Создание векторного индекса в потоке запроса Машинное обучение Azure (предварительная версия)
Вы можете использовать Машинное обучение Azure для создания векторного индекса из файлов или папок на компьютере, расположения в облачном хранилище, Машинное обучение Azure ресурса данных, репозитория Git или базы данных SQL. Машинное обучение Azure в настоящее время могут обрабатывать файлы .txt, MD, .pdf, .xls и .docx. Вы также можете повторно использовать существующий индекс поиска ИИ Azure (прежнее название — Когнитивный поиск) вместо создания нового индекса.
При создании векторного индекса Машинное обучение Azure блокирует данные, создает встраивания и сохраняет внедрения в индекс Faiss или индекс поиска ИИ Azure. Кроме того, Машинное обучение Azure создает:
Проверьте данные для источника данных.
Пример потока запроса, использующего созданный индекс вектора. Ниже приведены функции примера потока запроса:
- Автоматически созданные варианты запроса.
- Оценка каждого варианта запроса с помощью созданных тестовых данных.
- Метрики для каждого варианта запроса, помогающие выбрать оптимальный вариант для выполнения.
Этот пример можно использовать для продолжения разработки запроса.
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Необходимые компоненты
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись.
Доступ к службе Azure OpenAI.
Потоки запросов, включенные в Машинное обучение Azure рабочей области. Потоки запросов можно включить, включив решения ИИ сборки с помощью потока запроса на панели функций "Управление предварительными версиями".
Создание векторного индекса с помощью студии Машинное обучение
Выберите поток запроса в меню слева.
Перейдите на вкладку "Векторный индекс ".
Нажмите кнопку создания.
Когда откроется форма создания векторного индекса, укажите имя векторного индекса.

Выберите тип источника данных.
В зависимости от выбранного типа укажите сведения о расположении источника. Затем выберите Далее.
Просмотрите сведения о индексе вектора и нажмите кнопку "Создать ".
На появившемся странице обзора можно отслеживать и просматривать состояние создания векторного индекса. Процесс может занять некоторое время в зависимости от размера данных.
Добавление векторного индекса в поток запроса
После создания векторного индекса его можно добавить в поток запроса из холста потока запроса.
Откройте существующий поток запроса.
В верхнем меню конструктора потоков запроса выберите "Дополнительные инструменты" и выберите " Поиск индекса".

Средство подстановки индекса добавляется на холст. Если средство не отображается немедленно, прокрутите страницу внизу холста.
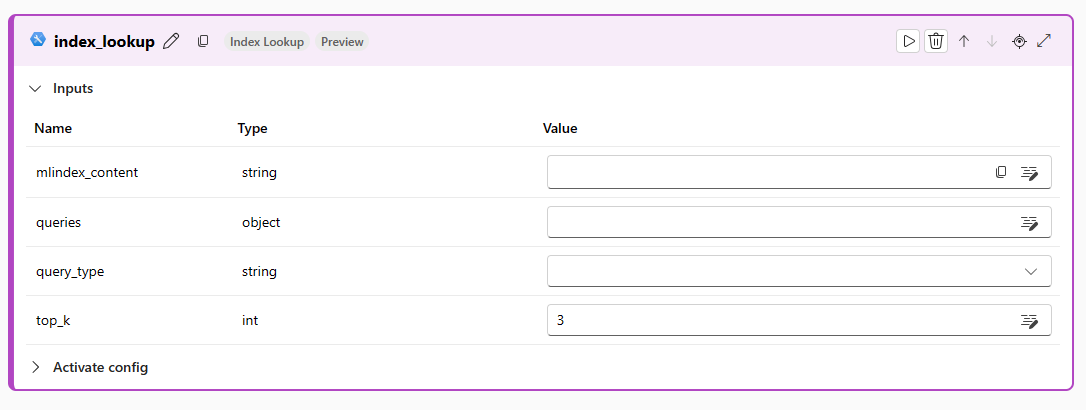
Выберите поле mlindex_content значения и выберите индекс. Средство должно обнаружить индекс, созданный в разделе "Создание векторного индекса" руководства. После заполнения всех необходимых сведений нажмите кнопку "Сохранить", чтобы закрыть ящик создания.
Введите запросы и query_types, которые необходимо выполнить в индексе.
Пример простой строки, которую можно ввести в этом случае, будет:
How to use SDK V2?'. Here is an example of an embedding as an input:${embed_the_question.output}". Передача простой строки будет работать только в том случае, если индекс вектора будет использоваться в рабочей области, которая ее создала.
Поддерживаемые типы файлов
Поддерживаемые типы файлов для создания задания векторного индекса: .txt, .md, .html, .htm, .py, .pdf, .ppt, .pptx, .doc, .docx, .xls, .xlsx. Любые другие типы файлов будут игнорироваться во время создания.
Следующие шаги
Начало работы с RAG с помощью примера потока запроса (предварительная версия)
Использование векторных хранилищ с Машинное обучение Azure (предварительная версия)