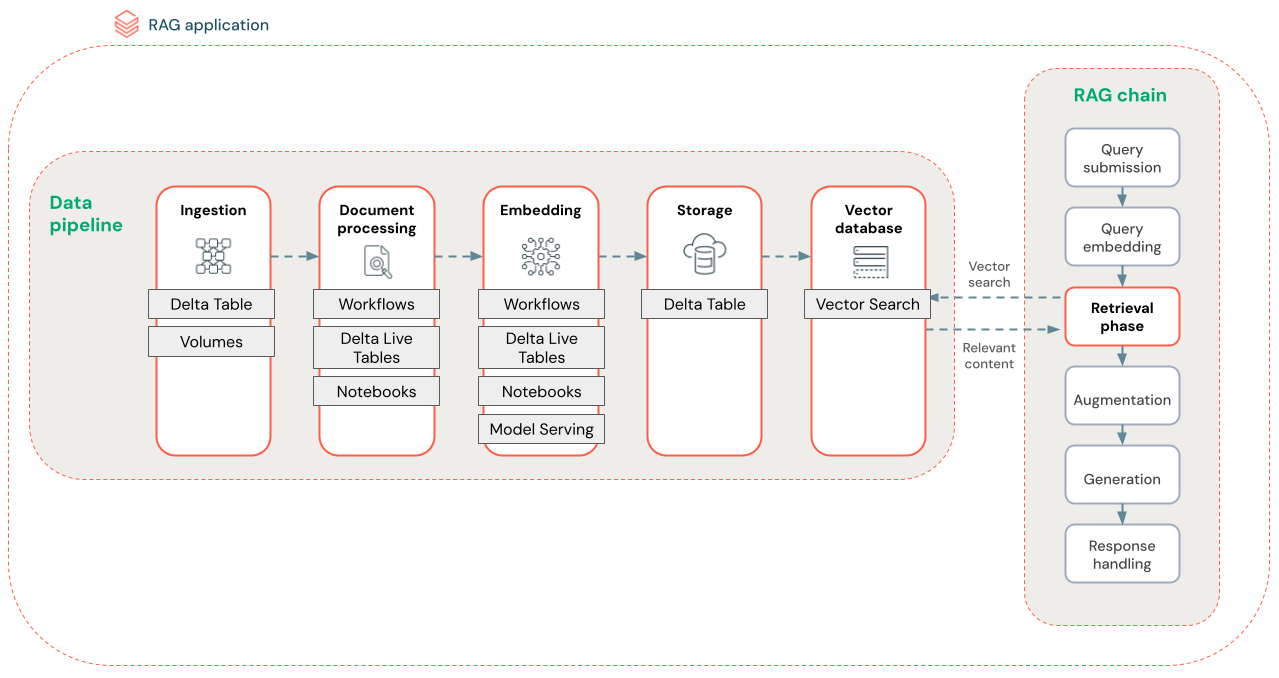
- Прием данных — прием данных из собственного источника. Сохраните эти данные в разностной таблице или томе каталога Unity.
- Обработка документов. Эти задачи можно выполнять с помощью заданий Databricks, записных книжек Databricks и разностных динамических таблиц.
- Анализ необработанных документов: преобразование необработанных данных в доступный формат. Например, извлечение текста, таблиц и изображений из коллекции PDF-файлов или использование методов оптического распознавания символов для извлечения текста из изображений.
- Извлечение метаданных: извлечение метаданных документа, таких как заголовки документов, номера страниц и URL-адреса, чтобы получить запрос на шаг более точно.
- Документы блока. Разделение данных на блоки, которые помещаются в окно контекста LLM. Получение этих ориентированных фрагментов, а не целых документов, дает LLM более целевое содержимое для создания ответов.
- Внедрение блоков — модель внедрения использует блоки для создания числовых представлений информации, называемой векторными внедрениями. Векторы представляют семантический смысл текста, а не только ключевые слова уровня поверхности. В этом сценарии вы вычисляете внедрение и используете модель обслуживания для обслуживания модели внедрения.
- Внедрение хранилища . Сохраните векторные внедрения и текст блока в таблице Delta, синхронизированной с векторным поиском.
- Векторная база данных — в рамках векторного поиска внедрение и метаданные индексируются и хранятся в векторной базе данных для простого запроса агентом RAG. Когда пользователь выполняет запрос, его запрос внедряется в вектор. Затем база данных использует векторный индекс для поиска и возврата наиболее похожих блоков.
Каждый шаг включает в себя инженерные решения, влияющие на качество приложения RAG. Например, выбор правильного размера блока на шаге (3) гарантирует, что LLM получает определенную контекстуализованную информацию, при выборе соответствующей модели внедрения на шаге (4) определяет точность блоков, возвращаемых во время извлечения.
Поиск вектора Databricks
Вычисление сходства часто является дорогостоящим вычислением, но векторные индексы, такие как Databricks Vector Search оптимизируют это путем эффективного упорядочения внедрения. Векторный поиск быстро ранжируют наиболее релевантные результаты без сравнения каждого внедрения в запрос пользователя по отдельности.
Векторный поиск автоматически синхронизирует новые внедрения, добавленные в таблицу Delta, и обновляет индекс векторного поиска.
Что такое агент RAG?
Агент получения дополненного поколения (RAG) является ключевой частью приложения RAG, которое улучшает возможности больших языковых моделей (LLMs), интегрируя извлечение внешних данных. Агент RAG обрабатывает запросы пользователей, извлекает соответствующие данные из векторной базы данных и передает эти данные в LLM для создания ответа.
Такие инструменты, как LangChain или Pyfunc, связывают эти действия, подключая входные и выходные данные.
На схеме ниже показан агент RAG для чат-бота и функций Databricks, используемых для создания каждого агента.
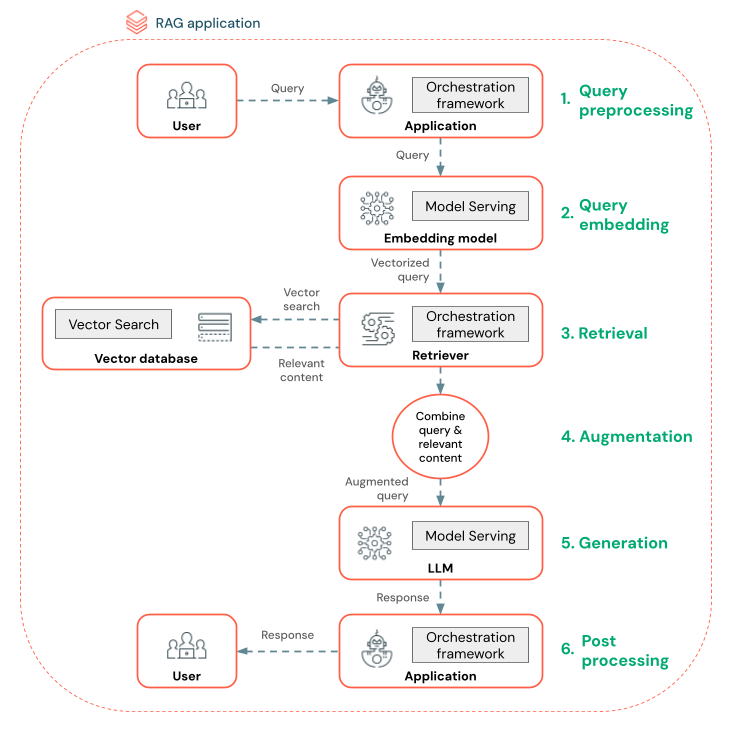
- Предварительная обработка запроса — пользователь отправляет запрос, который затем предварительно обрабатывается, чтобы сделать его подходящим для запроса векторной базы данных. Это может включать размещение запроса в шаблоне или извлечение ключевых слов.
- Векторизация запросов — используйте службу моделей для внедрения запроса с помощью той же модели внедрения, используемой для внедрения блоков в конвейер данных. Эти внедрения позволяют сравнить семантику сходства между запросом и предварительно обработанными блоками.
- Этап извлечения — извлекатель, приложение, ответственное за получение соответствующих сведений, принимает векторный запрос и выполняет поиск по сходства векторов с помощью векторного поиска. Наиболее релевантные блоки данных ранжируются и извлекаются на основе их сходства с запросом.
- Расширение запроса — извлекатель объединяет извлеченные блоки данных с исходным запросом, чтобы предоставить дополнительный контекст LLM. Запрос тщательно структурирован, чтобы убедиться, что LLM понимает контекст запроса. Часто LLM имеет шаблон для форматирования ответа. Этот процесс настройки запроса называется проектированием запросов.
- Этап создания LLM — LLM создает ответ с помощью дополненного запроса, обогащенного результатами извлечения. LLM может быть пользовательской моделью или базовой моделью.
- После обработки — ответ LLM может обрабатываться для применения дополнительной бизнес-логики, добавления ссылок или уточнения созданного текста на основе предопределенных правил или ограничений.
На протяжении всего этого процесса могут применяться различные охранники, чтобы обеспечить соответствие корпоративным политикам. Это может включать фильтрацию для соответствующих запросов, проверку разрешений пользователей перед доступом к источникам данных и использование методов con режим палатки ration в созданных ответах.
Разработка агента RAG на уровне рабочей среды
Быстро выполните итерацию по разработке агента с помощью следующих функций:
Создание и ведение журналов агентов с помощью любой библиотеки и MLflow. Параметризируйте агенты, чтобы быстро экспериментировать и выполнять итерацию по разработке агентов.
Развертывание агентов в рабочей среде с собственной поддержкой потоковой передачи маркеров и ведения журнала запросов и ответов, а также встроенное приложение проверки для получения отзывов пользователей для агента.
Трассировка агента позволяет выполнять журнал, анализ и сравнение трассировок в коде агента для отладки и понимания того, как агент отвечает на запросы.
Оценка и мониторинг
Оценка и мониторинг помогают определить, соответствует ли приложение RAG требованиям к качеству, стоимости и задержке. Оценка происходит во время разработки, а мониторинг происходит после развертывания приложения в рабочей среде.
RAG по неструктурированным данным имеет множество компонентов, влияющих на качество. Например, изменения форматирования данных могут повлиять на полученные блоки и способность LLM создавать соответствующие ответы. Поэтому важно оценить отдельные компоненты в дополнение к общему приложению.
Дополнительные сведения см. в разделе "Что такое оценка агента ИИ Мозаики?".
Доступность по регионам
Сведения о региональной доступности Agent Framework см. в разделе "Функции с ограниченной региональной доступностью"