Предварительная обработка текста
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
Компонент предварительной обработки текста используется для очистки и упрощения текста. Он поддерживает следующие основные операции обработки текста:
- Удаление стоп-слов
- Использование регулярных выражений для поиска и замены конкретных целевых строк
- Лемматизация, то есть преобразование нескольких связанных слов в одну каноническую форму
- Нормализация регистра
- Удаление определенных классов символов, таких как числа, специальные символы и последовательности повторяющихся символов, например "аааа"
- Обнаружение и удаление сообщений электронной почты и URL-адресов
Компонент предварительной обработки текста в настоящее время поддерживает только английский язык.
Настройка предварительной обработки текста
Добавьте компонент предварительной обработки текста в конвейер машинного обучения Azure. Этот компонент можно найти в разделе Анализ текста.
Подключите набор данных, содержащий хотя бы один столбец с текстом.
В раскрывающемся списке Язык выберите язык.
Столбец текста для очистки. Выберите столбец для предварительной обработки.
Удалить стоп-слова. Выберите этот параметр, если требуется применить заранее составленный список стоп-слов к текстовому столбцу.
Списки стоп-слов настраиваются и зависят от языка.
Лемматизация. Выберите этот параметр, если необходимо представить слова в канонической форме. Этот параметр позволяет уменьшить количество уникальных вхождений аналогичных текстовых маркеров.
Процесс лемматизации в большой степени зависит от языка.
Найти предложения. Выберите этот параметр, если необходимо, чтобы компонент разграничивал предложения при выполнении анализа.
Этот компонент использует последовательность из трех символов вертикальной черты
|||, обозначающих конец предложения.Выполнение необязательных операций поиска и замены с помощью регулярных выражений Регулярное выражение обрабатывается первым, и только после этого применяются все остальные встроенные параметры.
- Пользовательское регулярное выражение. Определите искомый текст.
- Пользовательская строка замены. Определите одно заменяющее значение.
Нормализация регистра до нижнего. Выберите этот параметр, если требуется преобразовать символы верхнего регистра ASCII в формы нижнего регистра.
Если символы не нормализованы, то одно и то же слово, написанное прописными и строчными буквами, считается двумя разными словами.
Можно также удалить из обработанного выходного текста следующие типы символов или последовательностей символов:
Удалить числа. Выберите этот параметр, чтобы удалить все числовые символы для указанного языка. Идентификационные номера зависят от области применения и языка. Если числовые символы являются составной частью известного слова, такие числа могут сохраняться. Дополнительные сведения см. в Технических примечаниях.
Удалить специальные символы. Используйте этот параметр для удаления любых специальных символов, отличных от буквенно-цифровых.
Удалить повторяющиеся символы. Выберите этот параметр, чтобы удалить лишние символы в любой последовательности, которые повторяются более двух раз. Например, такая последовательность, как "аааа", будет сокращена до "аа".
Удалить адреса электронной почты. Выберите этот параметр, чтобы удалить любую последовательность формата
<string>@<string>.Удалить URL-адреса. Выберите этот параметр, чтобы удалить все последовательности, включающие следующие префиксы URL-адресов:
http,https,ftp,www
Развернуть сокращенные глагольные формы. Этот параметр применяется только к языкам, в которых используются сокращенные глагольные формы (в настоящее время только для английского языка).
Например, если выбран этот параметр, можно заменить фразу wouldn't stay there на "would not stay there".
Нормализовать обратные косые черты до косых черт. Выберите этот параметр, чтобы сопоставить все экземпляры
\\с/.Разбить маркеры на специальные символы. Выберите этот параметр, если нужно разбить слова на такие символы
&,-и т. д. Этот параметр также позволяет сократить количество специальных символов, если они повторяются более двух раз.Например, строка
MS---WORDбудет разделена на три маркера:MS,-иWORD.Отправьте конвейер.
Технические примечания
Компонент предварительной обработки текста в Studio (классическая версия) и в конструкторе использует разные языковые модели. В конструкторе используется многозадачная обученная модель CNN из spaCy. Различные модели предоставляют разные средства определения маркеров и тегов частей речи, что приводит к различным результатам.
Ниже приводятся некоторые примеры.
| Настройка | Итоговый результат |
|---|---|
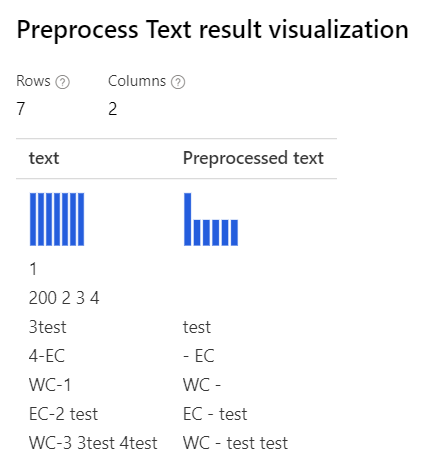
| Со всеми выбранными параметрами Объяснение: В таких случаях, как "3Test" в "WC-3 3Test 4test", конструктор удаляет слово "3Test" целиком, поскольку в этом контексте средство определения тегов частей речи распознает этот маркер "3Test" как числительное, и в соответствии с частью речи компонент удаляет его. |

|
Только с выбранным параметром Removing number Объяснение: В таких случаях, как "3Test" и "4-EC", создатель маркеров в конструкторе не разделяет эти варианты и обрабатывает их как целые маркеры. Следовательно, числа из этих слов не удаляются. |

|
Можно также использовать регулярное выражение для вывода настраиваемых результатов:
| Настройка | Итоговый результат |
|---|---|
| При выборе всех параметров настраиваемого регулярного выражения: настраиваемая строка замены: (\s+)*(-|\d+)(\s+)* \1 \2 \3 |

|
Removing number Только при выборе настраиваемого регулярного выражения: настраиваемая строка замены: (\s+)*(-|\d+)(\s+)* \1 \2 \3 |
|
Следующие шаги
Ознакомьтесь с набором доступных компонентов для машинного обучения Azure.