Компонент выполнения скрипта R
В этой статье описывается, как использовать компонент выполнения скрипта R для выполнения кода R в конвейере конструктора Машинного обучения Azure.
С помощью R можно выполнять задачи, которые не поддерживаются существующими компонентами, например:
- Создание пользовательских преобразований данных
- Использование собственных метрик для оценки прогнозов
- Создание моделей с использованием алгоритмов, которые не реализованы как автономные компоненты в конструкторе
Поддержка версии R
Конструктор Машинного обучения Azure использует распределение R по CRAN (всеобъемлющая сеть с архивом R). Текущая используемая версия — CRAN 3.5.1.
Поддерживаемые пакеты R
Среда R предустанавливается с более чем 100 пакетов. Полный список см. в разделе Предварительно установленные пакеты R.
Можно также добавить следующий код в любой компонент выполнения скрипта R, чтобы просмотреть установленные пакеты.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Примечание.
Если конвейер содержит несколько компонентов выполнения скрипта R, для которых требуются пакеты, отсутствующие в списке предварительно установленных, установите пакеты в каждый компонент.
Установка пакетов R
Чтобы установить дополнительные пакеты R, используйте метод install.packages(). Пакеты устанавливаются для каждого компонента выполнения скрипта R. Они не являются совместно используемыми для других компонентов выполнения скрипта R.
Примечание.
НЕ рекомендуется устанавливать пакет R из пакета скриптов. Рекомендуется устанавливать пакеты непосредственно в редакторе скриптов.
При установке пакетов укажите репозиторий CRAN, например install.packages("zoo",repos = "https://cloud.r-project.org").
Предупреждение
Компонент выполнения скрипта R не поддерживает установку пакетов, для которых требуется компиляция в машинный код, например пакет qdap, требующий JAVA и пакет drc, для которого требуется C++. Это происходит потому, что этот компонент выполняется в предварительно установленной среде с разрешениями, не являющимися администраторскими.
Не устанавливайте пакеты, предварительно созданные на, или для платформы Windows, так как компоненты конструктора выполняются на Ubuntu. Чтобы проверить, является ли пакет предварительно созданным в Windows, можно зайти на CRAN и выполнить поиск по пакету, загрузить один двоичный файл в соответствии с текущей операционной системой, а затем проверить раздел Сборка: в файле DESCRIPTION. Ниже приведен пример. 
В этом примере показано, как установить Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Примечание.
Перед установкой пакета проверьте, не установлен ли он уже, чтобы не повторять установку второй раз. Повторные установки могут привести к истечению времени ожидания в запросах веб-службы.
Доступ к зарегистрированному набору данных
Чтобы получить доступ к зарегистрированным наборам данных в рабочей области, можно обратиться к следующему примеру кода:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Настройка выполнения скрипта R
Компонент выполнения скрипта R содержит пример кода, служащего отправной точкой.
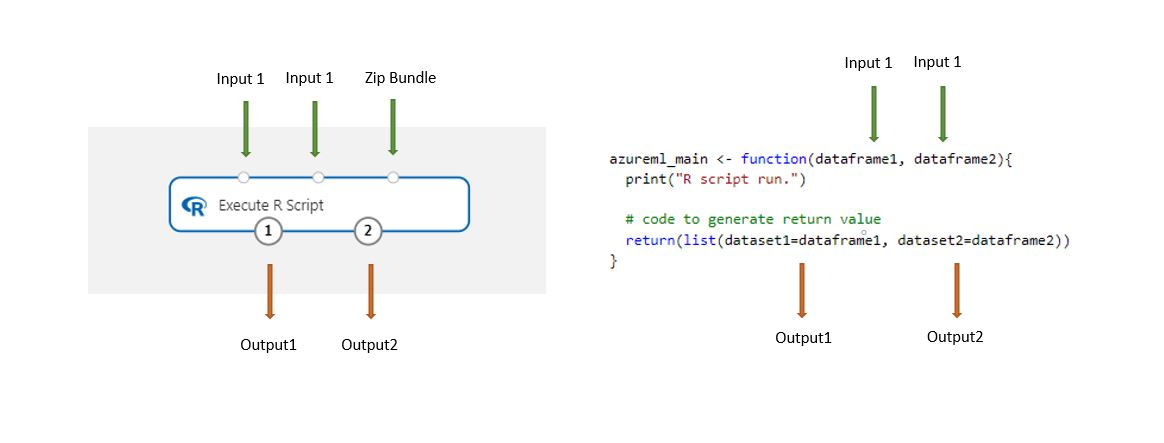
Наборы данных, хранящиеся в конструкторе, автоматически преобразуются в кадр с данными R при загрузке с этим компонентом.
Добавьте компонент выполнения скрипта R в конвейер.
Подключите все входные данные, требующиеся скрипту. Входные данные необязательны и могут включать в себя данные и дополнительный код R.
Dataset1. Ссылка на первые входные данные в виде
dataframe1. Входной набор данных должен быть в формате файла CSV, TSV или ARFF. Или можно подключить набор данных Машинного обучения Azure.DataSet2. Ссылка на вторые входные данные в виде
dataframe2. Этот набор данных также должен быть в формате файла CSV, TSV или ARFF или в виде набора данных Машинного обучения Azure.Пакет скриптов. Третьи входные данные принимаются в виде ZIP-файлов. Упакованный архив в ZIP-файл может содержать несколько файлов и несколько типов файлов.
В текстовом поле Скрипт R введите или вставьте допустимый скрипт R.
Примечание.
Будьте внимательны при написании скрипта. Убедитесь в отсутствии синтаксических ошибок, таких как использование необъявленных переменных или неимпортированных компонентов или функций. Обратите особое внимание на список предварительно установленных пакетов в конце этой статьи. Чтобы использовать пакеты, которых нет в списке, установите их в скрипт. Например,
install.packages("zoo",repos = "https://cloud.r-project.org").Чтобы помочь приступить к работе, в текстовом поле Скрипт R заранее приводится образец кода, который можно править или заменять.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Функция точки входа должна иметь входные аргументы
Param<dataframe1>иParam<dataframe2>, даже если эти аргументы не используются в функции.Примечание.
Данные, передаваемые в компонент выполнения скрипта R, обозначаются как
dataframe1иdataframe2, что отличается от конструктора Машинного обучения Azure (в конструкторе они обозначаются какdataset1,dataset2). Убедитесь, что в скрипте указаны правильные ссылки на входные данные.Примечание.
В имеющемся коде R могут потребоваться незначительные изменения для выполнения его в конвейере конструктора. Например, входные данные, которые предоставляются в формате CSV, должны быть явно преобразованы в набор данных, прежде чем его можно будет использовать в коде. Типы данных и столбцов, используемые в языке R, также отличаются, в некотором смысле, от типа данных и столбцов, используемых в конструкторе.
Если размер скрипта превышает 16 КБ, используйте порт Пакета скриптов, чтобы избежать ошибок, таких как, Командная строка, превышает ограничение в 16 597 символов.
- Упакуйте скрипт и другие дополнительные ресурсы в ZIP-файл.
- Отправьте ZIP-файл в качестве Файла набора данных в студию.
- Перетащите компонент набора данных из списка Наборы данных в левой панели компонента на странице конструктора разработки.
- Подключите компонент набора данных к порту Пакет скрипта компонента выполнения скрипта R.
Ниже приведен пример кода для использования скрипта в пакете скрипта:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Для параметра Случайное начальное значение введите значение, которое будет использоваться в среде R в качестве случайного начального значения. Этот параметр эквивалентен вызову
set.seed(value)в коде R.Отправьте конвейер.
Результаты
Компоненты выполнения скрипта R могут возвращать несколько выходных значений, но они должны быть представлены в виде кадров данных R. Конструктор автоматически преобразует кадры данных в наборы данных для обеспечения совместимости с другими компонентами.
Стандартные сообщения и ошибки из R возвращаются в журнал компонента.
Если необходимо распечатать результаты в скрипте R, результаты печати можно найти в 70_driver_log на вкладке выходные данные и журналы в правой панели компонента.
Примеры сценариев
Существует множество способов расширения конвейера с помощью пользовательских скриптов R. В этом разделе представлен образец кода для распространенных задач.
Добавление скрипта R в качестве входных данных
Компонент выполнения скрипта R поддерживает произвольные файлы скриптов R в качестве входных данных. Чтобы использовать их, необходимо передать их в рабочую область как часть ZIP-файла.
Чтобы отправить ZIP-файл, содержащий код R, в рабочую область, перейдите на страницу ресурсов Наборы данных. Выберите Создать набор данных, а затем выберите Из локального файла и параметр типа набора данных Файл.
Убедитесь, что архивированный ZIP-файл отображается в разделе Мои наборы данных в категории Наборы данных в левом дереве компонента.
Подключите набор данных к порту ввода Пакета скриптов.
Все файлы в ZIP-файле доступны во время конвейерного выполнения.
Если файл пакета скрипта содержит структуру каталогов, структура сохраняется. Но необходимо изменить код так, чтобы в нем к началу пути был добавлен каталог ./Script Bundle.
Обработка данных
В следующем примере показано, как масштабировать и нормализовать входные данные.
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Чтение ZIP-файла в качестве входных данных
В этом примере показано, как использовать набор данных в ZIP-файле в качестве входных данных для компонента выполнения скрипта R.
- Создайте файл данных в формате CSV и назовите его mydatafile.csv.
- Создайте ZIP-файл и добавьте CSV-файл в архив.
- Отправьте архивированный ZIP-файл в рабочую область Машинного обучения Azure.
- Подключите результирующий набор данных ко входу ScriptBundle компонента выполнения скрипта R.
- Используйте следующий код для чтения CSV-данных из архивированного ZIP-файла.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Репликация записей
В этом примере показано, как реплицировать положительные записи в наборе данных для балансировки примера:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Передача объектов R между компонентами выполнения скрипта R
Вы можете передавать объекты R между экземплярами компонента выполнения скрипта R с помощью внутреннего механизма сериализации. В этом примере предполагается, что необходимо переместить объект R с именем A между двумя компонентами выполнения скрипта R.
Добавьте первый компонент выполнения скрипта R в конвейер. Затем введите следующий код в текстовом поле Скрипт R, чтобы создать сериализованный объект
Aв виде столбца в таблице выходных данных компонента:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Явное преобразование в целочисленный тип выполняется потому, что функция сериализации выводит данные в формате R
Raw, который конструктор не поддерживает.Добавьте второй экземпляр компонента выполнения скрипта R и подключите его к порту вывода предыдущего компонента.
Введите следующий код в текстовом поле Скрипт R , чтобы извлечь объект
Aиз таблицы входных данных.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Предварительно установленные пакеты R
В настоящее время доступны следующие предварительно установленные пакеты R:
| Пакет | Версия |
|---|---|
| askpass | 1,1 |
| assertthat | 0.2.1 |
| внутренние порты | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0–6 |
| загрузка | 1.3-22 |
| метла | 0.5.2 |
| вызывающий объект | 3.2.0 |
| крышка | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| компилятор | 3.5.1 |
| карандаш | 1.3.4 |
| curl | 3,3 |
| data.table | 1.12.2 |
| наборы данных | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0,14 |
| вентиляторы | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| иностранный | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| Универсальные шаблоны | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| клей | 1.3.1 |
| Говер | 0.2.1 |
| gplots | 3.0.1.1 |
| графика | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| высокий | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| Итераторы | 1.0.10 |
| jsonlite | 1,6 |
| KernSmooth | 2.23-15 |
| трикотажный | 1.23 |
| маркирование | 0,3 |
| решётка | 0.20-38 |
| Lava | 1.6.5 |
| lazoval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| Markdown | 1 |
| МАССАЧУСЕТС | 7.3-51.4 |
| «Матрица» | 1.2-17 |
| оплаты | 3.5.1 |
| mgcv | 1.8-28 |
| мим | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| столб | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| Ход выполнения | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| квантмод | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| Рецепты | 0.1.5 |
| реванш | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| сетчатый | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1,13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| весы | 1.0.0 |
| селектор | 0.4-1 |
| пространственный | 7.3-11 |
| Сплайны | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| статистика4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| выживание | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| TimeDate | 3043.102 |
| tinytex | 0,13 |
| средства | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| служебные программы | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| усы | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| зоопарк | 1.8-6 |
Следующие шаги
Ознакомьтесь с набором доступных компонентов для машинного обучения Azure.