Краткое руководство. Создание кластера Apache Spark в Azure HDInsight с помощью шаблона ARM
Из этого краткого руководства вы узнаете, как с помощью шаблона Azure Resource Manager (шаблон ARM) создать кластер Apache Spark в Azure HDInsight. Затем вы создадите файл Jupyter Notebook и с его помощью выполним SQL-запрос Spark к таблицам Apache Hive. Azure HDInsight — это управляемая комплексная служба аналитики с открытым кодом, предназначенная для предприятий. Платформа Apache Spark для HDInsight обеспечивает быструю аналитику данных и кластерные вычисления, используя обработку в памяти. Jupyter Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
Если вы используете несколько кластеров вместе, вам нужно создать виртуальную сеть. Если же вы используете кластер Spark, вы также можете использовать Hive Warehouse Connector. См. сведения о планировании виртуальной сети для Azure HDInsight и интеграции Apache Spark и Apache Hive с Hive Warehouse Connector.
Шаблон Azure Resource Manager — это файл нотации объектов JavaScript (JSON), который определяет инфраструктуру и конфигурацию проекта. В шаблоне используется декларативный синтаксис. Вы описываете предполагаемое развертывание без написания последовательности команд программирования для создания развертывания.
Если среда соответствует предварительным требованиям и вы знакомы с использованием шаблонов ARM, нажмите кнопку Развертывание в Azure. Шаблон откроется на портале Azure.

Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Изучение шаблона
Шаблон, используемый в этом кратком руководстве, взят из шаблонов быстрого запуска Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
В шаблоне определено два ресурса Azure:
- С помощью Microsoft.Storage/storageAccounts создается учетная запись хранения Azure.
- С помощью Microsoft.HDInsight/cluster создается кластер HDInsight.
Развертывание шаблона
Нажмите кнопку Развертывание в Azure ниже, чтобы войти в Azure и открыть шаблон ARM.
Введите или выберите следующие значения:
Свойство Описание Подписка В раскрывающемся списке выберите подписку Azure, которая используется для кластера. Группа ресурсов В раскрывающемся списке выберите существующую группу ресурсов, а затем Создать новую. Расположение В качестве значения будет автоматически указано расположение, используемое для группы ресурсов. Имя кластера Введите глобально уникальное имя. Для этого шаблона вы можете использовать только строчные буквы и цифры. Имя пользователя для входа в кластер Укажите имя пользователя, значение по умолчанию admin.Пароль для входа в кластер Введите пароль. Пароль должен содержать по крайней мере 10 символов в длину и содержать по крайней мере одну цифру, один верхний регистр и одну строчную букву, одну буквенно-цифровые символы (за исключением символов ' ` ").Имя пользователя SSH Укажите имя пользователя, значение по умолчанию sshuser.Пароль SSH Укажите пароль. 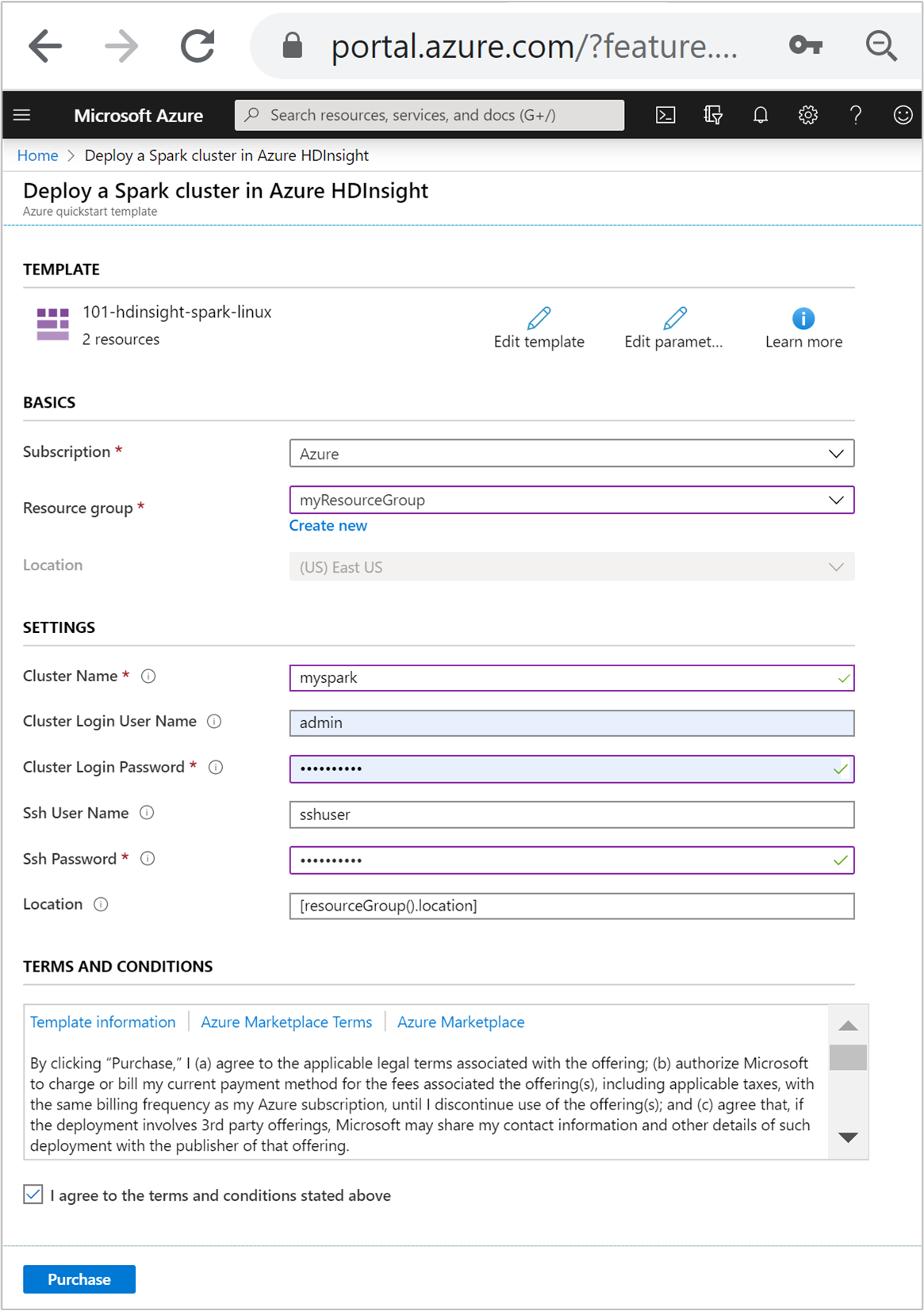
Ознакомьтесь с УСЛОВИЯМИ ИСПОЛЬЗОВАНИЯ. Затем установите флажок Я принимаю указанные выше условия и нажмите кнопку Приобрести. Вы получите уведомление о выполнении развертывания. Процесс создания кластера занимает около 20 минут.
Если при создании кластера HDInsight возникают проблемы, возможно, у вас нет необходимых разрешений. Дополнительные сведения см. в разделе Требования к контролю доступа.
Просмотр развернутых ресурсов
После создания кластера вы получите уведомление Развертывание прошло успешно со ссылкой Перейти к ресурсу. На странице группы ресурсов будет указан новый кластер HDInsight и хранилище по умолчанию, связанное с кластером. Каждый кластер имеет служба хранилища Azure или Azure Data Lake Storage Gen2 зависимость. Она называется учетной записью хранения по умолчанию. Кластер HDInsight должен находиться в том же регионе Azure, что и его учетная запись хранения, используемая по умолчанию. Удаление кластеров не приведет к удалению зависимости учетной записи хранения. Она называется учетной записью хранения по умолчанию. Кластер HDInsight должен находиться в том же регионе Azure, что и его учетная запись хранения, используемая по умолчанию. Удаление кластеров не приведет к удалению учетной записи хранения.
Создание файла Jupyter Notebook
Jupyter Notebook — это интерактивная среда записных книжек, которая поддерживает различные языки программирования. Вы можете использовать Jupyter Notebook, чтобы работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
Откройте портал Azure.
Выберите Кластеры HDInsight, а затем выберите созданный кластер.
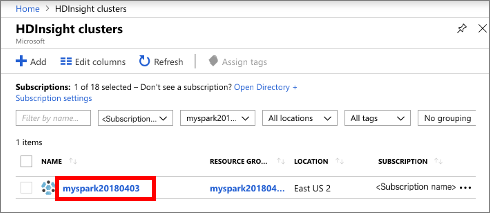
На портале в разделе Панели мониторинга кластера выберите Jupyter Notebook. При появлении запроса введите учетные данные для входа в кластер.
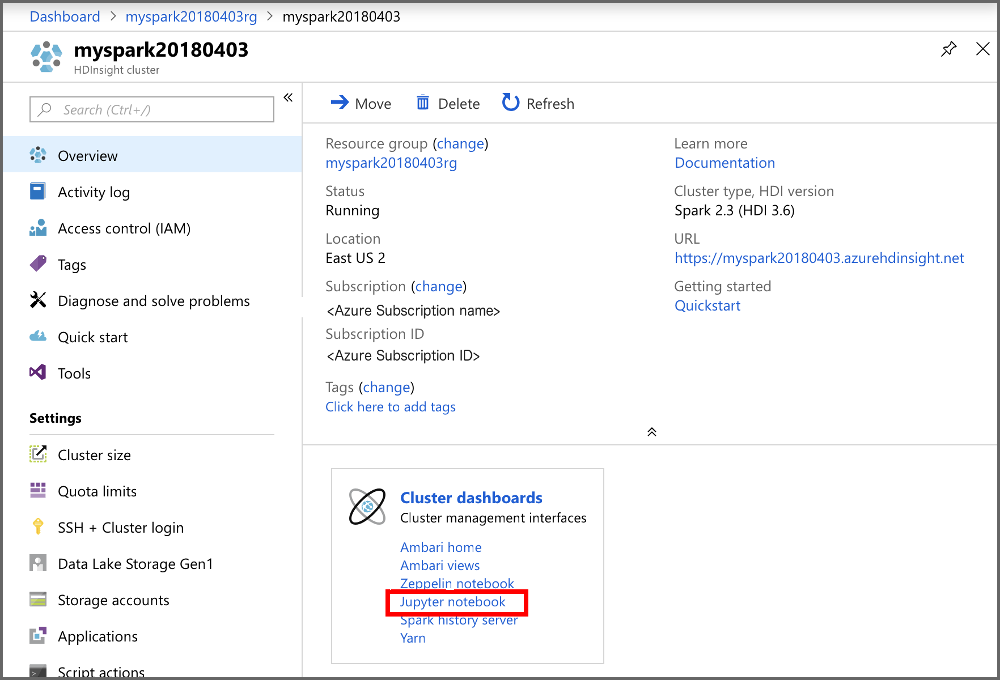
Щелкните Создать>PySpark, чтобы создать элемент Notebook.
Будет создана и открыта записная книжка с именем Untitled (Untitled.pynb).
Выполнение инструкций SQL в Apache Spark
SQL (Structured Query Language) — наиболее распространенный и широко используемый язык для создания запросов и преобразования данных. Spark SQL работает как расширение Apache Spark для обработки структурированных данных с использованием знакомого синтаксиса SQL.
Убедитесь, что ядро готово. Ядро будет готово, когда в записной книжке появится пустой круг рядом с именем ядра. Заполненный круг означает, что ядро занято.
 alt-text="Состояние ядра". Border="true":::
alt-text="Состояние ядра". Border="true":::При первом запуске записной книжки некоторые задачи ядро выполняет в фоновом режиме. Дождитесь готовности ядра.
Вставьте указанный ниже код в пустую ячейку и нажмите сочетание клавиш SHIFT + ВВОД, чтобы выполнить код. Эта команда выводит список таблиц Hive в кластере:
%%sql SHOW TABLESПри использовании файла Jupyter Notebook с кластером HDInsight вы получаете предварительно настроенный сеанс
spark, в котором можно выполнять запросы Hive с помощью Spark SQL. По%%sqlJupyter Notebook понимает, что для выполнения запроса Hive нужно использовать сеансspark. Запрос извлекает первые 10 строк из таблицы Hive (hivesampletable), которая по умолчанию входит в состав всех кластеров HDInsight. Когда вы отправите первый запрос, Jupyter создаст для записной книжки приложение Spark. Это займет около 30 секунд. После создания приложения Spark запрос выполняется в течение секунды и возвращает результаты. Выходные данные выглядят следующим образом.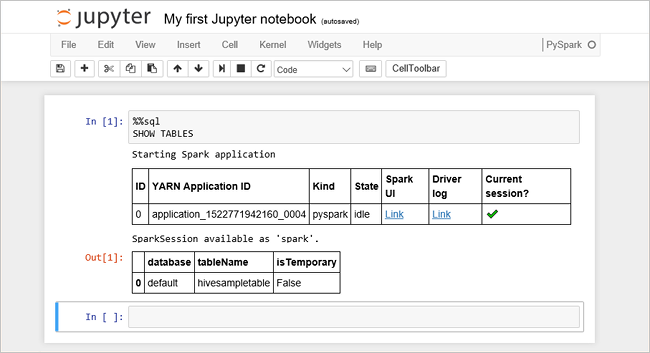 y в HDInsight " border="true":::
y в HDInsight " border="true":::При каждом выполнении запроса в Jupyter в заголовке окна веб-браузера будет отображаться состояние (Занято), а также название записной книжки. Кроме того, рядом с надписью PySpark в верхнем правом углу окна будет показан закрашенный кружок.
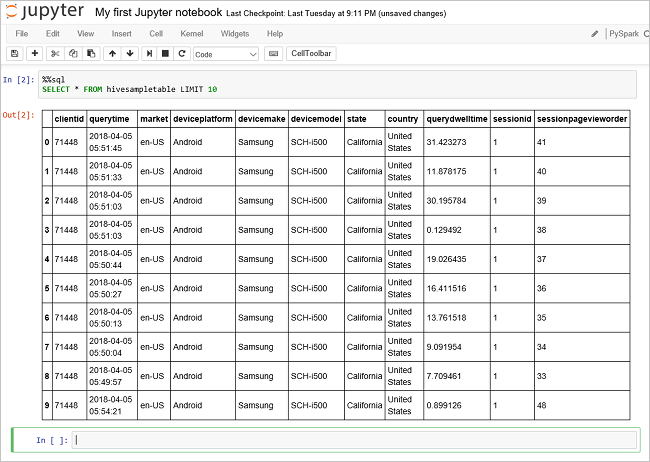
Выполните другой запрос, чтобы вывести данные из таблицы
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Экран обновится, и отобразятся выходные данные запроса.
 Insights" border="true":::
Insights" border="true":::Для этого в меню File (Файл) элемента Notebook выберите Close and Halt (Закрыть и остановить). При завершении работы записной книжки ресурсы кластера освобождаются (включая приложение Spark).
Очистка ресурсов
После завершения работы с этим кратким руководством кластер можно удалить. В случае с HDInsight ваши данные хранятся в службе хранилища Azure, что позволяет безопасно удалить неиспользуемый кластер. Плата за кластеры HDInsight взимается, даже когда они не используются. Так как затраты на кластер во много раз превышают затраты на хранилище, экономически целесообразно удалять неиспользуемые кластеры.
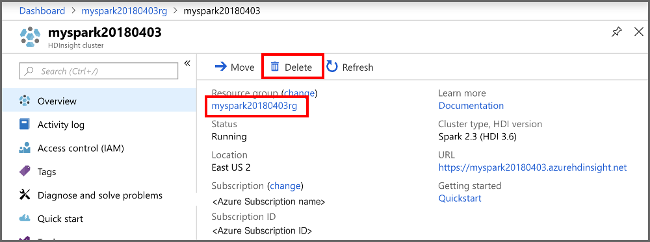
На портале Azure перейдите в свой кластер и выберите Удалить.
 sight cluster" border="true":::
sight cluster" border="true":::
Кроме того, можно выбрать имя группы ресурсов, чтобы открыть страницу группы ресурсов, а затем щелкнуть Удалить группу ресурсов. Вместе с группой ресурсов вы также удалите кластер HDInsight и учетную запись хранения по умолчанию.
Следующие шаги
Из этого краткого руководства вы узнали, как создать кластер Apache Spark в HDInsight и выполнить простой SQL-запрос Spark. Из следующего руководства вы узнаете, как с помощью кластера HDInsight выполнять интерактивные запросы, используя для этого пример данных.