Использование Delta Lake в Azure HDInsight в AKS с кластером Apache Spark™ (предварительная версия)
Примечание.
Мы отставим Azure HDInsight в AKS 31 января 2025 г. До 31 января 2025 г. необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого прекращения рабочих нагрузок. Оставшиеся кластеры в подписке будут остановлены и удалены из узла.
До даты выхода на пенсию будет доступна только базовая поддержка.
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
Azure HDInsight в AKS — это управляемая облачная служба для аналитики больших данных, которая помогает организациям обрабатывать большие объемы данных. В этом руководстве показано, как использовать Delta Lake в Azure HDInsight в AKS с кластером Apache Spark™.
Предварительные требования
Создание кластера Apache Spark™ в Azure HDInsight в AKS

Запустите сценарий Delta Lake в Jupyter Notebook. Создайте записную книжку Jupyter и выберите "Spark" при создании записной книжки, так как в следующем примере используется Scala.



Сценарий
- Чтение формата данных NYC Taxi Parquet — список URL-адресов файлов Parquet предоставляются из Комиссии по такси и лимузину Нью-Йорка.
- Для каждого URL-адреса (файла) выполняется некоторое преобразование и хранение в разностном формате.
- Вычислить среднее расстояние, среднюю стоимость за милю и среднюю стоимость из разностной таблицы с помощью добавочной нагрузки.
- Сохраните вычисленное значение из шага 3 в разностном формате в папку вывода ключевого показателя эффективности.
- Создайте папку выходных данных Delta Table в разностном формате (автоматическое обновление).
- В выходной папке KPI имеется несколько версий среднего расстояния и средняя стоимость за милю для поездки.
Предоставление необходимых конфигураций для разностного озера
Delta Lake с матрицой совместимости Apache Spark — Delta Lake, измените версию Delta Lake на основе версии Apache Spark.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Вывод списка файлов данных
Примечание.
Эти URL-адреса файлов относятся к NYC Taxi и Лимузин Комиссии.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Создание выходного каталога
Расположение, в котором нужно создать выходные данные разностного формата, при необходимости измените transformDeltaOutputPath и avgDeltaOutputKPIPath переменную.
avgDeltaOutputKPIPath— для хранения среднего ключевого показателя эффективности в разностном форматеtransformDeltaOutputPath— хранение преобразованных выходных данных в разностном формате
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Создание данных разностного формата из формата Parquet
Входные данные — из места, из
listOfDataFileкоторого скачанные данные https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pageЧтобы продемонстрировать путешествие по времени и версию, загрузите данные по отдельности
Выполните преобразование и вычисление следующего бизнес-ключевого показателя эффективности при добавочной нагрузке:
- Среднее расстояние
- Средняя стоимость за милю
- Средняя стоимость
Сохранение преобразованных и ключевых показателей эффективности данных в разностном формате
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Чтение разностного формата с помощью разностной таблицы
- чтение преобразованных данных
- чтение данных ключевого показателя эффективности
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Схема печати
- Печать схемы разностной таблицы для преобразованных и средних данных ключевого показателя эффективности1.
// tranform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema
Отображение последнего вычисляемого ключевого показателя эффективности из таблицы данных
dtAvgKpi.toDF.show(false)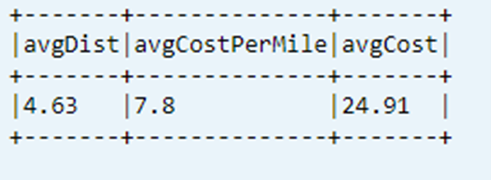


Отображение журнала вычисляемых ключевых показателей эффективности
На этом шаге отображается журнал таблицы транзакций ключевого показателя эффективности из _delta_log
dtAvgKpi.history().show(false)

Отображение данных ключевого показателя эффективности после каждой загрузки данных
- С помощью перемещения по времени можно просмотреть изменения ключевого показателя эффективности после каждой загрузки
- Вы можете сохранить все изменения версий в формате
avgMoMKPIChangePathCSV, чтобы Power BI могли считывать эти изменения.
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Справочные материалы
- Apache, Apache Spark, Spark и связанные открытый код имена проектов являются товарными знаками Apache Software Foundation (ASF).